







激活函数
在人工神经网络中,激活函数扮演了重要的角色,其作用就是作为隐藏层和输出层之间作为一个非线性的操作。
设想,如果我们的函数都是线性的那,那么无论经过多少层,他的输出都不会进行改变。
选择合适的激活函数
梯度消失和梯度爆炸式训练神经网络经常会遇到的问题,所以选择合适的激活函数就十分重要。
输出层选择激活函数:
- 回归任务选择线性激活函数
- 二分类任务选择sigmod激活函数
- 多分类任务选择softmax激活函数
- 多标签任务选择sigmod激活函数
隐藏层选择激活函数,一般根据神经网络类型来进行选择:
- 卷积神经网络选择Relu激活函数或者其改进型的激活函数,LeakyRelu 、Prelu、Selu等
- 递归神经网络选择sigmoid或者Tanh激活函数
除此之外,还有下面一些经验准则以供参考:
ReLU及其改进型激活函数只适合用在隐藏层。Sigmoid和Tanh激活函数一般用在输出层而不适合用在隐藏层。Swish激活函数适合用于超过40层的神经网络。
常见以及的几种函数有以下几种。
1 :sigmoid激活函数
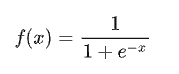
Sigmod函数 Sigmod导数
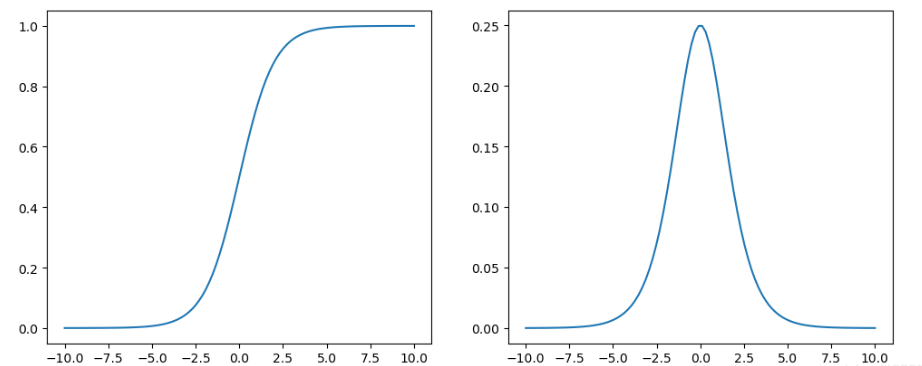
Sigmod函数
优点
1:值域范围在【0,1】 适合模型输出函数用于0-1范围内的概率值,比如二分类或者表示置信度。
2:函数连续可导,可以提供非常平滑的梯度值,防止模型训练过程中出现突变的梯度。
缺点
1:参考导数函数图像,sigmod容易出现饱和的状态,当X值在【-5,5】的范围外时其导数接近于0,曲线接近饱和,不会递增或者递减。
反向传播时权重就几乎得不到更新,从而导致模型难以训练。这种现象称呼为梯度消失。
