







参考PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】P6~15
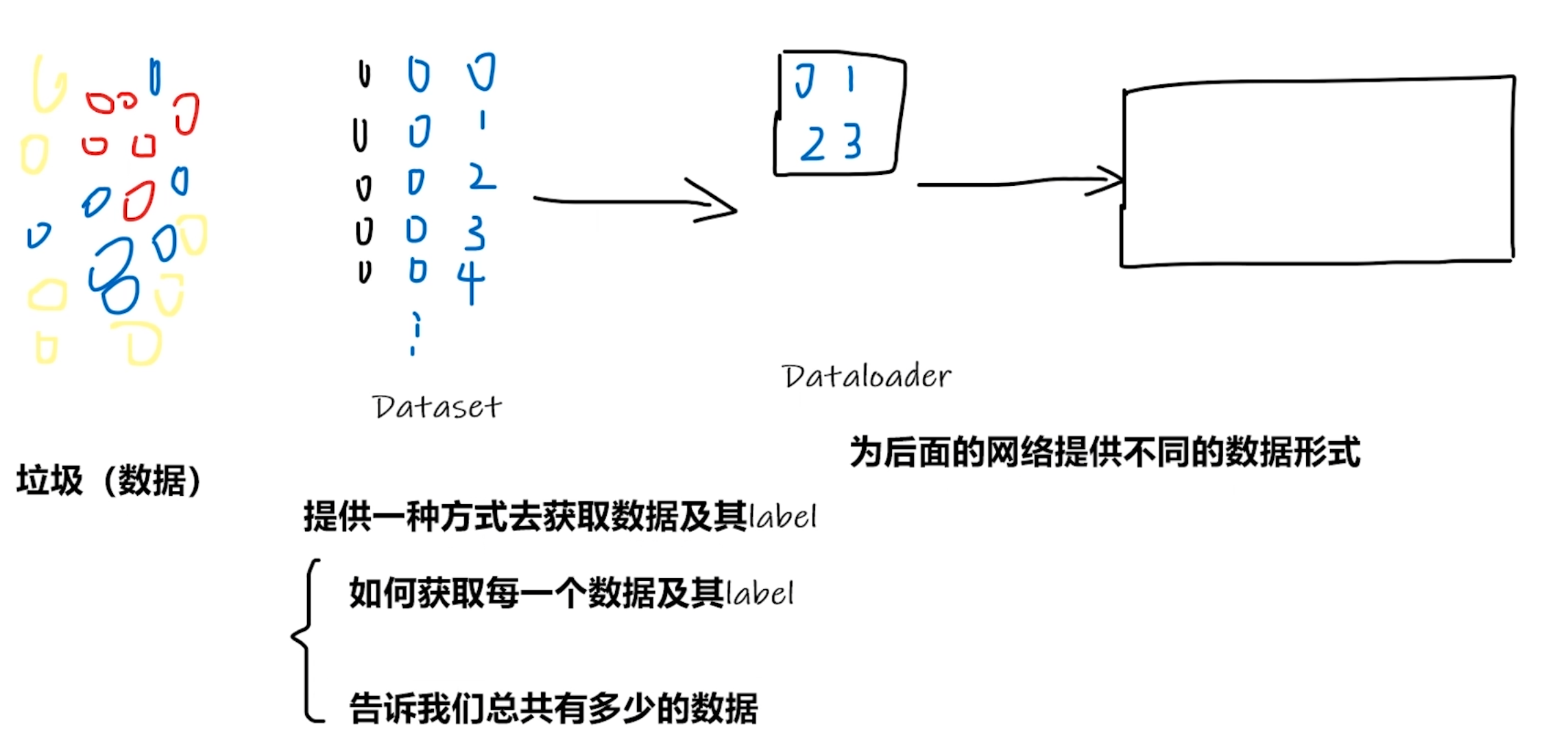
Dataset类
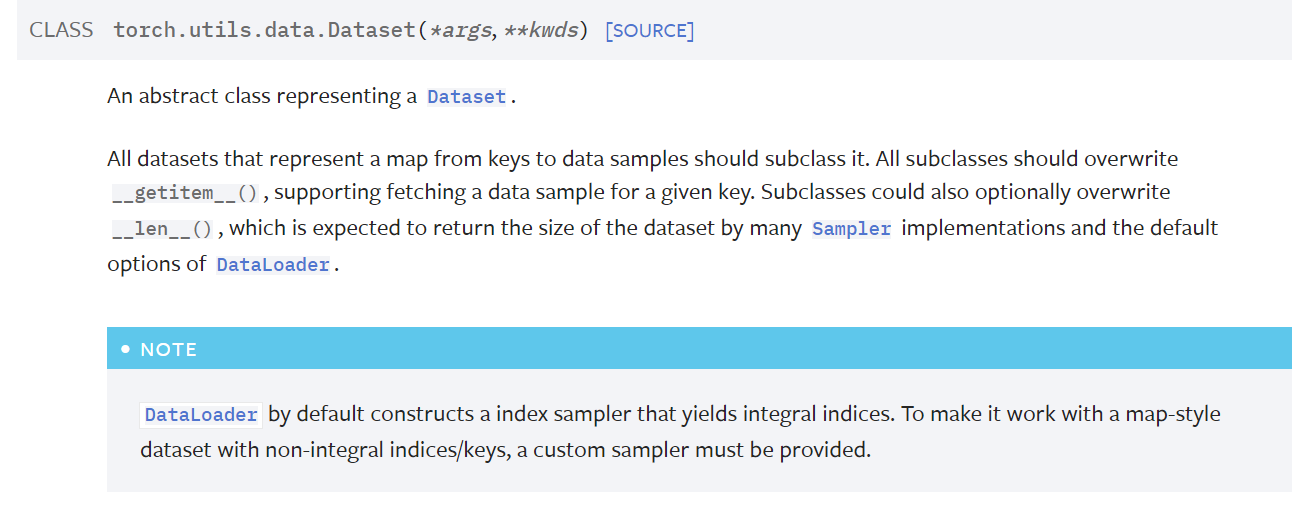
Dataset类一个表示数据集的抽象类torch.utils.data.Dataset
通过继承Dataset类可以实现数据集的加载,定义三个函数,分别是:初始化 __init__()、获得每一个数据 __getitem__()、数据长度 __len__()。
这里面的过程,要很清楚:
__init__()用于初始化数据集的配置,例如数据集的路径、文件名称;__getitem__()用于获取给定键对应的数据__len__()计算数据集的大小。
from torch.utils.data import Dataset
from PIL import Image
import os
# dataset有两个作用:1、加载每一个数据,并获取其label;2、用len()查看数据集的大小
class MyData(Dataset):
def __init__(self, root_dir, label_dir): # 初始化,为这个函数用来设置在类中的全局变量
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir) # 单纯的连接起来而已,背下来怎么用就好了,因为在win下和linux下的斜线方向不一样,所以用这个函数来连接路径
self.img_path = os.listdir(self.path) # img_path 的返回值,就已经是一个列表了
def __getitem__(self, idx): # 获取数据对应的 label
img_name = self.img_path[idx] # img_name 在上一个函数的最后,返回就是一个列表了
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) # 这行的返回,是一个图片的路径,加上图片的名称了,能够直接定位到某一张图片了
img = Image.open(img_item_path) # 这个步骤看来是不可缺少的,要想 show 或者 操作图片之前,必须要把图片打开(读取),也就是 Image.open()一下,这可能是 PIL 这个类型图片的特有操作
label = self.label_dir # 这个例子中,比较特殊,因为图片的 label 值,就是图片所在上一级的目录
return img, label # img 是每一张图片的名称,根据这个名称,就可以使用查看(直接img)、print、size等功能
# label 是这个图片的标签,在当前这个类中,标签,就是只文件夹名称,因为我们就是这样定义的
def __len__(self):
return len(self.img_path) # img_path,已经是一个列表了,len()就是在对这个列表进行一些操作
