







在CS231N的课程中提到了卷积神经网络的可视化,其中大多数的内容都是来自于这篇论文,因为对卷积神经网络的内容不是很理解,所以又读了一下这篇论文。
一、介绍
目前神经网络领域有这很大的进步,更大的数据集、GPU的发展、正则化技术的引入都让神经网络领域向着更强的方向发展。模型识别的效果越来越好,但是对模型的内部构造仍然是一头雾水,不能够很好地理解内部的结构,整个模型仍然是一个黑箱。
这片论文提出了一种可视化神经网络内部的方法,并利用这种方法,对现有的神经网络的结构进行可视化和检验,基于检验结果改进网络的结构,让识别的正确率进一步提高。
二、相关工作
一般的可视化工作都是停留在第一层的像素空间,因为低层的特征提取还具有一般性质,人还比较容易理解,一旦到了高层上,特征越来越抽象,人想要直接去理解也变得越来越难。Donahue在他的论文里面提出了数据集中的局部图片对高层神经元的激活有着很大的作用。这篇论文在此基础上提出的可视化,不仅仅是输入图片的产物,而是一种从高层到低层的映射,能够展示出原图中的哪部分对激活起着重要的作用。
三、处理方法
首先作者选择了LeNet的模型作为要可视化的模型,这个模型的结构如下:
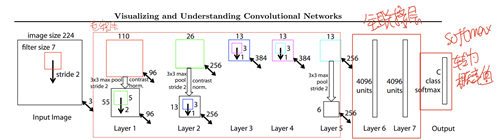
这个模型除了输入和输出,一共有七层,其中五个卷积层用于提取特征,两个全连接层用于特征的分类。与一般的卷积神经网络不同的是,这个网络并不是卷积-池化的循环,而是卷积-非线性-池化的循环。
卷积和池化的部分和一般的卷积神经网络都一样,这里对非线性的部分单独记录一下,非线性的部分使用的是ReLU函数,这个函数会去掉所有的负值,对卷积后的特征图使用非线性处理,主要目的还是对特征图进行过滤,过滤掉其中的负值之后,让特征图更加明显。除此之外,可以使用其它非线性函数例如tanh、sigmoid替代ReLU ,然而ReLU被发现在大多数场景下表现更为出色。

