






我们公司的小姐姐很多都是肖战的铁粉,我就想看看肖战有哪些吸引小姐姐的地方,看看里面是不是有摆脱我单身的痛。
话不多说我们先看看肖战的微博
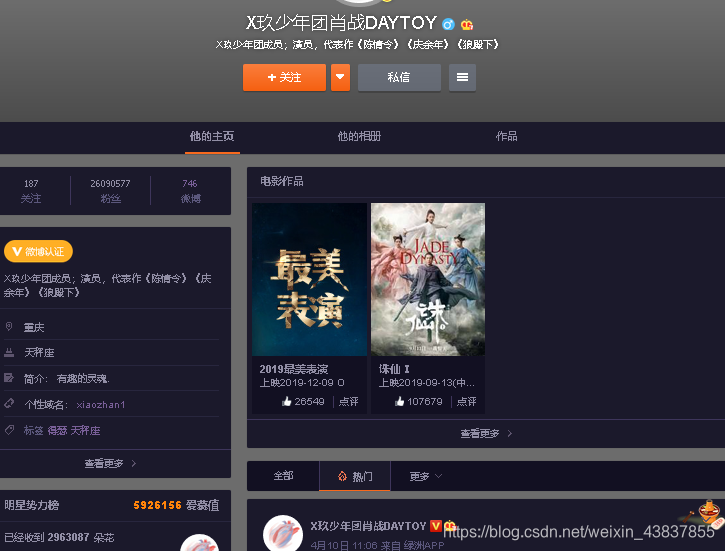
我们以第一篇微博为例子,点击进去,按F12,进入开发者选项,按照下图操作,这是一个js文件,这个文件里面是评论数据。我们要抓取评论数据,首先就要构建这个url。
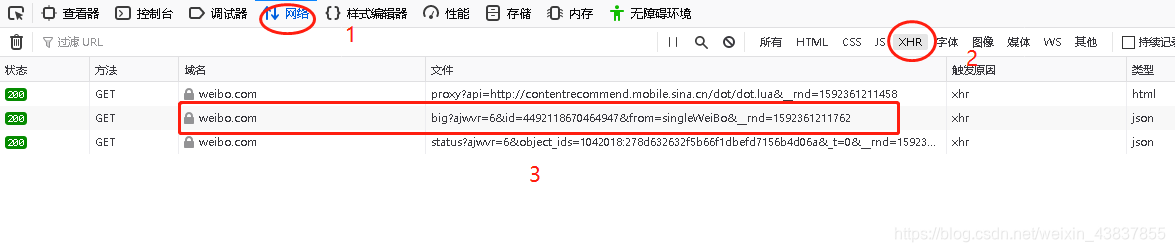
通过分析url我们可以知道,在上一页的评论里面我们可以找到下一级root_comment_max_id,这样我们就可以构建url了。
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4492118670464947&from=singleWeiBo&__rnd=1592459762324

主要的元素如下:
ajwvr:6常量
id:4492118670464947 微博id
root_comment_max_id:父级id
from:singleWeiBo
rnd:当前时间减去1970.01.01,时间差转换为毫秒
代码如下:
headers = { 'Cookie': 填写自己的cookies}
params = {
'ajwvr': 6,
'id': '4492118670464947',
'from': 'singleWeiBo',
'root_comment_max_id': ''
}
URL = 'https://weibo.com/aj/v6/comment/big'
response = requests.get(URL, params=params, headers=headers)
response = json.loads(resp.text)
html = response ['data']['html']
html = etree.HTML(html)
print(etree.tostring(html, encoding=str, pretty_print=True))
max_id_json = html.xpath('//div[@node-type="comment_loading"]/@action-data')[0]
node_params = parse_qs(max_id_json)
# 获取父级ID
max_id = node_params['root_comment_max_id'][0]
params['root_comment_max_id'] = max_id
爬取评论以及用户ID

爬取结果

完整代码
import json
import requests
import time
import random
from lxml import etree
import lxml
import os
from urllib.parse import parse_qs
from bs4 import BeautifulSoup
#cookies
headers = {
'Cookie': '填写cookies'}
#当前路径+pic
pic_file_path = os.path.join(os.path.abspath(''), 'picture')
def ipget():
proxies=[]
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.121 Safari/537.36'}
# 发送网络请求
response = requests.get('https://www.xicidaili.com/nn/', headers=headers)
response.encoding = 'utf-8' # 设置编码方式
if response.status_code == 200: # 判断请求是否成功
html = etree.HTML(response.text) # 解析HTML
table = html.xpath('//table[@id="ip_list"]')[0] # 获取table标签内容
trs = table.xpath('//tr')[1:] # 获取所有tr标签,排除第一条
# 循环遍历标签内容
for t in trs:
clas = t.xpath('td/text()')[5]
if clas == 'HTTPS':
ip = t.xpath('td/text()')[0] # 获取代理ip
port = t.xpath('td/text()')[1] # 获取端口
proxies.append(ip + ':' + port)
return proxies
def write_comment(comment):
comment += '\n'
with open('comment.txt', 'a', encoding='utf-8') as f:
f.write(comment.replace('回复', '').replace('等人', '').replace('图片评论', ''))
def download_pic(url, nick_name):
if not url:
return
if not os.path.exists(pic_file_path):
os.mkdir(pic_file_path)
resp = requests.get(url)
if resp.status_code == 200:
with open(pic_file_path + f'/{nick_name}.jpg', 'wb') as f:
f.write(resp.content)
if __name__ == '__main__':
proxies_use_urls = set()
proxies_nouse_urls = set()
# 代理池
proxies = ipget()
params = {
'ajwvr': 6,
'id': '4492118670464947',
'from': 'singleWeiBo',
'root_comment_max_id': ''
}
URL = 'https://weibo.com/aj/v6/comment/big'
# 爬去100页,需要代理,或者进行sleep 不然会超时。
for num in range(3):
print(f'========= 正在读取第 {num} 页 ====================')
while True:
try:
proxy = proxies.pop()
print(proxy)
if proxy not in proxies_use_urls and proxy not in proxies_nouse_urls :
resp = requests.get(URL, params=params, headers=headers, proxies={"https":proxy})
resp = json.loads(resp.text)
except Exception as e:
proxies_nouse_urls.add(proxy)
continue
break
if resp['code'] == '100000':
print(proxies_nouse_urls)
proxies_use_urls.add(proxy)
html = resp['data']['html']
html = etree.HTML(html)
print(etree.tostring(html, encoding=str, pretty_print=True))
max_id_json = html.xpath('//div[@node-type="comment_loading"]/@action-data')[0]
node_params = parse_qs(max_id_json)
# 获取父级ID
max_id = node_params['root_comment_max_id'][0]
params['root_comment_max_id'] = max_id
data = html.xpath('//div[@node-type="root_comment"]')
for i in data:
# 评论人昵称
nick_name = i.xpath('.//div[@class="WB_text"]/a/text()')[0]
# 评论内容。
wb_text = i.xpath('.//div[@class="WB_text"][1]/text()')
string = ''.join(wb_text).strip().replace('\n', '')
write_comment(string)
# 评论id , 用于获取评论内容
comment_id = i.xpath('./@comment_id')[0]
# 评论的图片地址
pic_url = i.xpath('.//li[@class="WB_pic S_bg2 bigcursor"]/img/@src')
pic_url = 'https:' + pic_url[0] if pic_url else ''
download_pic(pic_url, nick_name)

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