if __name__ == '__main__':
root_dir = "dataset/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
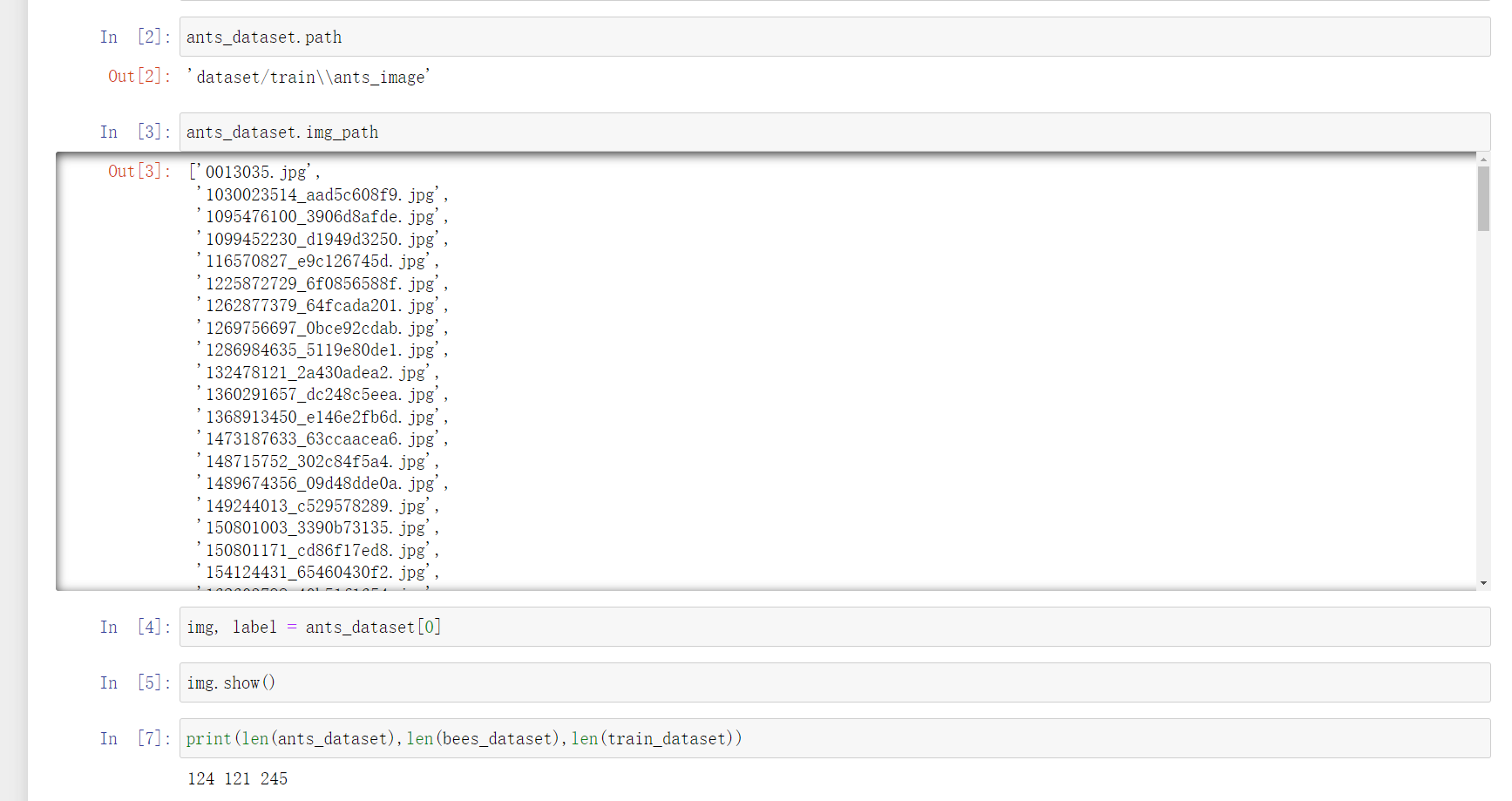
两个Dataset类可以直接相加,结果为两个Dataset类的和。
官网文档解释
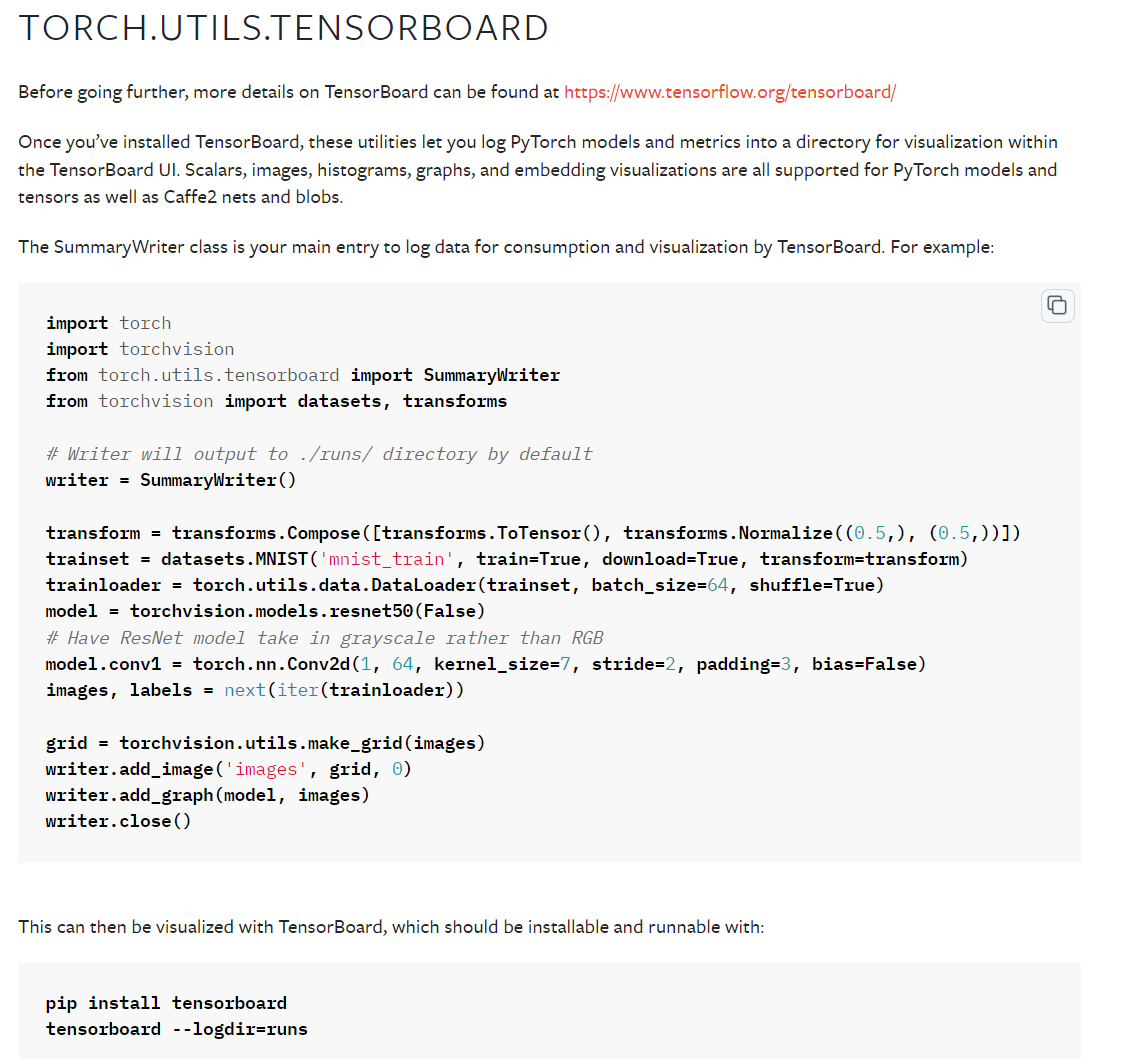
TensorBoard
Tensorboard是tensorflow内置的一个可视化工具,它通过将tensorflow程序输出的日志文件的信息可视化使得tensorflow程序的理解、调试和优化更加简单高效。Tensorboard的可视化依赖于tensorflow程序运行输出的日志文件。
首先需要安装相关的包pip install tensorboard
常见函数
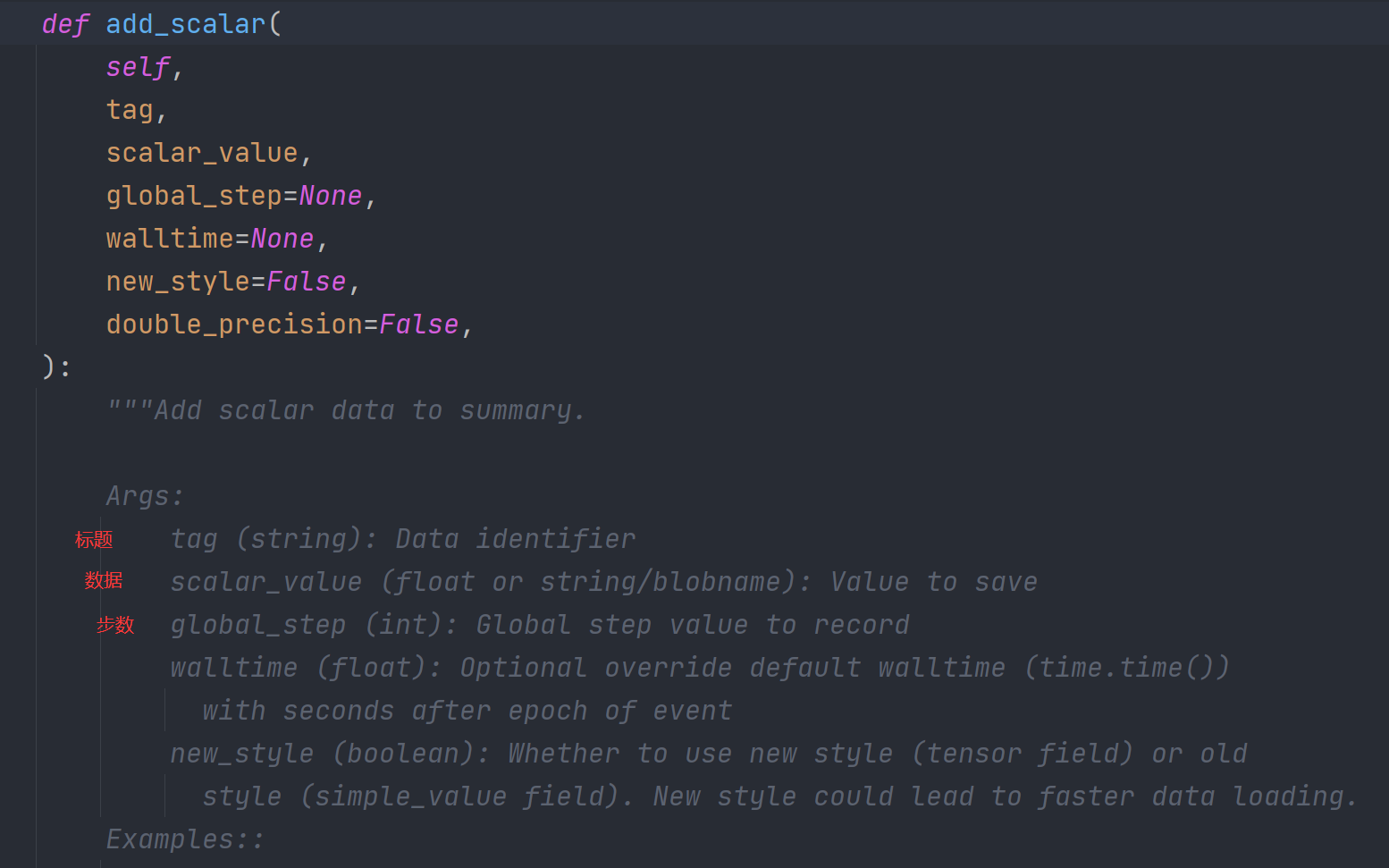
add_scalar()用于展示标量、数add_image()用于展示图片
add_scalar()
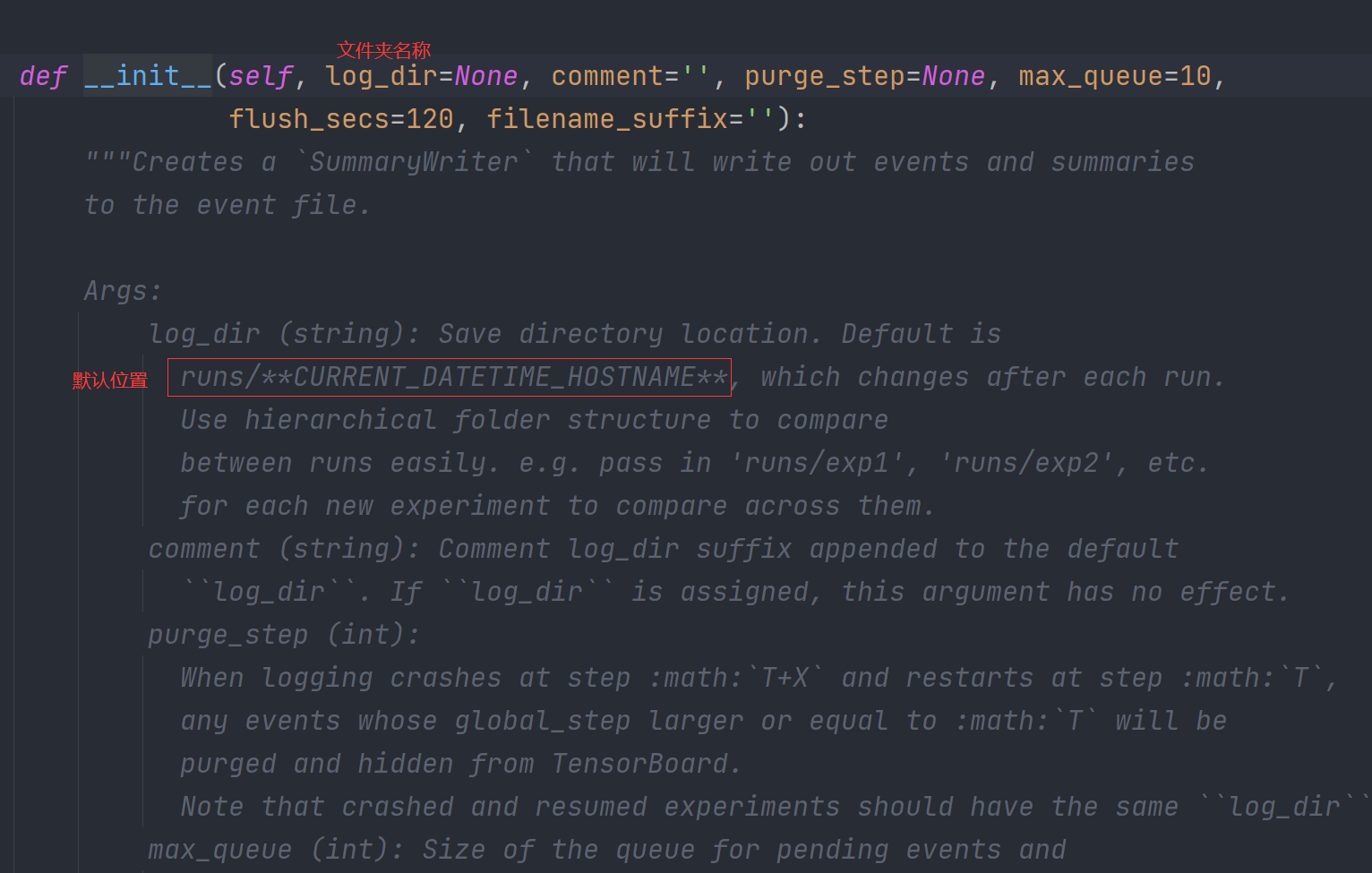
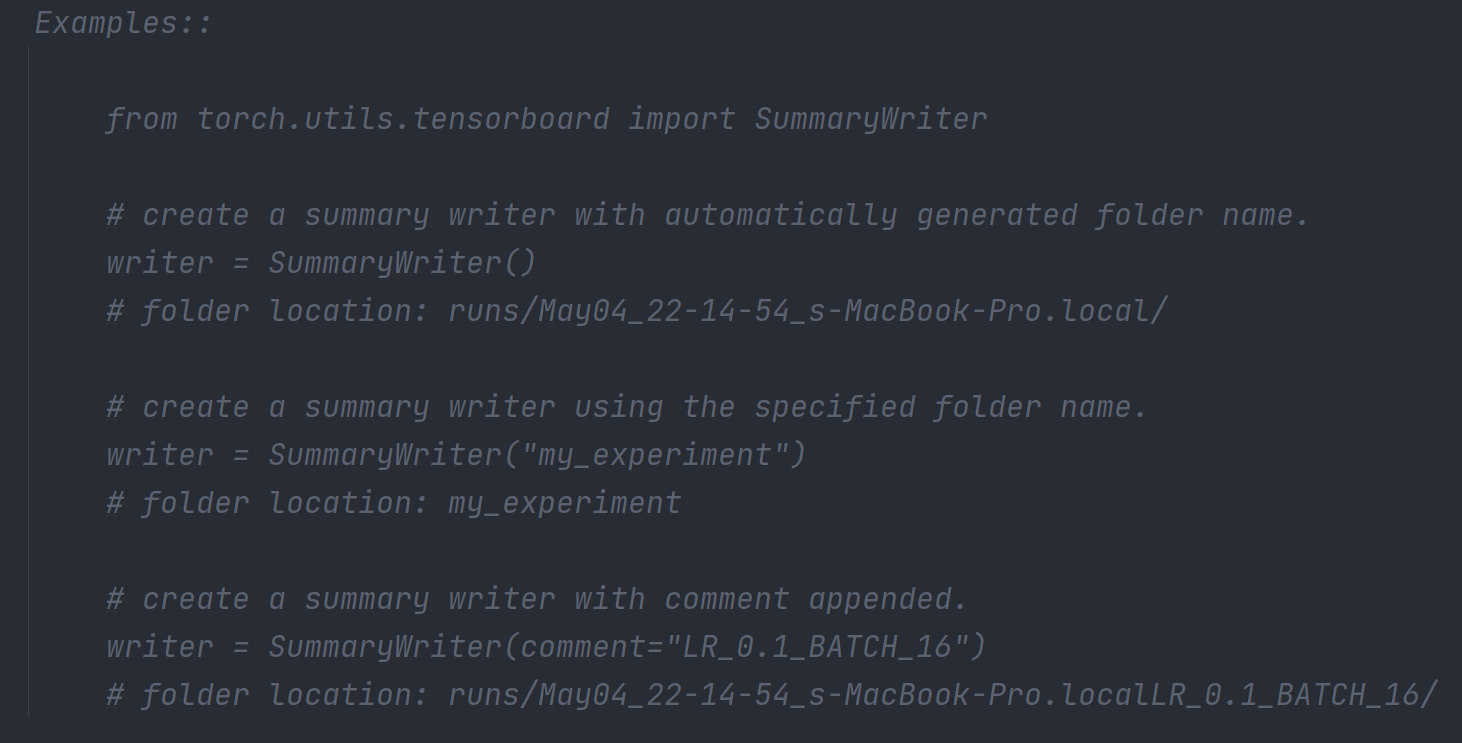
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# y = x
for i in range(100):
writer.add_scalar("y=x", i, i)
writer.close()
SummaryWriter代码(ctrl+鼠标左键点击查看)
官方举例
add_scalar()
如果运行出现这个情况是因为setuptools 版本过高,需要降级
pip uninstall setuptools
pip install setuptools==59.5.0

在项目文件夹中可以看到新增了一个叫logs的文件里,通过在Terminal控制台
输入tensorboard--logdir=logs可以查看生成的网页地址
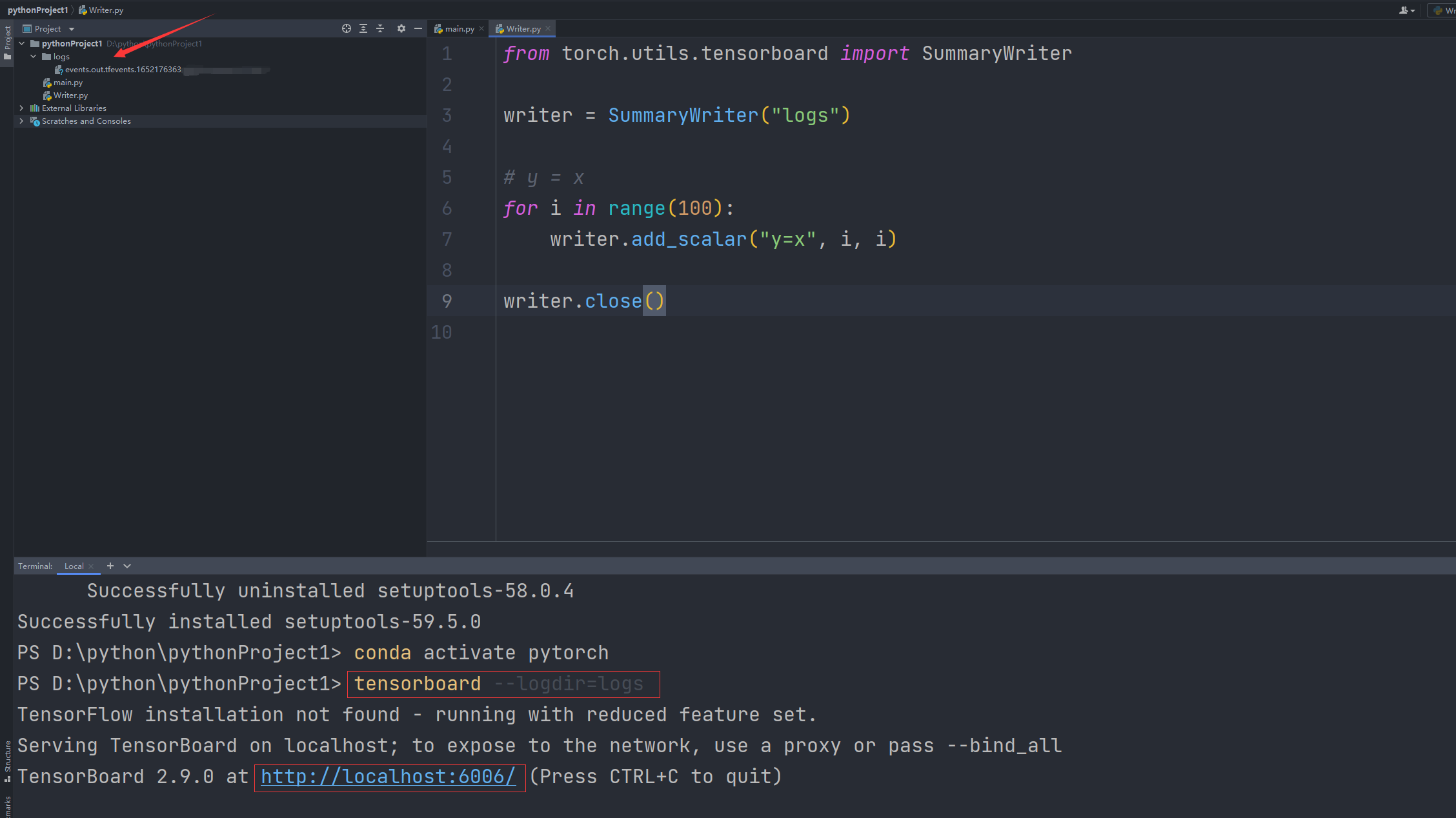
http://localhost:6006/默认为
6006
6006
6006端口
可以通过在添加--port=指定端口来改变端口防止端口冲突

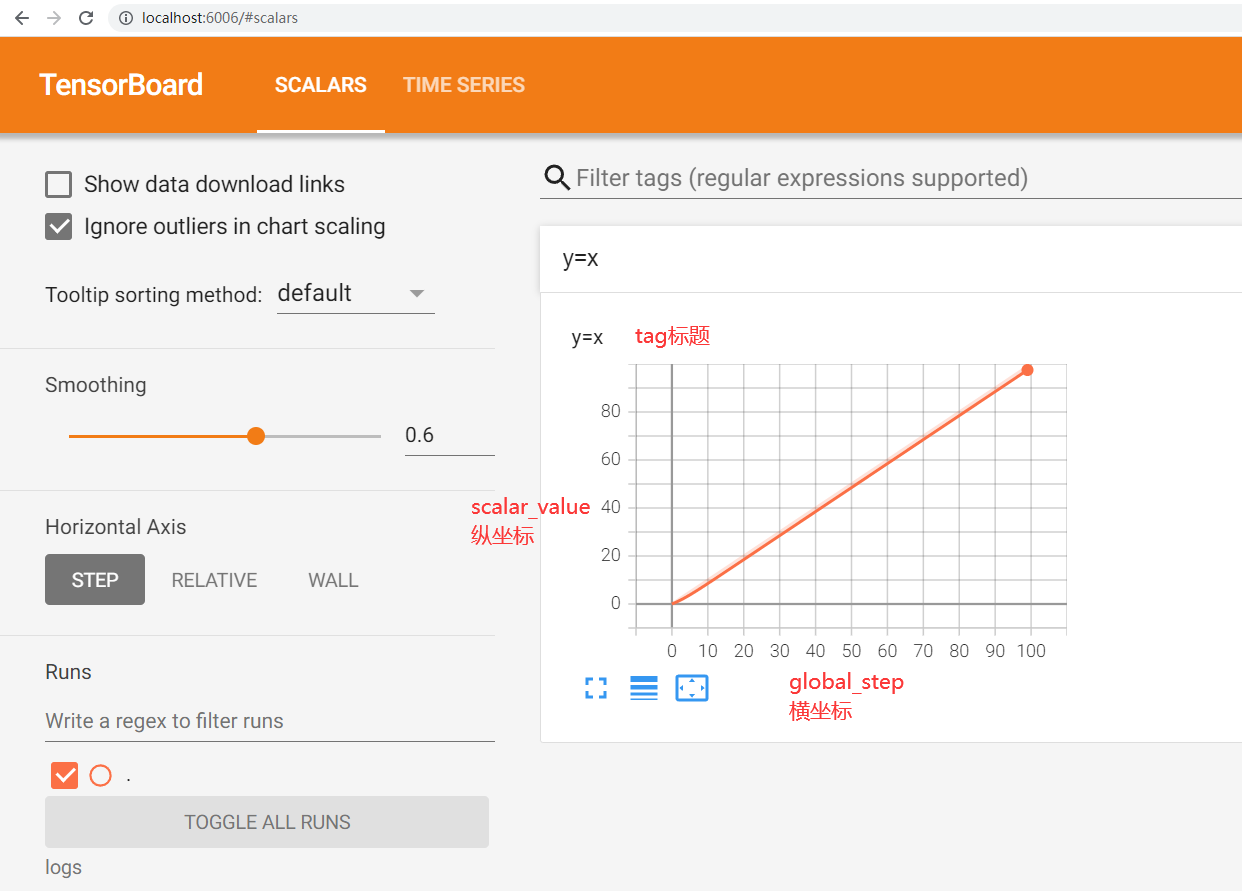
可以通过改变sclar_value和global_step的值来绘制不同的直线
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# y = x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
writer.close()
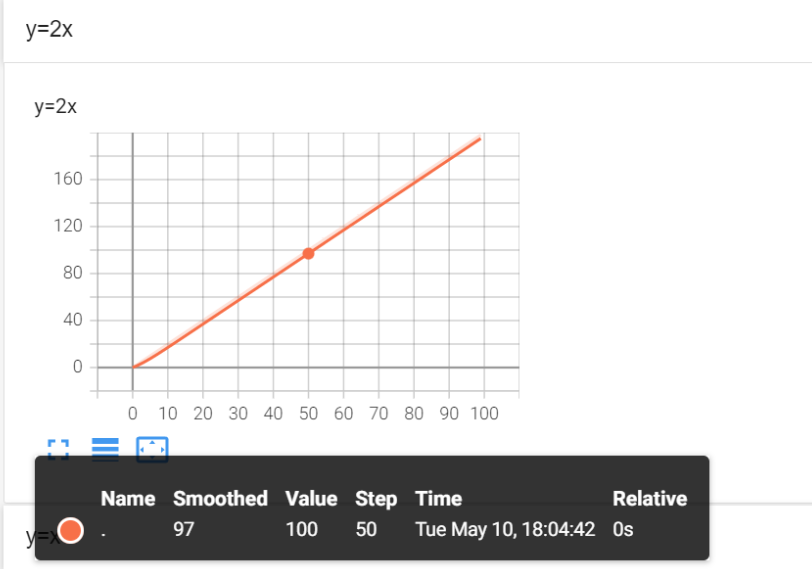
当tag相同时,会在一个坐标系内绘制两幅图,这时候可能会出现过拟合的现象