2:输出不是以0为中心,几乎都是大于0的,这样下一层的升级元会得到上一层的全正信号作为输入,
所以sigmod激活函数一般都放置于神经网络的最后输出层使用。
2: ReLU激活函数
![]()
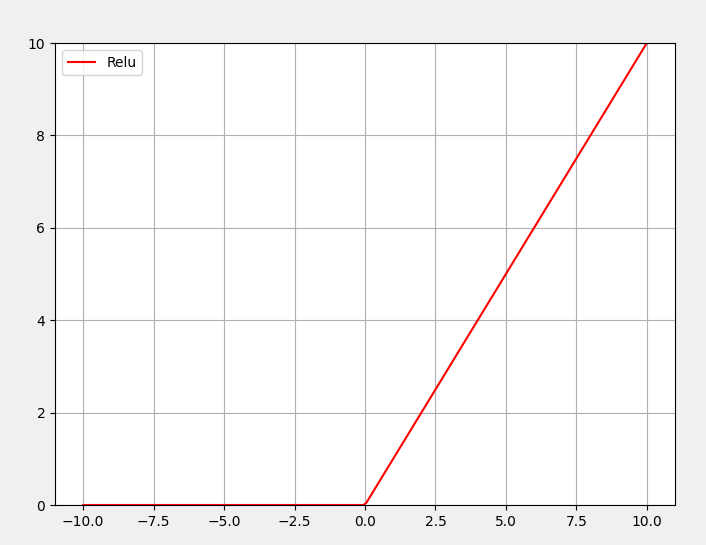
Relu函数
优点
1:可以解决Sigmod和TanH梯度消失的问题。
缺点
1:输出不是以0为中心,前向4传播如果小于0,则输出全为0,
反向传播时没有梯度回传,从而使得神经元权重得不到更新。神经元处于非激活状态
3: Leaky_Relu 激活函数
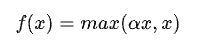
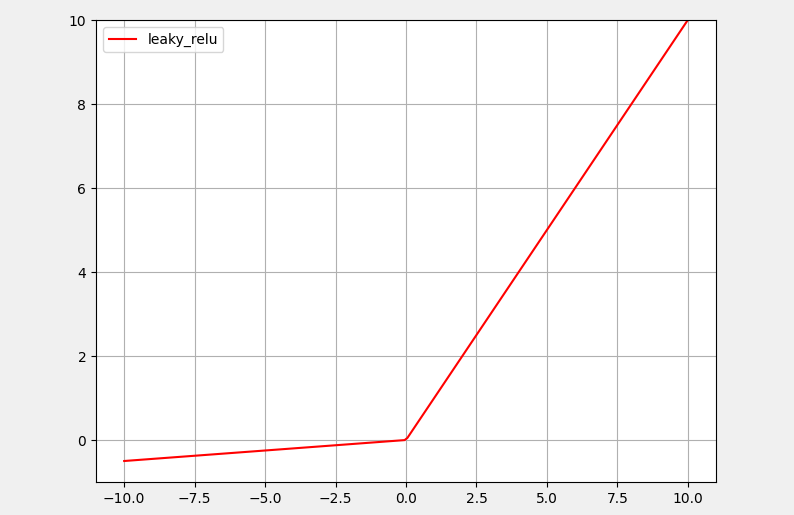
LeakyRelu激活函数在负半轴添加一个小的正斜率解决Relu激活函数的死区问题,该斜率参数a是手动设置的超参数,一般设置为0.01。
torch.nn.LeakyReLU(x,negative_slope=0.01)LeakyRelu通过这种方式,可以确保模型在小于0的情况下依旧会得到更新。
同时还有一种Prelu激活函数,Prelu激活函数的斜率参数a是通过学习而得到的而不是手动设置的恒定值,通过学习的方法去选择似乎更加合理一些
4:ELU激活函数
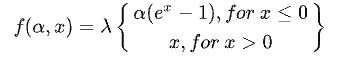
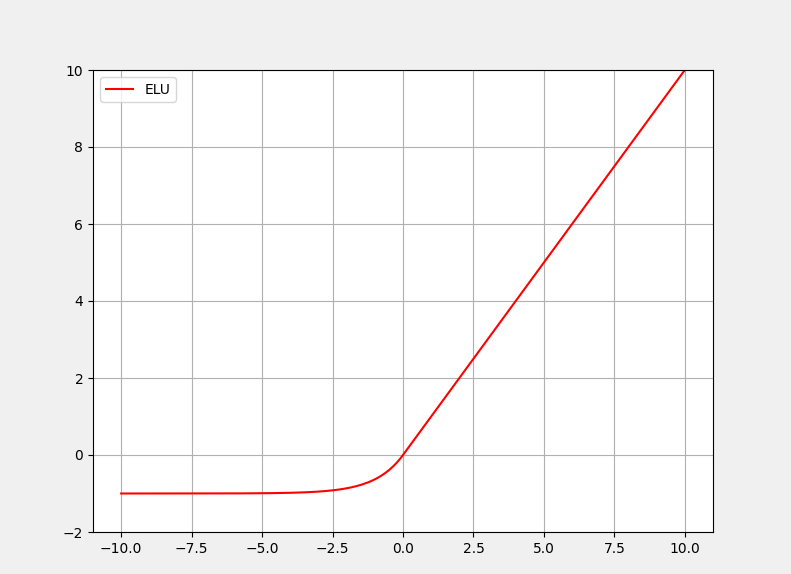
优点
与Relu激活函数不同,ELU激活函数负半轴是一个指数函数而不是一条直线,整个函数更加平滑,这样可以使得训练过程中模型的收敛速度更快
5:SELU激活函数
