







吧
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本文主要记录了Glove嵌入的学习笔记,如有错误还请不吝赐教!
提示:以下是本篇文章正文内容,下面案例可供参考
一、Glove 词嵌入
上下文窗口内的词共现可以携带丰富的语义信息。可以预先计算此类共现的全局语料库统计数据:这可以提高训练效率。
让我们先回顾之前的跳元Skip-Gram模型,但考虑使用全局语料库统计来解释它。
1.1 带全局语料统计的跳元模型
我们用
q
i
j
qij
qij 来表示词Wj的条件概率:
P(wj | wi)
在跳元模型中,给定词wi,有
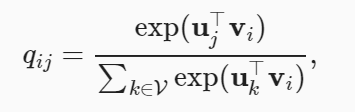
vi,ui 分别表示词wi作为中心词和上下文词。
考虑wi可能在语料中出现多次,于是我们考虑使用重数。
举例说明:假设词 wi 在语料库中出现两次,并且在两个上下文窗口中以 wi 为其中心词的上下文词索引是 k,j,m,k 和 k,l,k,j 。因此,多重集 Ci={j,j,k,k,k,k,l,m} ,其中元素 j,k,l,m 的重数分别为2、4、1、1。
我们将全局语料统计加入到跳元模型中:
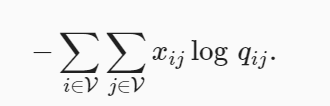
我们用 xi 表示上下文窗口中的所有上下文词的数量,其中 wi 作为它们的中心词出现。设 pij 为用于生成上下文词 wj 的条件概率 xij/xi :
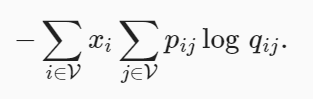
虽然我们一般使用交叉熵损失函数通常用于测量概率分布之间的距离,但在这里可能不是一个好的选择。
首先:正如之前所提到的,规范化qij的代价在于整个词表求和。其次,来自大型语料库的大量罕见事件往往被交叉熵损失建模,从而赋予过多的权重。
1.2 GloVe 模型
由上述,GloVe模型基于平方损失对跳元模型进行了三个修改。
1.使用变量p′ij=xij 和q′ij=exp(u⊤j vi) 而非概率分布,并取两者的对数。所以平方损失项是
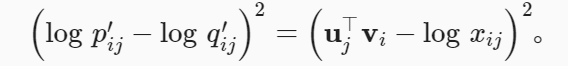 2. 为每个词wi 添加两个标量模型参数:中心词偏置bi和上下文偏置ci
2. 为每个词wi 添加两个标量模型参数:中心词偏置bi和上下文偏置ci
3.用权重函数 h(xij) 替换每个损失项的权重,其中 h(x) 在 [0,1] 的间隔内递增
由此得到相应的损失函数:
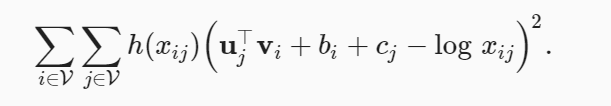
应该强调的是,当词 wi 出现在词 wj 的上下文窗口时,词 wj 也出现在词 wi 的上下文窗口。因此, xij=xji 。与拟合非对称条件概率 pij 的word2vec不同,GloVe拟合对称概率 logxij 。因此,在GloVe模型中,任意词的中心词向量和上下文词向量在数学上是等价的。但在实际应用中,由于初始值不同,同一个词经过训练后,在这两个向量中可能得到不同的值:GloVe将它们相加作为输出向量。
二、fastText
在不同语言中,每个词都有其对应的变形形式。比如“helps”、“helped”和“helping”等单词都是同一个词“help”的变形形式。在上述的word2vec和GloVe都没有对词的内部结构进行探讨。
2.1 fastText 模型
考虑word2vec中的跳元模型和连续词袋模型,我们发现同一个词的不同变形形式直接由不同的向量表示,不需要共享参数。
而为了使用单词的形态信息,fastText模型提出了一种子词嵌入方法,其中子词是一个字符 n -gram,每个中心词都由其子词级向量之和表示。
举例说明:
在这里我们以where单词为例:
首先,在词的开头和末尾添加特殊字符“<”和“>”,以将前缀和后缀与其他子词区分开来。 然后,从词中提取字符 n -gram。 例如,值 n=3 时,我们将获得长度为3的所有子词: “<wh”、“whe”、“her”、“ere”、“re>”和特殊子词“”。
在fastText中,对于任意词 w ,用 Gw 表示其长度在3和6之间的所有子词与其特殊子词的并集。词表是所有词的子词的集合。假设 zg 是词典中的子词 g 的向量,则跳元模型中作为中心词的词 w 的向量 vw 是其子词向量的和:
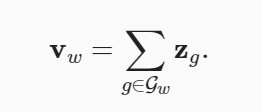
fastText的其余部分与跳元模型相同。与跳元模型相比,fastText的词量更大,模型参数也更多。此外,为了计算一个词的表示,它的所有子词向量都必须求和,这导致了更高的计算复杂度。然而,由于具有相似结构的词之间共享来自子词的参数,罕见词甚至词表外的词在fastText中可能获得更好的向量表示。(也就是说由相似结构的单词之间参数共享)
2.2 字节对编码(Byte Pair Encoding)
在fastText中,所有提取的子词都必须是指定的长度,例如3到6,因此词表的大小不能预定义。为了在固定大小的词表中允许可变长度的子词,我们可以应用一种称为字节对编码(BPE)的压缩算法来提取子词。
字节对编码执行训练数据集的统计分析,以发现单词内的公共符号,诸如任意长度的连续字符。从长度为1的符号开始,字节对编码迭代地合并最频繁的连续符号对以产生新的更长的符号。(字节对编码及其变体已经应用于GPT-2和RoBERTa等自然语言处理预训练模型中的输入表征)
举例的示例如下:
我们给定初始的符号词表,其包含了所有英文的小写字符、特殊的词尾符号‘_’以及特殊的未知符号‘[UNK]’
symbols = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z',
'_', '[UNK]']
我们对词典token_freqs的键迭代地执行字节对编码算法。在第一次迭代中,最频繁的连续符号对是’t’和’a’,因此字节对编码将它们合并以产生新符号’ta’。在第二次迭代中,字节对编码继续合并’ta’和’l’以产生另一个新符号’tal’。将迭代生成的新的词汇放入到symbol中。
对于上述,我们可以直观的理解为它贪心的对词语进行相应的子词分割。找到频率最高的公共子词,而不是每个词都进行相应的n-gram的分割。
总结:
1.fastText模型提出了一种子词嵌入方法:基于word2vec中的跳元模型,它将中心词表示为其子词向量之和。
2.字节对编码执行训练数据集的统计分析,以发现词内的公共符号。作为一种贪心方法,字节对编码迭代地合并最频繁的连续符号对。
3.子词嵌入可以提高稀有词和词典外词的表示质量。














 709
709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