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# y = x
for i in range(100):
writer.add_scalar("y=2x", 3*i, i)
writer.close()
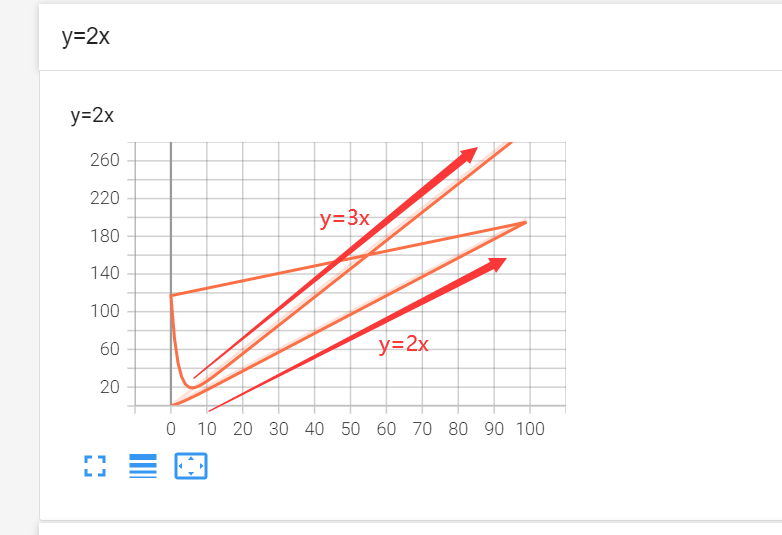
这时候可以将log文件夹下的所有文件都进行删除重新绘制
add_image()
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "data/train/ants_image/6240329_72c01e663e.jpg"
img_PIL = Image.open(image_path) #根据上述路径打开图片
img_array = np.array(img_PIL) #按照numpy类型保存图片的数据信息
print(type(img_array))
# <class 'numpy.ndarray'>
print(img_array.shape)
# (369, 500, 3)
writer.add_image("train", img_array, 1, dataformats='HWC')
writer.close()
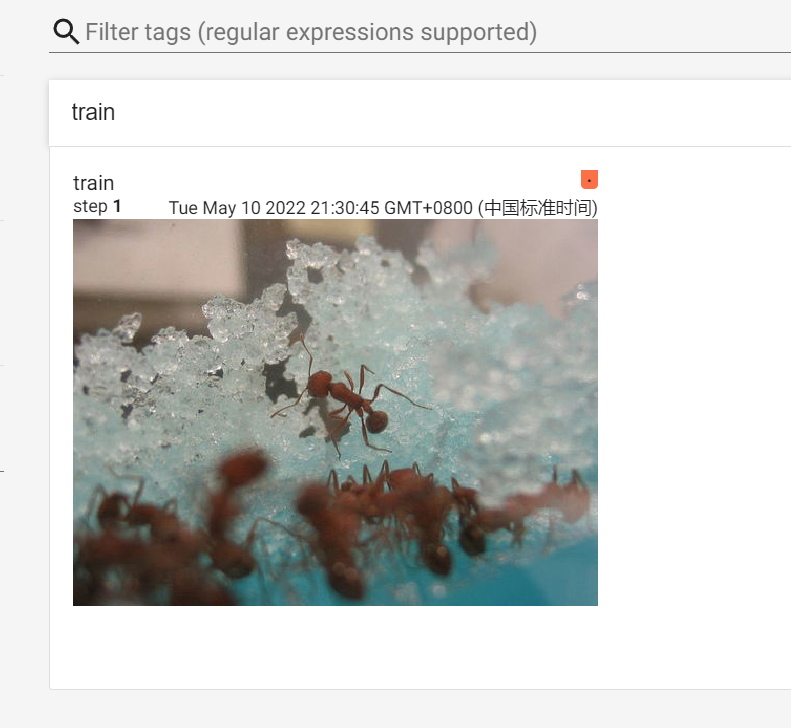
add_image()
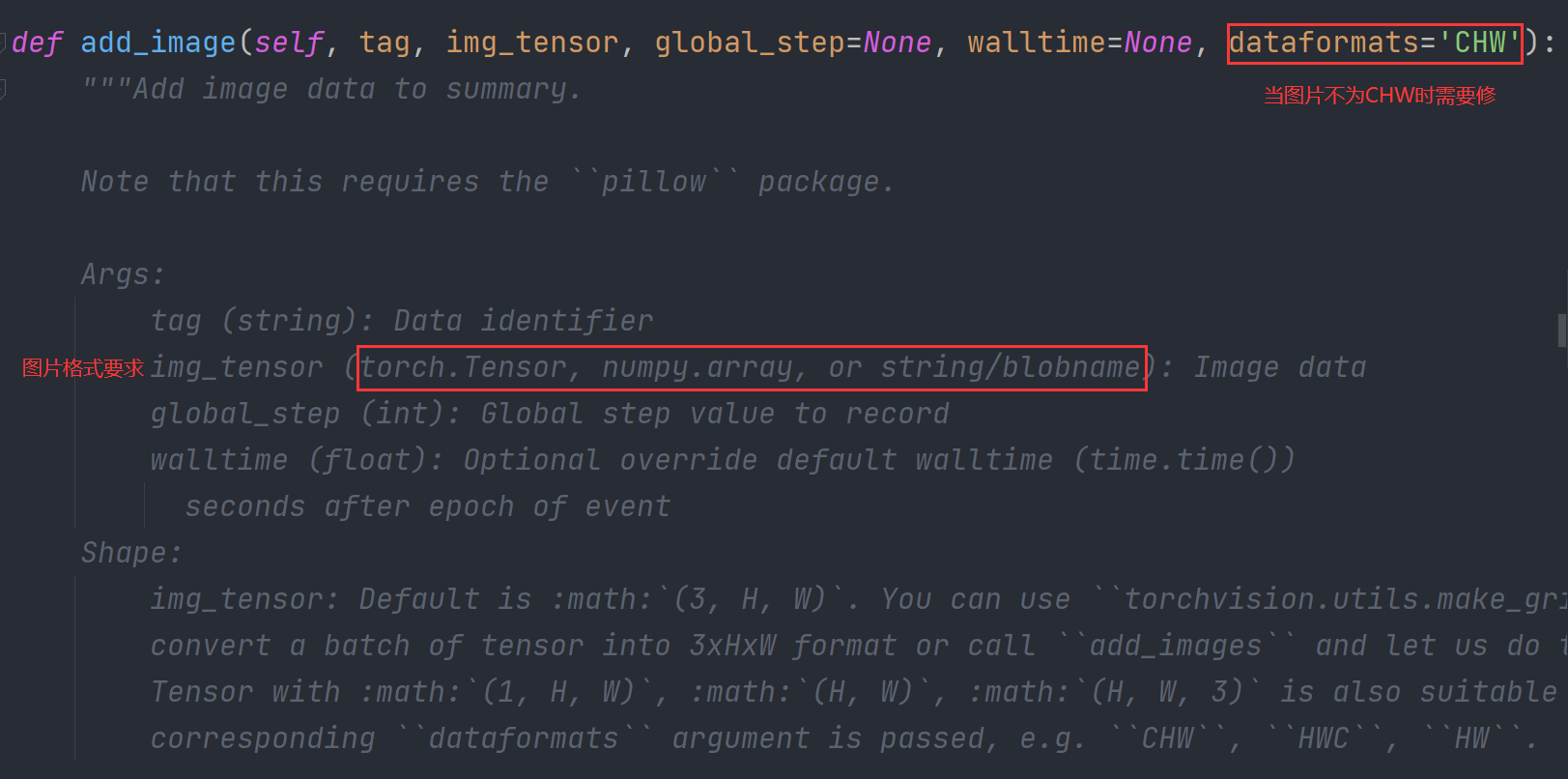
img_tensor要求输入为torch.Tensor,numpy.array, or string/blobname
当图片格式不为CHW时可能出错,可以通过shape属性进行查看
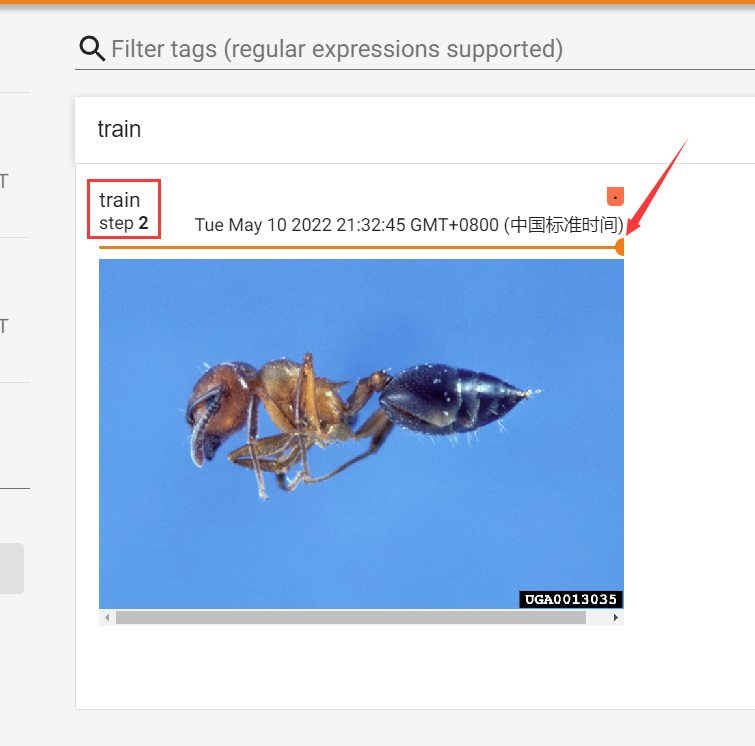
可以通过设置不同的global_step让许多图片全部放置在同一个tag下,通过滑动窗口上的滑轮即可查看不同的图片。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "data/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path) #根据上述路径打开图片
img_array = np.array(img_PIL) #按照numpy类型保存图片的数据信息
print(type(img_array))
# <class 'numpy.ndarray'>
print(img_array.shape)
# (369, 500, 3)
writer.add_image("train", img_array, 2, dataformats='HWC')
writer.close()
Transforms类
torchvision.transforms : 常用的图像预处理方法
如何使用
from torchvision import transforms
from PIL import Image
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path) #打开图片