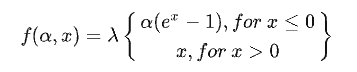
![]()
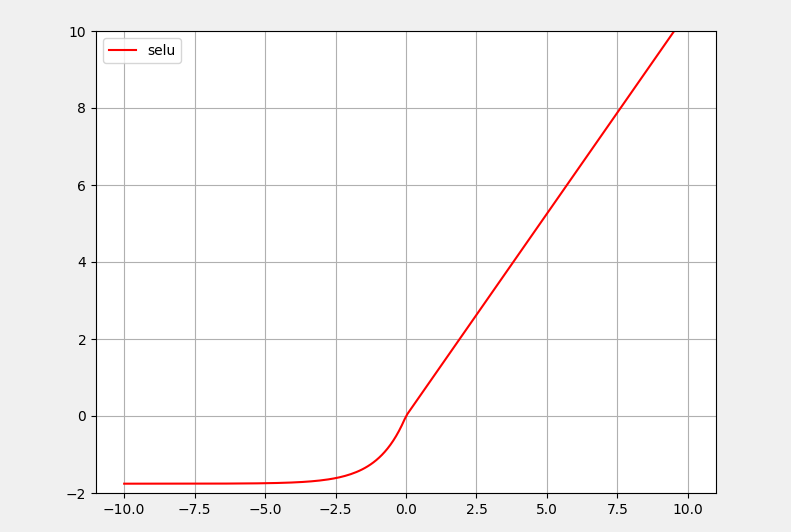
SELU激活函数是在自归一化网络中定义的,通过调整均值和方差来实现内部的归一化,这种内部归一化比外部归一化更快,这使得网络收敛得更快。
6:Swish激活函数
![]()
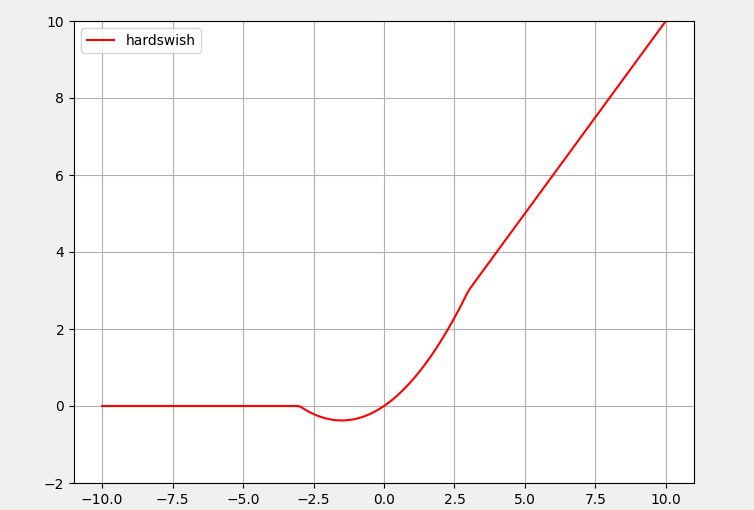
Swish激活函数具备无上界而有下界、平滑、非单调的特性,这些特性能够在模型训练过程中发挥有利的影响。与上述其他函数相比,Swish激活函数在x=0附近更为平滑,而非单调的特性增强了输入数据和要学习的权重的表达能力。
7:Mish激活函数
![]()
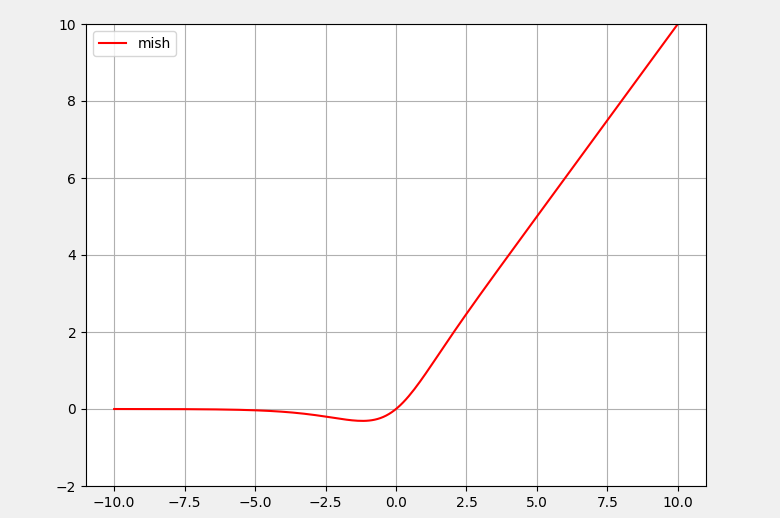
Mish激活函数的函数图像与Swish激活函数类似,但要更为平滑一些,缺点是计算复杂度要更高一些。
- 无上界,非饱和,避免了因饱和而导致梯度为0(梯度消失/梯度爆炸),进而导致训练速度大大下降;
- 有下界,在负半轴有较小的权重,可以防止ReLU函数出现的神经元坏死现象;同时可以产生更强的正则化效果;
- 自身本就具有自正则化效果(公式可以推导),可以使梯度和函数本身更加平滑(Smooth),且是每个点几乎都是平滑的,这就更容易优化而且也可以更好的泛化。随着网络越深,信息可以更深入的流动。
- x<0,保留了少量的负信息,避免了ReLU的Dying ReLU现象,这有利于更好的表达和信息流动。
- 连续可微,避免奇异点
- 非单调















 3243
3243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