这里有两个英文单词,简单记录一下:
patch:原图中的一个小图片,或者叫图像块,当需要处理的图太大的时候,就可以将原图拆分为一个个小块,一次只处理一个小块,之后随着卷积核的移动换到下一个小块。
activation:在卷积层之后增加一个激活层,让所有特征图的所有点经过一个激活函数,这个激活函数一般是ReLU激活函数或者是ReLU的延伸函数,通过这个激活层,去除特征图中一部分没有用的点,一方面可以让特征图更加明确,同时也可以减少参数之间的相互依赖关系,从而缓解过拟合的问题。此时可能是将经过激活层后的特征图里面所有点的值加起来作为激活值,这样来看哪一个是最强激活特征图。
回到论文,利用这个网络结构训练的模型进行可视化的设计。理解神经网络的中间层次是比较困难的问题,因为这部分层次无法直接由人来理解,这个论文提出的方法是将这些activities反向映射到输入像素空间,从而得到是图中的哪部分对这个activity起了作用。关于这个activity,想来想去干脆不翻译直接用这个词,这个词从上下文来看,指的是一个经过ReLU函数处理的特征图,可以看作是一个卷积核提取出来的特征信息。
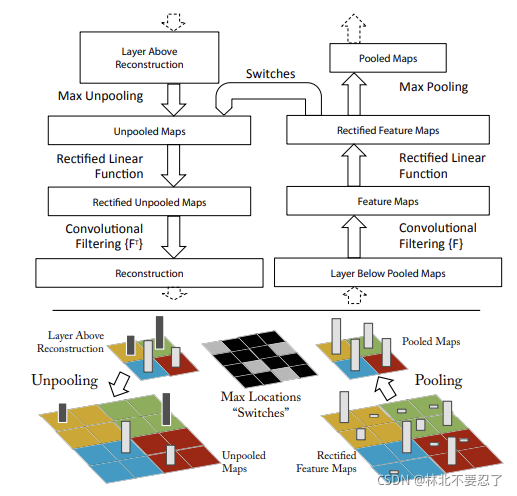
上图反应了这个反卷积网络的基本思路,首先是一个正向的过程,输入一个图片,图片经过神经网络的处理,在某个要检验的卷积核处停止,目前原始的图片变成了一个特征图,特征图经过这个卷积核运算,变成另一个卷积核,经过ReLU函数后,在池化之前进入反向的操作。经过反池化、纠正和过滤,最终一轮一轮重建到初试输入空间。
反向映射的过程则需要使用反卷积网络,这个网络使用相同的结构,只不过是反过来的,这样就可以实现反向的映射。具体来说,反向的映射包括三个反向操作:
① 反池化
从名字就可以看出,这个过程是对池化的反操作。根据池化的过程,其实池化是不可逆的,因为每个池化区域内部只保留了最大值,而剩下的值都被丢弃了。所以如果要进行反向操作,就必须增加一个记录最大位置的量,也就是记录下正向池化时最大值是在哪里取的,这样反池化的时候才可以将最大值恢复到正确的位置。
② 纠正
纠正是对非线性部分的反操作,非线性使用的是ReLU函数,这个函数只保留了正值,而所有的负数都变成了0,所以反向操作的时候,只允许正值通过,其余值返回0。这里刚好和CS231N中的反卷积对应上了,区别在于这里是反向传播特征图,而网课里面是反向传播的梯度,但是用的都是反卷积的思路。
③ 过滤
这部分是对卷积的反操作,需要利用卷积核的转置,和反向的特征图去计算,从而返回到上一层。
经过寻多次这样的循环操作,最终一张特征图被反向对应到了输入像素空间,对于这个过程,我们的起点实际上是一张特征图,而特征图是从原图上提取出的细节,而这些细节对应的是原始输入空间上的部分,这就是整个过程的最终结果。现在经过反向操作,我们得到了原始图片上的哪部分对某个特征图的激活起了最关键的作用。也可以这样去想,特征图是经过一轮一轮的筛选剩下的,那么反过来,将这部分反向恢复,不恢复一开始剔除的部分,那么剩下的必然是一开始在原图里的细节,这部分细节就是恢复的起点所使用的特征图。
四、训练的细节
在进行结构的检验时,论文对上面提到的网络结构做出了一定的更改,这一部分会在后面实际应用的位置提到。除此之外,网络沿用了ImageNet的数据集,并且保持了统一的设定,比如使用batchsize为128的随机梯度下降,学习率设置为0.01,权重和偏置值的初始化等内容。
五、卷积网络的可视化
这部分的内容个人感觉更像是利用上面的反向操作去进行一些实际的应用的过程。论文利用上一部分的网络结构去进行了一些验证。
论文做了几个实验,首先是特征的可视化。论文选取了每一层激活值最高的九张图片,利用这些图片反向传回第一层,将结果显示出来,按照前面的说法,这里得到的是对于这张特征图原图上激活作用最强的部分。之后论文放了一张特别大的图,这张图展示了反向传回的结果:

对于这张图,论文举了其中的一个例子,在第五层第一行第二列的9张图片,把图片拎出来是下面的情况:


从这一组结果来看,这组图片的共同点并不多,而通过反向传播得到的数据可以看出来,我们选出来的这个特征图实际上是筛选出了这组图片背景中的绿色草地,而不是图片中的其他内容。
除此之外,通过这个实验我们还可以看出,特征的提取实际上也是具有分层结构的,越高层的特征图反向传回输入像素空间,得到的特征就越细化,就越可以看出图片中的物体是什么。
第二个实验是特征提取的演变实验,这个实验是在训练的过程中,不断反向传回,从而可视化了整个模型训练的过程,利用这个可视化,我们可以验证模型的收敛情况,低层次的可能几轮训练就可以收敛,但是高层可能需要较多轮训练才能得到比较好的结果。

