







系列文章:
Python PDF神器PyMuPDF使用指南 (一)——安装和基础功能
Python PDF神器PyMuPDF使用指南 (二)——文件和文本功能
Python PDF神器PyMuPDF使用指南 (三)——图像和注释功能
Python PDF神器PyMuPDF使用指南 (四)——绘图、多线程和OCR功能
Python PDF神器PyMuPDF使用指南 (五)——命令行使用
Python PDF神器PyMuPDF使用指南 (六)——Document类详解
Python PDF神器PyMuPDF使用指南 (七)——Page类详解
Python PDF神器PyMuPDF使用指南 (八)——基础使用指南
正文:
PyMuPDF是一个高性能的Python库,用于PDF(和其他)文档的数据提取、分析、转换和操作。
Github地址为:pymupdf代码库
官方文档地址为:PyMuPDF文档
前文介绍了PyMuPDF基本的安装和基础的功能,本文将详细介绍PyMuPDF处理PDF(和其他)文档的打开文件和文本处理功能。
打开文件
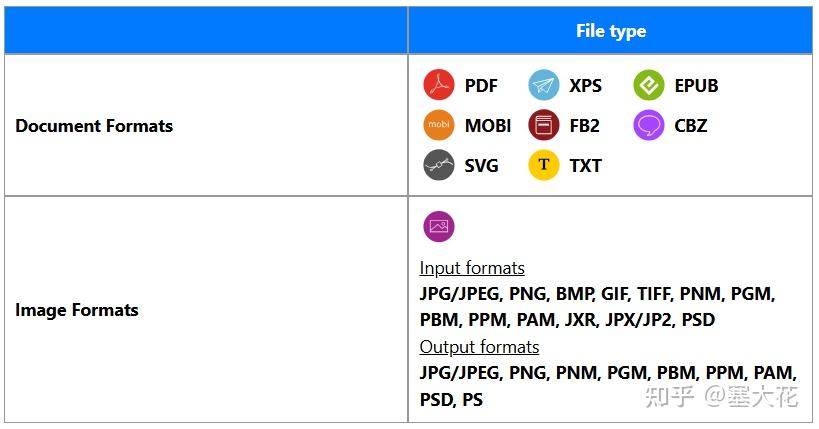
支持的文件类型
PyMuPDF可以打开的文件不止有PDF,还有其他文件类型,下面是目前支持的全部文件类型:
打开文件的方式详解
基本打开方式
打开文件的方式为:
doc = pymupdf.open("a.pdf")注意:这个方式创建了一个 Document对象,还有另外一种方式:doc=pymupdf.Document("a.pdf")。因此,open只是一个方便的别名,可以在Document对象介绍中找到其完整的API。后面会仔细介绍。
打开文件扩展名错误的文件
如果你有一个文件扩展名错误的文档,你仍然可以正确地打开它。
假设“some.file”实际上是一个XPS文件,你可以像这样打开它:
doc = pymupdf.open("some.file", filetype="xps")注意
PyMuPDF不会自动根据文件内容判断文件类型。你需要以某种方式提供文件类型信息——可以通过文件扩展名隐式提供,或者像上面一样通过filetype参数显式提供。有一些纯Python库,例如filetype,可以帮助你实现这一点。有关详细信息,后面会在Document对象介绍章节中详细解释。
如果PyMuPDF遇到一个没有扩展名或扩展名未知的文件,它会尝试将其作为PDF打开。因此,在这种情况下无需额外的预防措施。对于内存中的文档,可以直接指定doc=pymupdf.open(stream=mem_area)来将其作为PDF文档打开。
如果尝试打开一个不支持的文件类型,PyMuPDF将抛出文件数据错误。
打开远程文件
对于服务器上的远程文件(即非本地文件),你需要将文件数据流传输到PyMuPDF。
例如,可以使用requests库如下操作:
import pymupdf
import requests
r = requests.get('https://mupdf.com/docs/mupdf_explored.pdf')
data = r.content
doc = pymupdf.Document(stream=data)从云服务打开文件
关于如何处理存储在常见云服务上的文件的更多示例,请参阅这些与云交互相关的代码片段。
以文本格式打开文件
PyMuPDF支持将任何纯文本文件作为文档打开。为此,你应为pymupdf.open函数提供filetype="txt"参数。
doc = pymupdf.open("my_program.py", filetype="txt")通过这种方式,你可以打开各种文件类型,并执行典型的非PDF特定操作,例如文本搜索、文本提取和页面渲染。显然,一旦你渲染了txt内容,将其保存为PDF或与其他PDF文件合并是没有问题的。
示例
打开C#文件:
doc = pymupdf.open("MyClass.cs", filetype="txt")打开XML文件:
doc = pymupdf.open("my_data.xml", filetype="txt")打开JSON文件:
doc = pymupdf.open("more_of_my_data.json", filetype="txt")等等!如你所见,许多基于文本的文件格式可以非常简单地通过PyMuPDF打开并解析。这使得对广泛的先前不可用的文件进行数据分析和提取成为可能。
文本处理
如何提取文档中的所有文本
这个脚本将接受一个文档文件名,并生成一个包含文档所有文本的文本文件。
该文档可以是任何支持的类型。
此脚本作为命令行工具运行,期望将文档文件名作为参数提供。它会在脚本目录中生成一个名为“filename.txt”的文本文件。页面文本之间通过换页符(form feed)字符分隔:
import sys, pathlib, pymupdf
fname = sys.argv[1] # 获取文档文件名
with pymupdf.open(fname) as doc: # 打开文档
text = chr(12).join([page.get_text() for page in doc])
# 以二进制文件格式写入以支持非ASCII字符
pathlib.Path(fname + ".txt").write_bytes(text.encode())输出将是文档编码格式的纯文本。不会进行任何格式化,特别是对于PDF文件,这可能意味着输出顺序不符合常规阅读顺序,出现意外的换行等。
有很多方法可以修正这一点——参见附录2:关于嵌入文件的注意事项</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











