






数据挖掘与数据分析项目链家租房数据(一)数据爬虫
今日无聊将一个过去做的链家数据分析项目弄上来,当时是某面试,三天时间完成,主要是供大家抄代码和分享一下思考点,这一章是爬虫部分。
网站原图

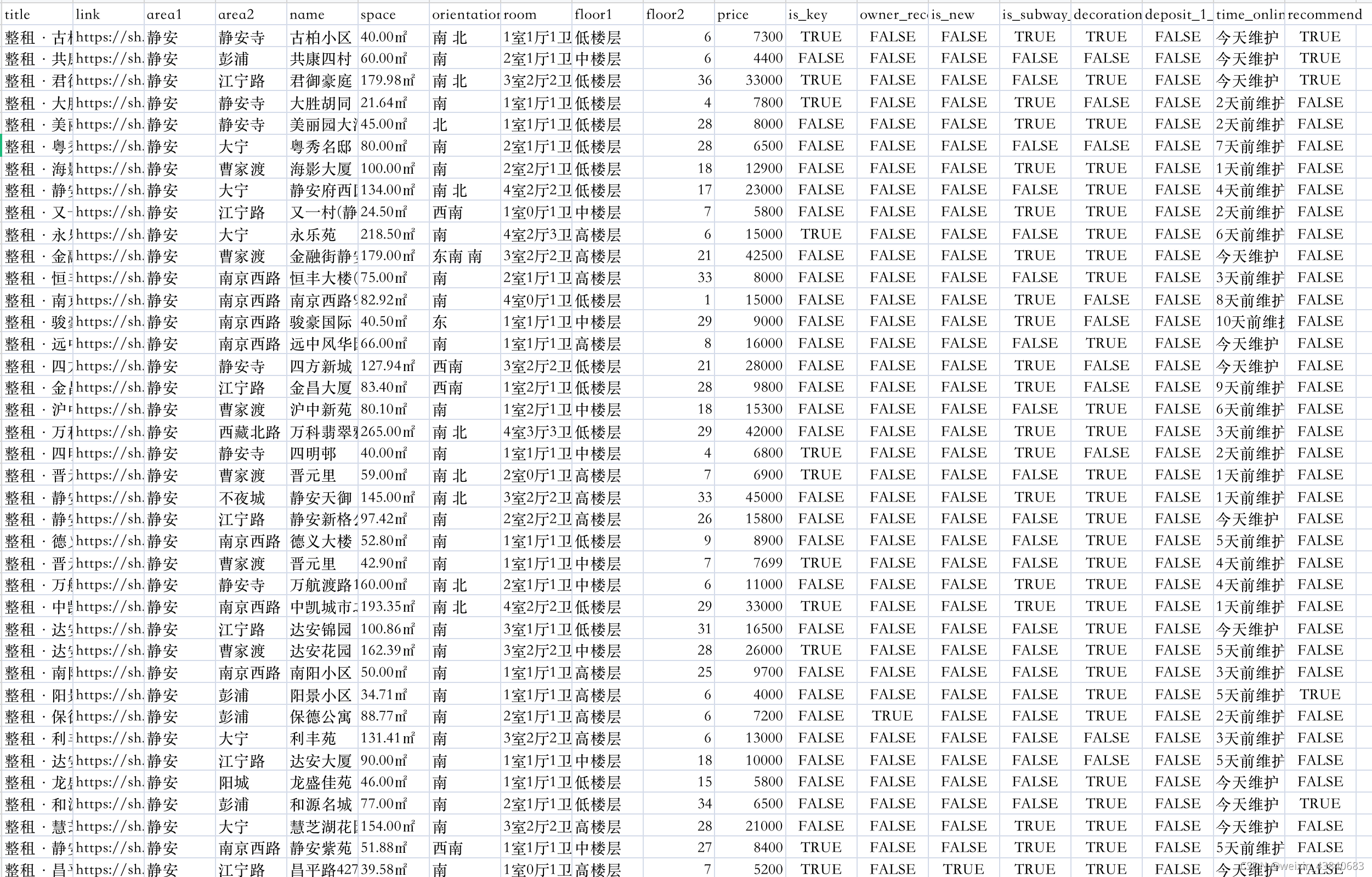
结果截图
先上结果截图,以下几类前几类标签名意思明显,后几列bool变量主要为是否靠近地铁,是否自检,是否精装修等业主提供的主观信息,最后一列表示是否被链家标注为必看好房。
数据量方面,当时爬取上海租房信息,接近一万五千条。
代码
以下则提供代码 代码部分最后有一些奇怪问题,url只对应一百页,所以后来按区分它,每次用要更新一下页数,很烦,但我爬虫懂不多只能这样干。
在这里插入代码片
#!/usr/bin/env python
# coding: utf-8
import requests
from bs4 import BeautifulSoup
import time
import csv
def spider(url):
headers ={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.2 Safari/605.1.15'}
resp = requests.get(url,headers=headers)
html = resp.text
soup = BeautifulSoup(html,'html.parser')
houses = soup.find('div',{'class':'content__list'}) .find_all('div',{'class':'content__list--item--main'})
infos = []
for house in houses:
title = house.find('p',{'class':'content__list--item--title'}).find('a').get_text() .replace('\n', '').strip()
link ='https://sh.lianjia.com'+house.find('p',{'class':'content__list--item--title'}) .find('a',{'class':'twoline'}).get('href')
des = house.find('p',{'class':'content__list--item--des'})
des = des.get_text().split('/')
tmp = des[0].replace('\n', '').strip().split('-')
area1,area2,name = tmp[0],tmp[1],tmp[2]
space = des[1].replace('\n', '').strip()
orientation = des[2].replace('\n', '').strip()
room = des[3].replace('\n', '').strip()
floor = des[4].replace('\n', '').strip().split('(')
floor1 = floor[0].strip()
if '层' in floor[1]:
floor2 = floor[1].split('层')[0]
else:
floor2 = -100
price = house.find('span',{'class':'content__list--item-price'}).find('em').get_text()
lable = house.find('p',{'class':'content__list--item--bottom oneline'})
is_key = lable.find('i',{'class':'content__item__tag--is_key'}) is not None
owner_reco = lable.find('i',{'class':'content__item__tag--owner_reco'}) is not None
is_new = lable.find('i',{'class':'content__item__tag--is_new'}) is not None
is_subway_house = lable.find('i',{'class':'content__item__tag--is_subway_house'}) is not None