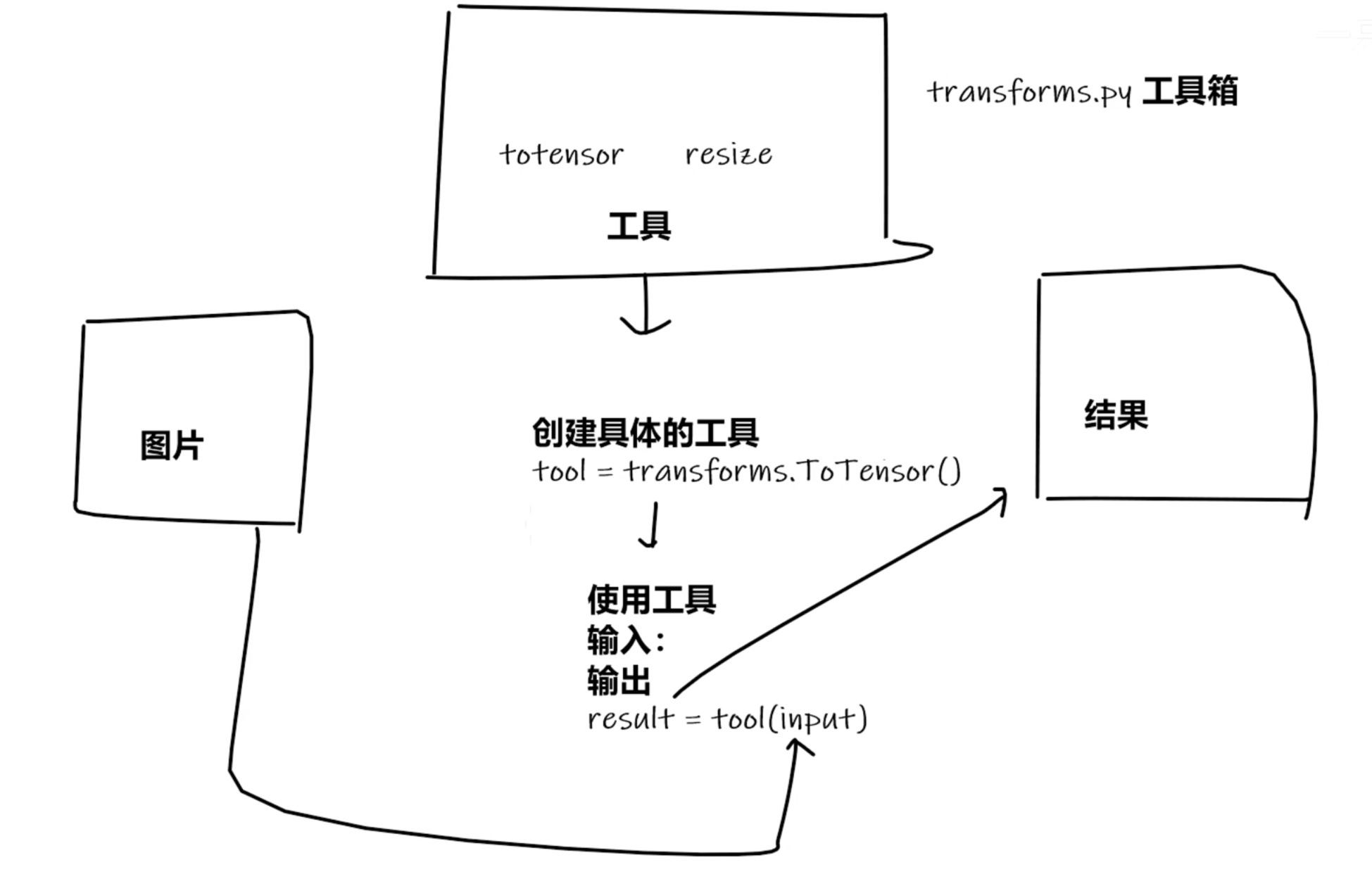
tensor_trans = transforms.ToTensor() #创建工具
tensor_img = tensor_trans(img) #使用工具
print(tensor_img)
'''
tensor([[[0.3137, 0.3137, 0.3137, ..., 0.3176, 0.3098, 0.2980],
[0.3176, 0.3176, 0.3176, ..., 0.3176, 0.3098, 0.2980],
[0.3216, 0.3216, 0.3216, ..., 0.3137, 0.3098, 0.3020],
...,
[0.3412, 0.3412, 0.3373, ..., 0.1725, 0.3725, 0.3529],
[0.3412, 0.3412, 0.3373, ..., 0.3294, 0.3529, 0.3294],
[0.3412, 0.3412, 0.3373, ..., 0.3098, 0.3059, 0.3294]],
[[0.5922, 0.5922, 0.5922, ..., 0.5961, 0.5882, 0.5765],
[0.5961, 0.5961, 0.5961, ..., 0.5961, 0.5882, 0.5765],
[0.6000, 0.6000, 0.6000, ..., 0.5922, 0.5882, 0.5804],
...,
[0.6275, 0.6275, 0.6235, ..., 0.3608, 0.6196, 0.6157],
[0.6275, 0.6275, 0.6235, ..., 0.5765, 0.6275, 0.5961],
[0.6275, 0.6275, 0.6235, ..., 0.6275, 0.6235, 0.6314]],
[[0.9137, 0.9137, 0.9137, ..., 0.9176, 0.9098, 0.8980],
[0.9176, 0.9176, 0.9176, ..., 0.9176, 0.9098, 0.8980],
[0.9216, 0.9216, 0.9216, ..., 0.9137, 0.9098, 0.9020],
...,
[0.9294, 0.9294, 0.9255, ..., 0.5529, 0.9216, 0.8941],
[0.9294, 0.9294, 0.9255, ..., 0.8863, 1.0000, 0.9137],
[0.9294, 0.9294, 0.9255, ..., 0.9490, 0.9804, 0.9137]]])
Process finished with exit code 0
'''
通过查看ToTensor的用法可知ToTensor就是将PIL Image or numpy.ndarray转化为tensor格式
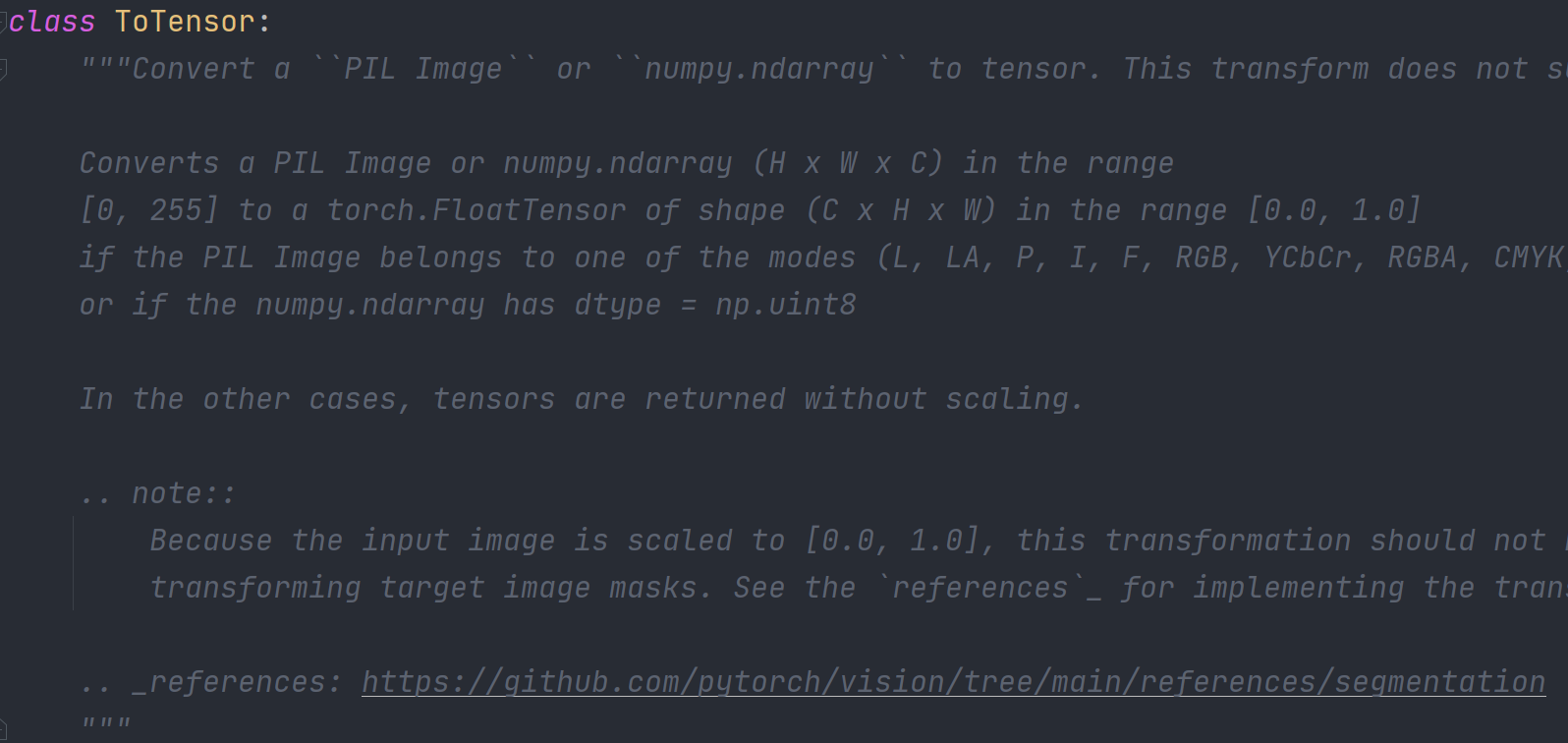
常见的Transforms