这张图就是实验的结果,图里的每一行表示的是训练过程中每一层激活值最高的图片的反向传回结果,可以看出前面的几次结果特征并不明显,但是随着训练轮数的增加,特征也就越来越明显。
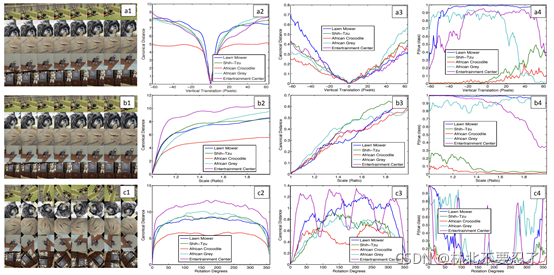
第三个实验是特征的不变性。这个实验是对输入的图像进行不同程度的旋转、平移,看看特征提取等内容会发生什么变化。从实验结果来看,小的改变可能会对低层产生很大的变化,但是反应在高层,并没有产生太大的影响。这个实验的结果就很丰富,最左边的一列是对同一张输入图片进行不同的变换,计算每一层输出的特征向量与标准情况下的欧式距离,也就是第二列和第三列,这两列表示的是第一层和第七层的欧式距离情况,而最右边一列表示的就是对判断概率的影响。可以看出,对第七层产生的影响要明显远小于第一层(注意看纵坐标的数量级)。
利用这些特性,论文提出了三个主要的应用:
①利用可视化去调整网络的结构
利用可视化的方法,将某一层的结果反向传回输入像素空间,然后看得到的结果是否具有一般性,如果不太合适,就适当调整网络的结构,比如步长、感受野的大小等内容,不断重复直到特征提取的效果变好。

这张图是论文中对这个应用的实验,a图是没有处理过的原图,b是利用原来的网络结构处理得到的特征图,c图是经过优化后提取的特征图,可以看出处理之前得到的特征图是高频信息和低频信息的混合,而对于中等频率的信息则保留不足,基于这个可视化的结果,对网络的结构进行调整,这里是将感受野变小,并且将卷积核移动的步长变小,利用新的结构重新跑,不难发现结果确实得到了明显的提升,提取的特征变得更加明显。
②遮挡实验
遮挡实验指的是挡住原图中的一部分,看在不同层的特征图会发生怎样的变化,这里看特征图的变化有两个方向,一个方向是直接看特征图,也可以利用前面的反向操作,将高层的内容返回到输入像素空间,看返回的图的内容。利用遮挡实验,最直观的作用就是回答了神经网络判断类别是依据图片里的哪个部分的问题。主要是看判断的正确率,当在遮住某一部分时正确率发生了很大的变化,就说明做出这一判断主要是依据遮住的部分,而不是其余的部分。
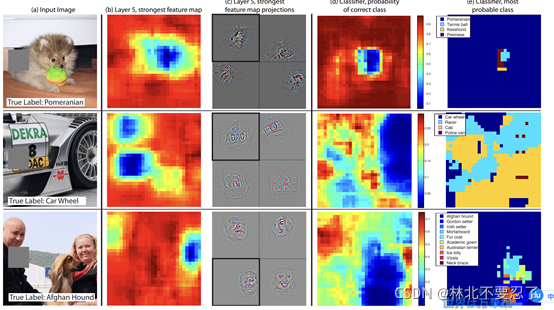
这个图是论文里做的实验,实验是移动输入里面的灰色块,将灰色块的位置作为变量,看特征图和反向操作的结果会发生什么样的变化,并且计算分类的概率情况。第二列和第三列是一对,分别是特征图和返回到输入向量空间的图,它们代表第五层最大激活的特征图对应到原始输入的位置。这里第二行和第三行虽然最大激活并不是我们需要的特征,但是经过多个特征图综合之后就变成了最需要的特征。这里暂且不看第二行第三行。对于第一行来说,可以看见最大激活的特征就是博美的脸,正好是我们需要的特征,第四列可以看见,当灰色块移动到后脸上时,正确分类的概率会下降,而在第五列也可以看出,当遮住狗脸的时候分类器会认为图片中的内容是网球。
③一致性分析
一致性分析个人感觉是在检验模型是否真正把握到了特征,这个实验说将不同图片中狗的同一位置遮住,看得到的特征向量与原始向量的差别,即做差得到一个差向量,再计算不同图同一遮挡位置下差向量的汉明距离,距离小则说明一致性强。
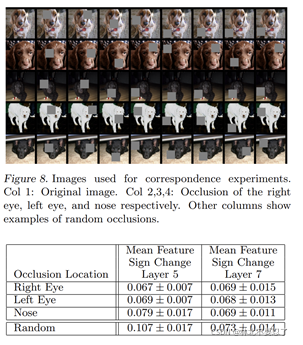
汉明距离小,说明差向量之间差距小,说明挡住同一部分对判断产生的偏差是一样的,所以相当于这个网络确实对不同图片的同一部位产生了正确的判断。而随机的遮住特征,汉明距离差距较大,意味着差向量相差较大,说明遮住的部位对判断产生的影响是不同的,所以遮住的部位不具有一致性。
六、实验
这部分不再赘述,改进的模型取得了很大的提升,取得了ImageNet2012的冠军。


















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