decoration = lable.find('i',{'class':'content__item__tag--decoration'}) is not None
deposit_1_pay_1 = lable.find('i',{'class':'content__item__tag--deposit_1_pay_1'}) is not None
time_online = house.find('p',{'class':'content__list--item--brand oneline'}) .find('span',{'class':'content__list--item--time oneline'}).get_text()
recommend = house.find('p',{'class':'content__list--item--title'}).find('img') is not None
info = [title,link,area1,area2,name,space,orientation,room,floor1,floor2,price, is_key,owner_reco,is_new,is_subway_house,decoration,deposit_1_pay_1,time_online,recommend]
infos.append(info)
return infos
if __name__ == '__main__':
infos = []
urls = ['https://sh.lianjia.com/zufang/jingan/','https://sh.lianjia.com/zufang/xuhui/', 'https://sh.lianjia.com/zufang/huangpu/','https://sh.lianjia.com/zufang/changning/', 'https://sh.lianjia.com/zufang/putuo/','https://sh.lianjia.com/zufang/pudong/l1/', 'https://sh.lianjia.com/zufang/pudong/l0l2l3/','https://sh.lianjia.com/zufang/baoshan/', 'https://sh.lianjia.com/zufang/hongkou/','https://sh.lianjia.com/zufang/yangpu/', 'https://sh.lianjia.com/zufang/minhang/','https://sh.lianjia.com/zufang/jinshan/', 'https://sh.lianjia.com/zufang/jiading/','https://sh.lianjia.com/zufang/chongming/', 'https://sh.lianjia.com/zufang/fengxian/','https://sh.lianjia.com/zufang/songjiang/', 'https://sh.lianjia.com/zufang/qingpu/']
pages = [42,51,28,43,42,79,100,24,10,19,42,2,19,2,14,30,25]
for i in range(17):
for page in range(pages[i]):
url = urls[i]+'pg'+str(page+1)
infos += spider(url)
with open("lianjia.csv","w") as f:
writer = csv.writer(f)
writer.writerow(['title','link','area1','area2','name','space', 'orientation','room','floor1','floor2','price', 'is_key','owner_reco','is_new','is_subway_house', 'decoration','deposit_1_pay_1','time_online','recommend'])
writer.writerows(infos)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