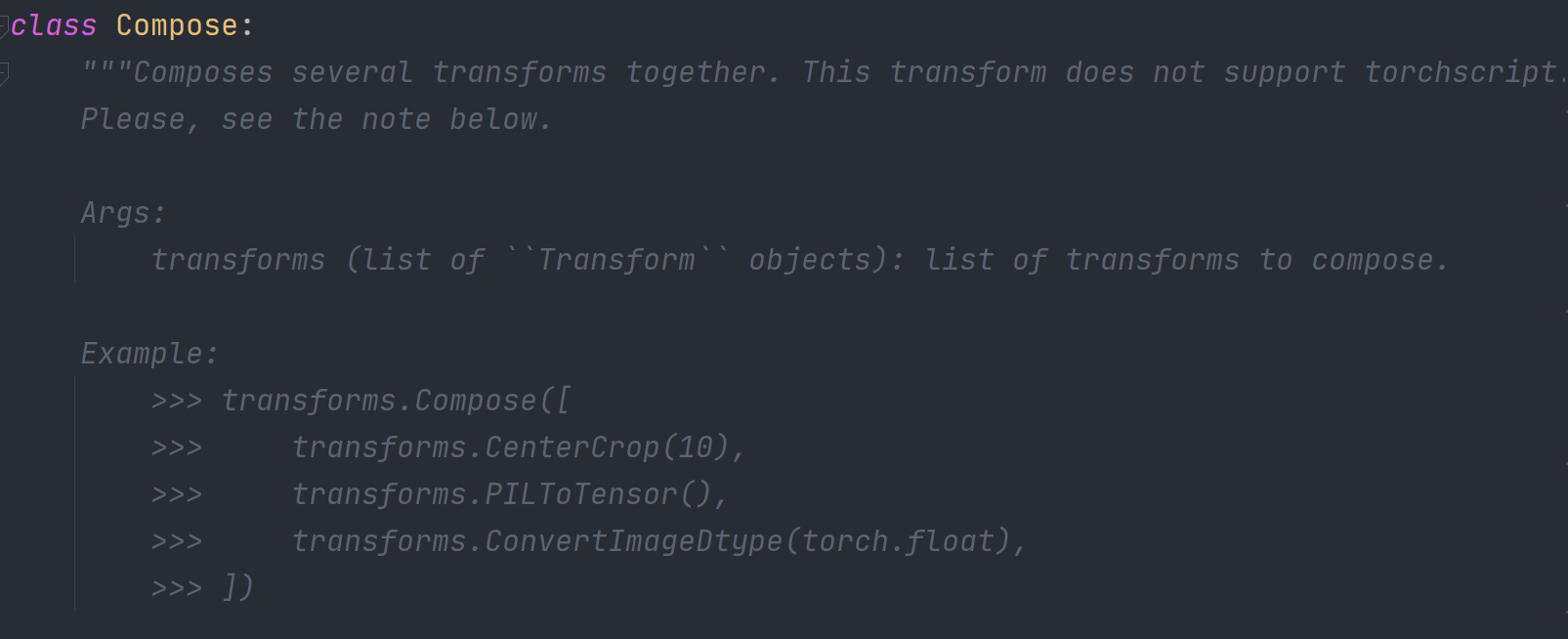
Compose()用来把多个transforms类型变换链接到一起的工具。
用法:Compose([transforms参数1,transforms参数2,...])
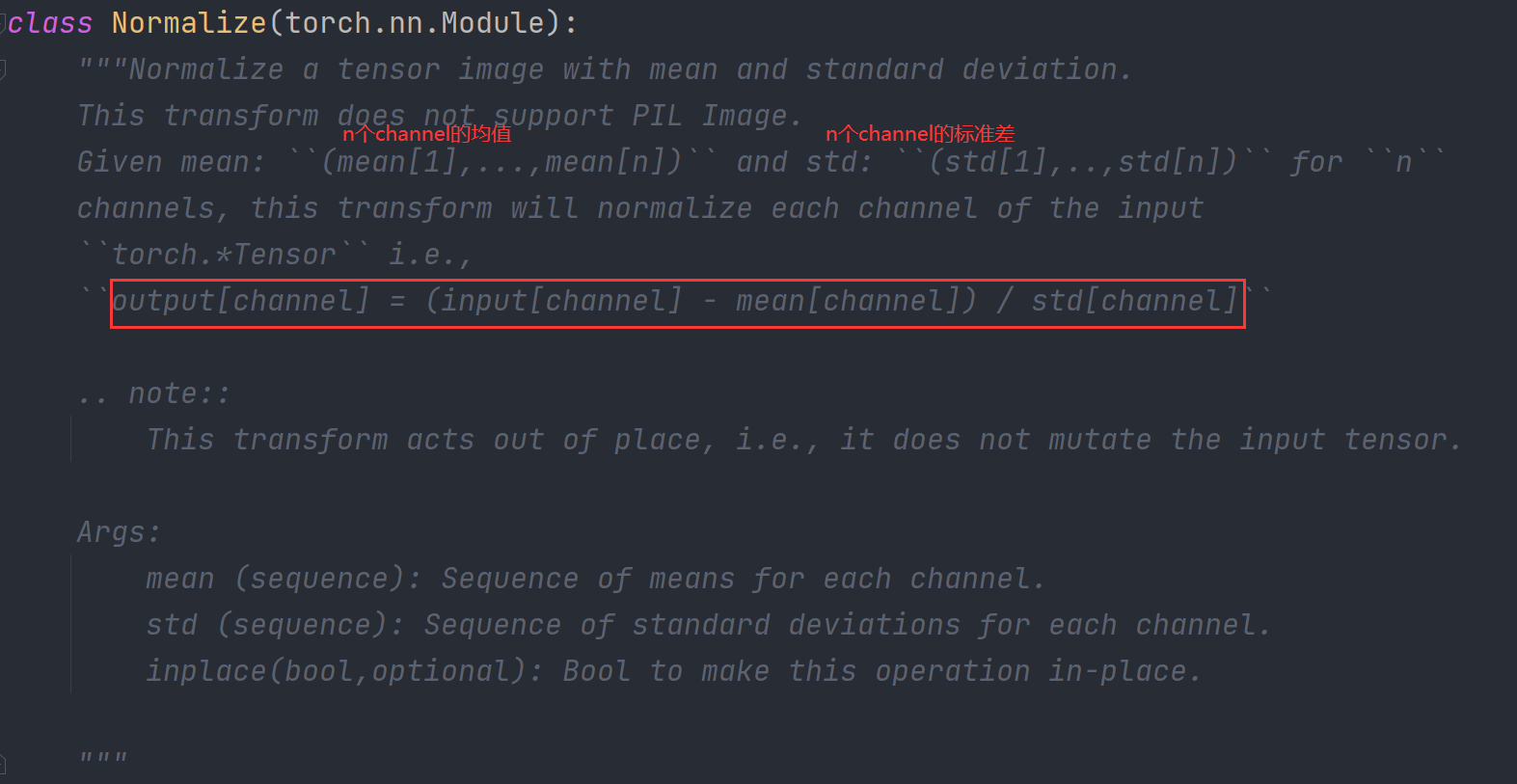
Normalize()归一化
output[channel] = (input[channel] - mean[channel]) / std[channel]
(
i
n
p
u
t
−
0.5
)
/
0.5
=
2
∗
i
n
p
u
t
−
1
(input-0.5)/0.5 = 2*input - 1
(input−0.5)/0.5=2∗input−1,因此通过Normalize()可以将
i
n
p
u
t
[
0
,
1
]
input[0,1]
input[0,1]转化为
r
e
s
u
l
t
[
−
1
,
1
]
result[-1,1]
result[−1,1]
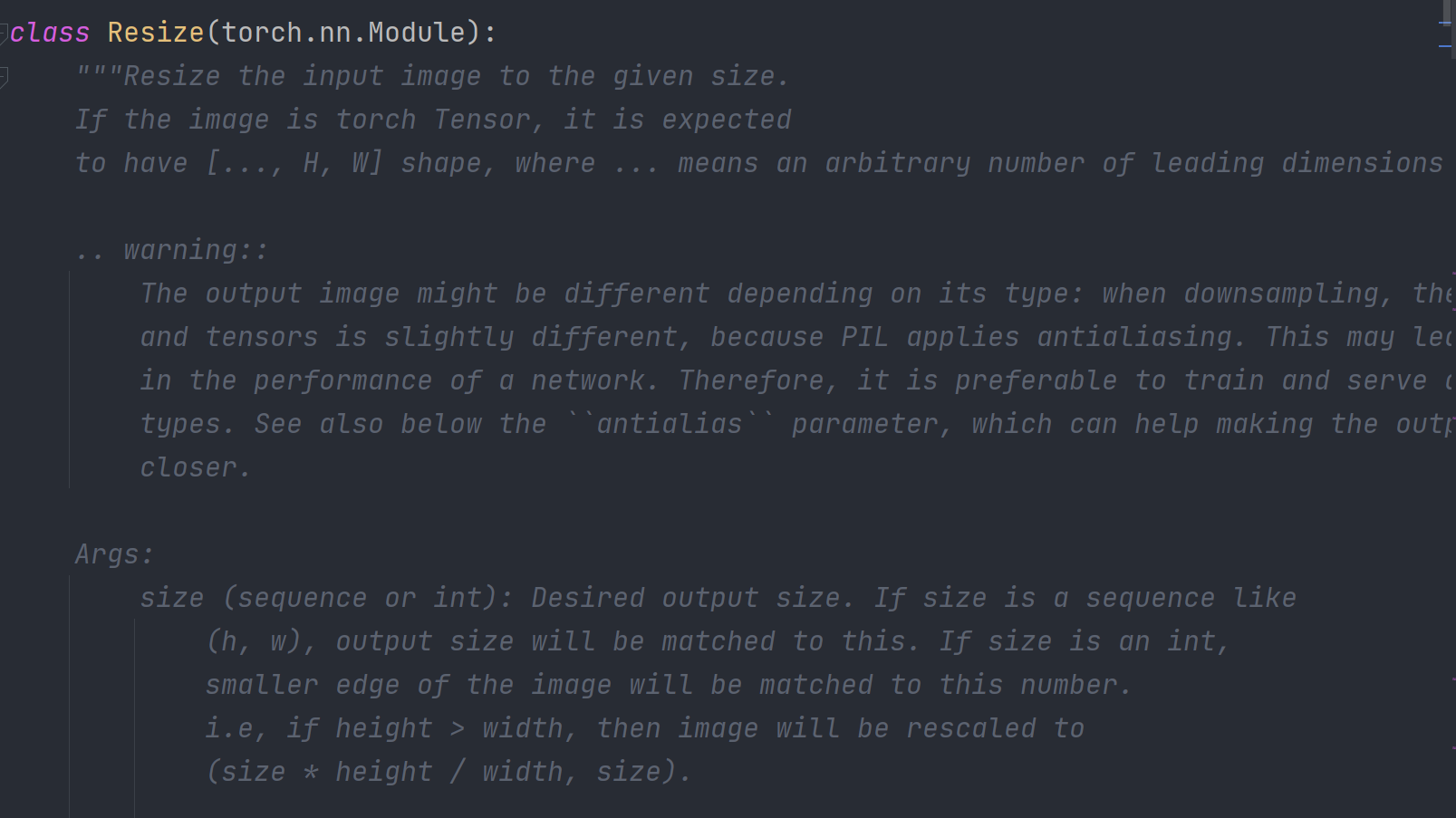
Resize()图像变换,当输入两个参数时,分别定义图像的高度和宽度;当输入一个参数时,设定图像较小的边为该数值并进行等比缩放
RandomCrop()随机裁剪,当输入两个参数时,分别定义裁剪图像的高度和宽度;当输入一个参数时,裁剪一个正方形
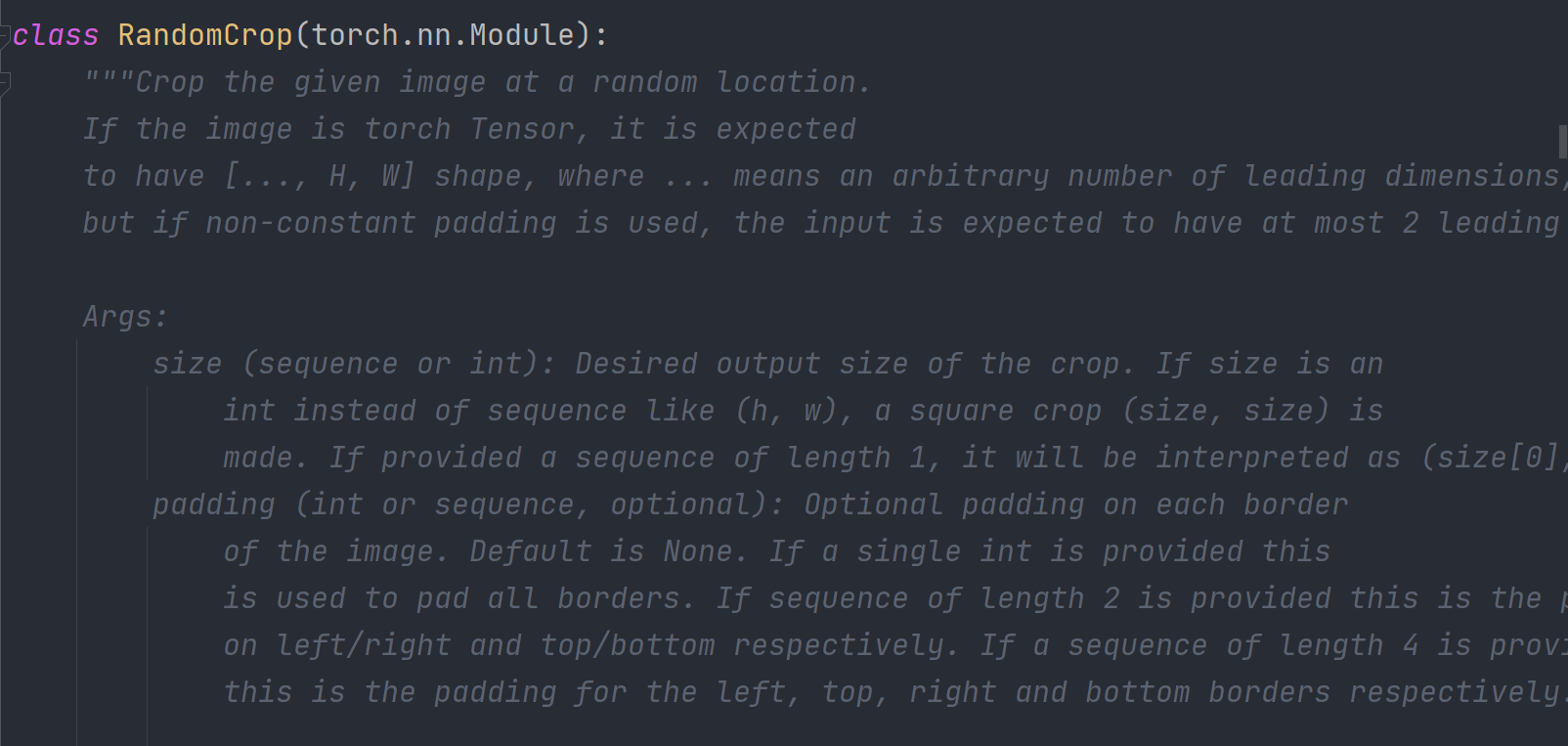
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
writer = SummaryWriter("logs")
img = Image.open("data/train/ants_image/0013035.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize 归一化
print(img_tensor[0][0][0]) # 处理前,看看第一个位置的数值
trans_norm = transforms.Normalize([1, 2, 2], [2, 1, 3]) # 因为图像时三个channel的,所以,均值[1, 2, 2]和标准差 [2, 1, 3] 都是三维的
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0]) # 处理后,再看第一个位置的数值,这是为了验证才这样写的
writer.add_image("Normalize", img_norm, 3)
# Resize 输入是 PIL 类型才行
print(img.size)
trans_resize = transforms.Resize((128, 128))
# img PIL -> resiz -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize, 0)
print(img_resize)
