







项目实训 No.2
阅读甲骨文提取文献
1.https://d.wanfangdata.com.cn/conference/8147619
先通过建立甲骨文字形动态描述库(Dynamic Description Library for Jiaguwen Characters,以下简称DDLJC),使用有向笔段和笔元对甲骨文字形进行动态的矢量化描述[12],然后在字形骨架上找出特征点,最后通过特征点进行量化和存储,实现了甲骨文字的字形编码,以后的字形的编辑和输出都是由特征点来动态的生成甲骨文字
2.https://d.wanfangdata.com.cn/thesis/Y1732016
使用Bezier曲线拟合甲骨文轮廓字形的方法,其中包括甲骨文字形轮廓数据的获取、轮廓字形特征点的提取以及使用Bezier曲线拟合字形等主要步骤.实验结果表明,通过使用我们开发的甲骨文字形处理系统,可以把图片形式的甲骨文转化为曲线轮廓描述的甲骨文字形,并形成标准的TrueType格式字库,从而能在通用的字处理软件中方便地使用甲骨文.

3.https://d.wanfangdata.com.cn/thesis/Y1732016
甲骨文原始图片中提取出字体,并拟合生成高精度曲线轮廓甲骨文字形,设计并实现了甲骨文字形自动生成系统。
1.结合K-均值聚类分析和八邻域法,提出了一种基于改进的K-均值聚类图像处理方法。该方法可以更有效地将甲骨文字体目标从原始甲骨文图片中分割出来。在甲骨文文字目标分割出来后,根据图像平滑等处理对甲骨文文字目标进行优化,然后提取出甲骨文原始轮廓线以及特征点信息,为下一步拟合生成曲线轮廓甲骨文字形做准备。
2.提出了一种带自适应形状参数的三次B样条曲线拟合方法,并将其应用于生成曲线轮廓甲骨文字形。该方法根据带局部形状参数三次B样条曲线的性质,首先反求出过特征点的B样条曲线的控制点,然后利用最小二乘法求解与离散点距离总偏差最小的局部形状参数,最后根据控制点和形状参数进行曲线拟合生成曲线轮廓甲骨文字形。该方法使拟合曲线精确的经过特征点,自动获取并调节形状参数,达到了比较好的曲线拟合效果。
3.设计并实现了高精度曲线轮廓甲骨文字形自动生成系统,该系统不仅验证了上述算法的正确性,而且大大提高了生成甲骨文字形的效率,减少了保存甲骨文字体所占的存储空间。、
4.http://www.cnki.com.cn/Article/CJFDTOTAL-KXJS201836014.htm
基于迭代函数系统和分形插值逼近的甲骨字形修复方法。
算法如下。
Step 1 对输入的甲骨字形图像进行去噪处理,得到二值图像 φ(x,y)。
Step 2 提取字形图像的特征点 Pi(xi,yi)。
Step 3 以首末特征点及其垂直平分线建立平面直角坐标系,利用笔划轮廓上特征点的坐标数据计算函数 hφ 和 bφ。
Step 4 利用式(1)解得分形插值函数 f,该函数由 Li(x)及 Fi(x,y)唯一确定。
Step 5 对目标集应用分形插值函数进行逼近,得到新的点集。
Step 6 对新的点集重复 Step 3 ~Step 5,迭代3 ~5 次后输出处理后的图像。
一般情况下,迭代 3 ~5 次,即可对图像边缘进行较好地平滑。
5.https://d.wanfangdata.com.cn/periodical/scgyxyxb201005013
Step1 去噪
通过计算自适应阈值,将噪声区域面积和阈值进行对比,将小于阈值的噪声区域视为噪声,对其进行填充。
Step2 平滑
基于分形几何的甲骨拓片字形图像复原方法。采用统计的方法计算甲骨拓片字形图像边缘的分形维数特征,对甲骨文字形的不同笔划和不同笔段分别进行不同的压缩变换处理,进而对甲骨拓片字形图像边缘进行平滑。
Step3 甲骨文字形的数字化拟合
1.郑芳林等人”采取三次B样条曲线来拟合还原甲骨文字符,开发了一个造字系统。
2.肖明等人[61利用HIGH.LOGIC公司的TrueType曲线轮廓造字软件,按照直线和二次B样条曲线拟合算法,自动将扫描的点阵图形抽成尽可能接近原稿的数字化信息(曲线轮廓),生成一个独立的可运行于Windows、Linux环境下的TTF格式字库。
3.李胜明等人采用3次样条B—spline曲线拟合还原字符轮廓技术对甲骨文字形进行处理。
4.马小虎(Xiaohu MA)等人旧圳开发出了一个针对甲骨文字形特点的字形处理系统。该系统在算法上采取顺序对曲线上的每个点与它左右两边相邻点的夹角求平均值的方法,来增加特征点提取的精确度,以及使用对缓慢弯曲的较长曲线插入一个额外特征点的方法,提高了字形拟合的精度。该系统还可以通过移动控制点、导引点来修改字形的形状,对字形拟合可以进行精确的控制。
