







一 概述
目标检测算法主要分为两类,one stage 和 two stage,one stage是指直接通过网络回归目标的类别和位置,另一种是首先训练RPN网络找到目标的位置,然后通过分类网络判定目标的类别。
一般来说,one stage网络检测速度快,但难以达到two stage网络的检测精度,而two stage网络速度慢,落地困难。而Focal loss函数的目的就是为了提高one stage检测精度。
学者们认为one stage检测精度难以达到two stage的一个重要原因是,在目标检测过程中,一张图片可以生成大量的样本,而只有少部分样本是包含目标的,即少数样本为正样本,大多数样本为负样本。负样本过多会占据损失函数的大部分,导致模型优化的方向不是我们所希望的方向。Focal loss损失函数的作用,就是降低大量简单负样本在训练中所占的比重。
二 函数形式
Focal loss是基于交叉熵损失函数的改进,首先来看二分类的交叉熵损失:
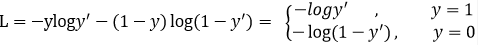
对于正样本,即y=1,预测概率越大损失越小,对于负样本,预测概率越小损失函数越大。
接下来,Focal希望减少易分类样本的损失,而更多的关注难分类,错分类的样本,具体改进如下:
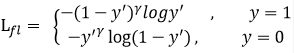
在原有的交叉熵损失函数上添加一个γ因子,其中γ>0。对于正样本而言,y‘越大则表示分类越简单,则损失越小,y’越小则损失越大。同理,对于负样本而言,y‘越小表示分类越简单,损失越小。这样,就减小了易分类样本的影响,而关注难分类和错分类的样本。
此外,为了降低正负样本不均衡的影响,加入平衡因子α,具体如下式:
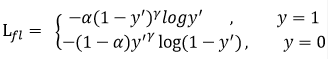
通过调节α的值就可以调节正负样本的比例,从而达到平衡样本的目的。
综上,即为Focal loss函数。
参考:https://www.cnblogs.com/king-lps/p/9497836.html














 3210
3210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