# Compose -resize -2
trans_resize_2 = transforms.Resize(128)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([
trans_resize_2, trans_totensor
])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
# RandomCrop
trans_random = transforms.RandomCrop(200, 200)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
writer.close()
-
裁剪(Crop)
- 中心裁剪:
transforms.CenterCrop - 随机裁剪:
transforms.RandomCrop - 随机长宽比裁剪:
transforms.RandomResizedCrop - 上下左右中心裁剪:
transforms.FiveCrop - 上下左右中心裁剪后翻转,
transforms.TenCrop
- 中心裁剪:
-
翻转和旋转(Flip and Rotation)
- 依概率p水平翻转:
transforms.RandomHorizontalFlip(p=0.5) - 依概率p垂直翻转:
transforms.RandomVerticalFlip(p=0.5) - 随机旋转:
transforms.RandomRotation
- 依概率p水平翻转:
-
图像变换(resize)
- 图像变换:
transforms.Resize - 标准化:
transforms.Normalize - 转为tensor,并归一化至[0-1]:
transforms.ToTensor - 填充:
transforms.Pad - 修改亮度、对比度和饱和度:
transforms.ColorJitter - 转灰度图:
transforms.Grayscale - 线性变换:
transforms.LinearTransformation - 仿射变换:
transforms.RandomAffine - 依概率p转为灰度图:
transforms.RandomGrayscale - 将数据转换为PILImage:
transforms.ToPILImage - 自定义lambad进行转换:
transforms.Lambda
- 图像变换:
-
对transforms操作,使数据增强更灵活
- 从给定的一系列transforms中选一个进行操作:
transforms.RandomChoice(transforms) - 给一个transform加上概率,依概率进行操作:
transforms.RandomApply(transforms, p=0.5) - 将transforms中的操作随机打乱:
transforms.RandomOrder
- 从给定的一系列transforms中选一个进行操作:
torchvision中的数据集使用
官网
其中官网文档中为我们提供了一些数据集
以torchvision中的CIFAR10为例