Step4 甲骨文字库的建设——内码
甲骨文字形的内码,即甲骨文字形的机内码,在计算机系统内部存储、处理甲骨文字形时所用的代码。甲骨文字形的外码,即甲骨文字形的输入码,是为了通过键盘字符把甲骨文字形输入计算机而设计的一种编码,它按照某种规则将每一个甲骨文字形和一个符号串或一个数字串对应起来,从而把甲骨文字形输入计算机中。
顾绍通等人训利用Unicode做为甲骨文字形的内码,将甲骨文字形放在自定义区域(Private Use Area,E000.F9FF),按照建设通用甲骨文字库的要求,制作了通用甲骨文字库。该字库为1TF格式,与现有的Win.dows系统完全兼容,实用性较强。
Step5 甲骨文字库的建设——输入码
1)按照字形特征进行编码,称为形码,如五笔字型编码。
2)按照汉字的字音特征进行编码,称为音码,例如智能ABC编码方案。
3)将汉字的形、音特征结合起来进行编码,称为形音码。
Step6 甲骨文字形的识别
1)周新伦¨副提出一种两级分类的识别方法:首先,将待识的甲骨文字符抽象为一种图,并提取其拓扑特征进行第一级识别;然后,给出一种广义笔划定义,并在此基础上提取有关的特征进行第二级识别。
2)李锋¨引提出一种基于图论方法识别甲骨文的理论和技术,把甲骨文当作无向图来处理,提取它的图特征,并以此为识别依据。通过对甲骨文进行识别来代替甲骨文输入编码,可以避免输入编码的弊端,但是甲骨文由于本质上还是一种图画文字,结构上难以准确区分笔划,因此甲骨文字形识别的准确率还有待提高。
6.https://d.wanfangdata.com.cn/thesis/D01831813
算法改进过程中基本上是遵循了原始追踪降噪算法的核心思想。在 BPDN 算法的基
础上,为了增加算法的鲁棒性,改变了支持集的更新方式,将基追踪去噪算法中关键的
一个步骤做了变动:关键步骤为:(1)计算更新方向(2)更新稀疏系数(3)计算更新
步长(4)更新支持集和符号序列集。本章改进了更新支持集的方式,提升了算法的识
别准确率。
传统非稀疏表示机器学习方法和深度学习分类算法,在甲骨文数据集上的准确率都
较低,为了进一步提升甲骨文数据集识别的准确率,本文尝试了抗噪能力较强的基于稀
疏表示的算法。由表 4-3 可知,稀疏表示算法准确率差距也极大,但其表现最优的算法
较多。除 RNIK、RNIM、LNIK、LNIM、ADL-KSVD、LRC、WSRC 准确率较低之外,
其余稀疏表示算法准确率均超过 30%。其中多个算法的准确率超过非稀疏表示算法,甚
至多个算法准确率高于 40%。但部分算法在数据集样本量较多的时候运行时间过长。典
型例子为 PALM 算法,运行时间为 793104.22 秒,折合为 9.18 天,显然该算法并不适合
较大的数据集。综合运行时间和准确率,准确率在 35%以上,运行时间在 1000 以内的
算法有 NNLS、BPDN、IBPDN、LNDK、RNDK、RNAK 多种,其中 RNDK、RNAK
算法在准确率和运行时间均表现优异。证明稀疏表示算法是解决甲骨文识别的有效算
法。
7.https://d.wanfangdata.com.cn/thesis/Y2328174
Step1 利用图像分割算法提取骨刻文,再进行二值化处理
Step2 图像进行放缩,旋转,拉伸和扭曲变换
Step3 对原图及变换后图像分别计算前10阶Zemike矩进行对比观察
3.2.1数据的预处理
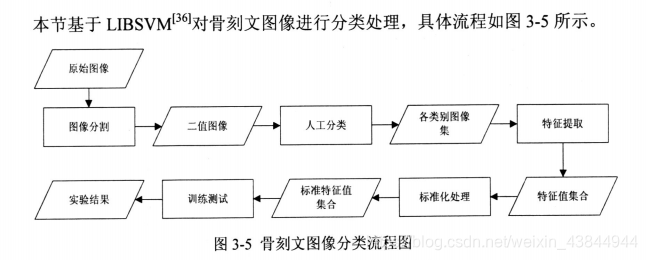
图3-5骨刻文图像分类流程图
1)图像分割:
采用基于图论的交互式图像分割算法对图像进行分割,得到目标图像,为了
后续利用,进一步进行二值化处理,得到二值化图像。
2)人工分类:
根据刘凤君教授编著的龙山骨刻文【3】一书中提供的骨刻文图像分类标准,分
为主干分枝型、中心圆型或近似圆型类两类。每一类选择35个数据作为训练集
建立模型。
利用LIBSVM依据刘凤君教授提出的分类标准对骨刻文进行分类,最后给出了分类结果。
3)对骨刻文与彝文的相似度进行分析
8.https://d.wanfangdata.com.cn/thesis/ChJUaGVzaXNOZXdTMjAyMTA1MTkSCFkyMTgzOTIyGgg0YXNpZjZjdg%3D%3D
特征计算是通过特定的算法对骨刻文二值图像进行特征的计算、更新和存储。特征计算方法包括四种:同心圆算法、同心圆+距离算法、Zemike算法和仿射Zemike算法。
配置python、anaconda、pytorch环境
(范、张)

















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









