







1--并行实现数组相加
定义两个数组 a 和 b,通过在 GPU 上实现两个数组的并行相加;
#include <iostream>
#include "cuda_runtime.h"
#define N 10
// From book.h
#define HANDLE_ERROR( err ) (HandleError( err, __FILE__, __LINE__ ))
static void HandleError( cudaError_t err,
const char *file,
int line ) {
if (err != cudaSuccess) {
printf( "%s in %s at line %d\n", cudaGetErrorString( err ),
file, line );
exit( EXIT_FAILURE );
}
}
// Add 函数
__global__ void add(int *a, int *b, int *c){
int tid = blockIdx.x;
if (tid < N)
c[tid] = a[tid] + b[tid];
}
int main(void){
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
// 在GPU上分配内存
HANDLE_ERROR(cudaMalloc( (void**)&dev_a, N*sizeof(int) ));
HANDLE_ERROR(cudaMalloc( (void**)&dev_b, N*sizeof(int) ));
HANDLE_ERROR(cudaMalloc( (void**)&dev_c, N*sizeof(int) ));
// 在CPU上为数组 'a' 和 'b'赋值
for (int i = 0; i < N; i++){
a[i] = -i;
b[i] = i * i;
}
// 将数据从主机复制到 GPU 当中
HANDLE_ERROR(cudaMemcpy( dev_a, a, N*sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy( dev_b, b, N*sizeof(int), cudaMemcpyHostToDevice));
add<<<N, 1>>>(dev_a, dev_b, dev_c);
// 将结果从 GPU 复制到 主机中
HANDLE_ERROR(cudaMemcpy( c, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost));
// 打印结果
for (int i = 0; i < N; i++){
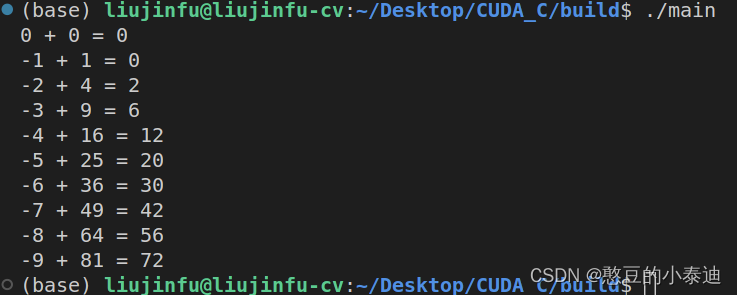
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
// 释放在 GPU 中分配的内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
代码解读:
通过修饰符__global__声明核函数;
add<<<N, 1>>>(dev_a, dev_b, dev_c) 中的参数 N 表示设备在执行核函数 add() 时使用的并行线程块数量;
blockIdx.x 是一个内置变量,其值表示执行当前设备代码的线程块的索引;
当启动核函数时,若将并行线程块的数量指定为N,这个并行线程块集合则称为一个线程格 (Grid);第一个线程格的blockIdx.x为 0,最后一个线程格的 blockIdx.x 为 N - 1;
注意事项:在启动线程块数组时,数组每一维的最大数量不能超过65 535(硬件限制),否则程序将运行失败;















 4420
4420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