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
# 后面要对数据做一个预处理,做一次transform的变化,这里的意思是,先建立一个工具,在后面的dataset当中,加入这个工具,直接就可以做预处理了,本例是将原始数据转为tensor类型
# CIFAR数据集中的数据,类型是PIL,需要转为tensor,才能进行处理
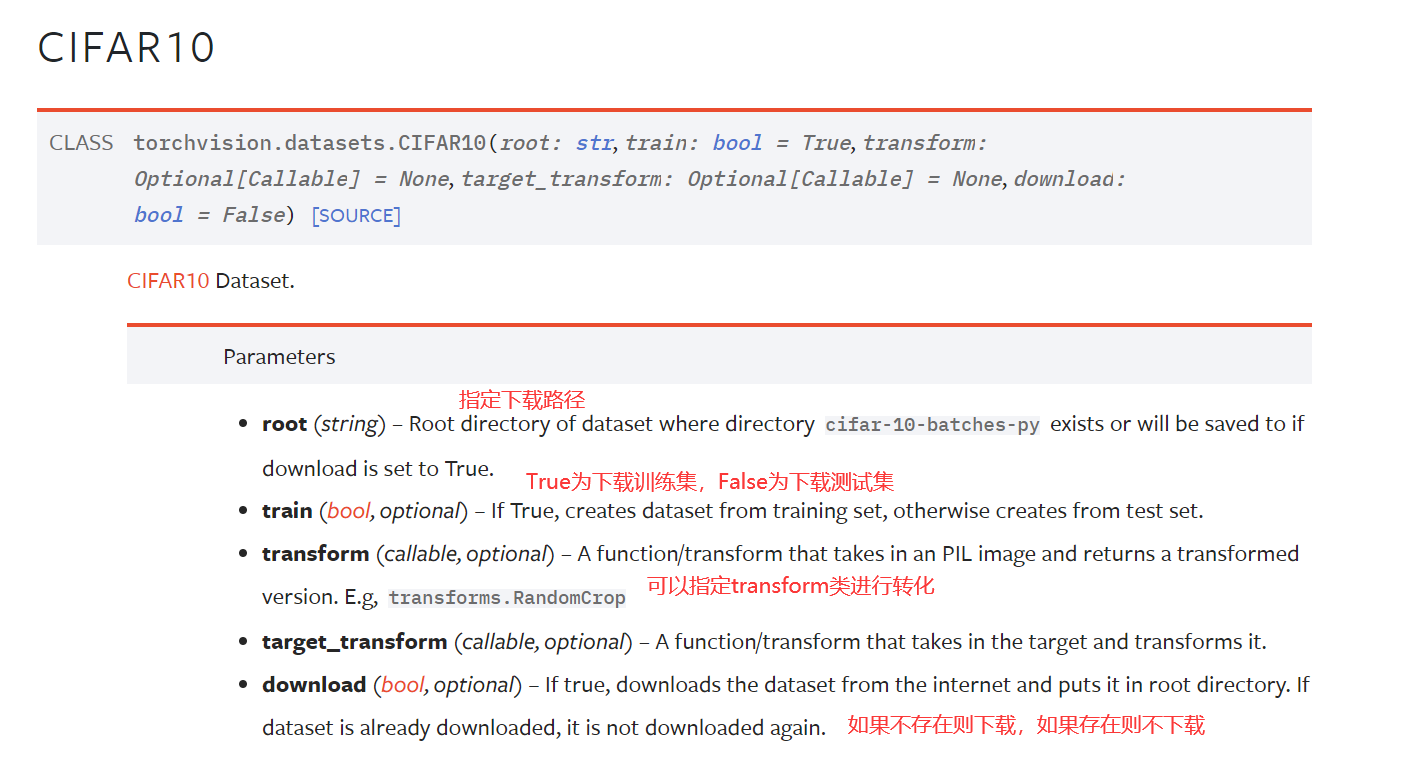
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
print(test_set[0])
# (<PIL.Image.Image image mode=RGB size=32x32 at 0x1E98CF496D8>, 3)
print(test_set.classes)
#['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
img, target = test_set[0]
print(img)
# <PIL.Image.Image image mode=RGB size=32x32 at 0x1E98CF49518>
print(target)
# 3
print(test_set.classes[target])
# cat
img.show()
print(test_set[0])
'''
(tensor([[[0.6196, 0.6235, 0.6471, ..., 0.5373, 0.4941, 0.4549],
[0.5961, 0.5922, 0.6235, ..., 0.5333, 0.4902, 0.4667],
[0.5922, 0.5922, 0.6196, ..., 0.5451, 0.5098, 0.4706],
...,
[0.2667, 0.1647, 0.1216, ..., 0.1490, 0.0510, 0.1569],
[0.2392, 0.1922, 0.1373, ..., 0.1020, 0.1137, 0.0784],
[0.2118, 0.2196, 0.1765, ..., 0.0941, 0.1333, 0.0824]],
[[0.4392, 0.4353, 0.4549, ..., 0.3725, 0.3569, 0.3333],
[0.4392, 0.4314, 0.4471, ..., 0.3725, 0.3569, 0.3451],
[0.4314, 0.4275, 0.4353, ..., 0.3843, 0.3725, 0.3490],
...,
[0.4863, 0.3922, 0.3451, ..., 0.3804, 0.2510, 0.3333],
[0.4549, 0.4000, 0.3333, ..., 0.3216, 0.3216, 0.2510],
[0.4196, 0.4118, 0.3490, ..., 0.3020, 0.3294, 0.2627]],
[[0.1922, 0.1843, 0.2000, ..., 0.1412, 0.1412, 0.1294],
[0.2000, 0.1569, 0.1765, ..., 0.1216, 0.1255, 0.1333],
[0.1843, 0.1294, 0.1412, ..., 0.1333, 0.1333, 0.1294],
...,
[0.6941, 0.5804, 0.5373, ..., 0.5725, 0.4235, 0.4980],
[0.6588, 0.5804, 0.5176, ..., 0.5098, 0.4941, 0.4196],
[0.6275, 0.5843, 0.5176, ..., 0.4863, 0.5059, 0.4314]]]), 3)
Process finished with exit code 0
'''
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()

DataLoader的使用
DataLoader本质上就是一个iterable(跟python的内置类型list等一样),并利用多进程来加速batch data的处理,使用yield来使用有限的内存
官方文档
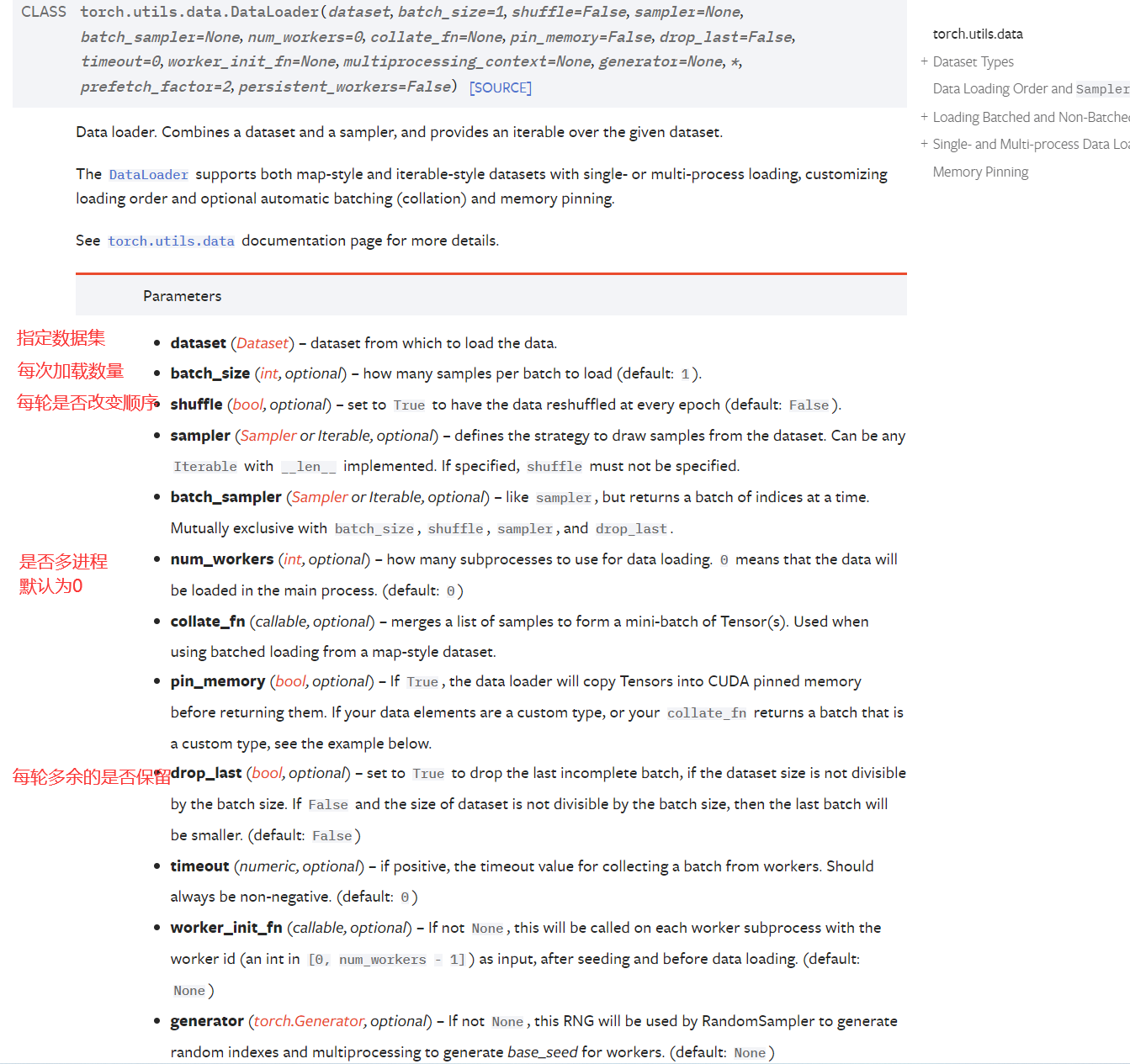
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
# torch.Size([3, 32, 32]) 单张图片的尺寸和通道数
print(target)
# 3
writer = SummaryWriter("dataloader")
# 测试数据集上所有的图片 imgs 是复数
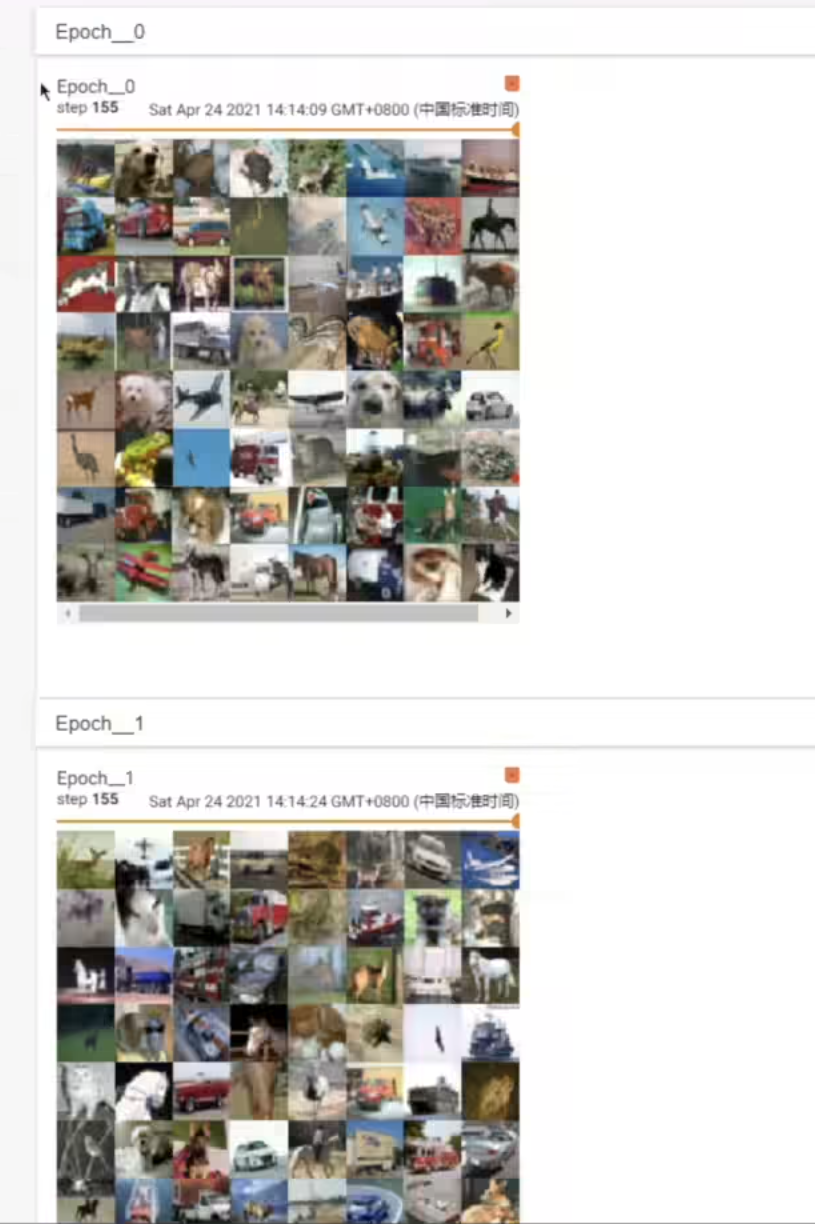
for epoch in range(2): # 进行两轮,上面的 shuffle,是对这个位置有影响,而不是 for data 那个循环有影响
step = 0
for data in test_loader: # 这个loader,返回的内容,就已经是包含了 img 和 target 两个值了,这个在 cifar 数据集的 getitem 函数里,写了
imgs, targets = data
print(imgs.shape)
# torch.Size([4, 3, 32, 32]) 这个输出的结果,其中的 4 ,是 batch_size 设定的值, 后面的 3, 32, 32 是单张图片的尺寸和通道数
print(targets)
# tensor([2, 8, 0, 2]) 这4个数字,是对 target 的打包,是随机的,数值代表所在的分类;debug一下,可以看到 sampler中的取值方式,是 RandomSampler
# 随机从 Data 中,抓取 4 个数据
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()















 9583
9583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









