







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
本篇论文主要记录了对抗生成网络训练难的问题和解决方式。
本文主要参考了两位大佬的博客 [WGAN (原理解析)](https://www.cnblogs.com/Allen-rg/p/10305125.html) [生成对抗网络——原理解释和数学推导](https://alberthg.github.io/2018/05/05/introduction-gan/)
提示:以下是本篇文章正文内容,下面案例可供参考
一、GAN训练
在讨论GAN的难训练问题前,我们先回顾一下GAN的算法步骤:
具体的算法流程如下:

对于生成器的损失函数,作者Goodfellow后来又提出了一个改进的损失函数:
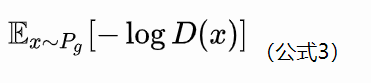
但是即便如此,GAN的训练依旧存在如下问题:
1.GAN训练不稳定,训练过程中很难收敛。(主要是优化目标JS散度的问题)
2.GAN训练中会产生collapse mode 的问题。
1.1 训练不稳定
在实际应用中我们会发现, D 的 Loss Function 非常容易变成 0 ,而且在后面的训练中也已知保持着 0,很难发生改变。这个现象是为什么呢?其实这个道理很简单。虽然说 JSD 能够衡量两个分布之间的距离,但实际上有两种情况可能会导致 JSD 永远判定两个分布距离“无穷大”( JSD(Pdata(x)||PG(x))=log2 )。从而使得 Loss Function 永远是 0:
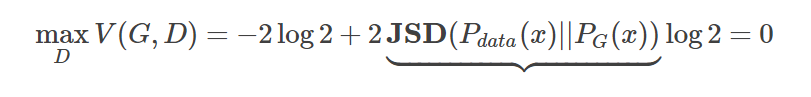
第一种情况: 就是判别器 D 太“强”了导致产生了过拟合。
当判别器足够“强”的时候,就很有可能找到一条分界线强行将两类样本分开,从而让两类样本之间被认为完全不存在重叠。我们可以尝试传统的正则化方法(regularization等),也可以减少模型的参数让它变得弱一些。但是我们训练的目的就是要找到一个“很强”的判别器,我们在实际操作中是很难界定到底要将判别器调整到什么水平才能满足我们的需要:既不会太强,也不会太弱。还有一点就是我们之前曾经认为这个判别器应该能够测量 JSD,但它能测量 JSD 的前提就是它必须非常强,能够拟合任何数据。这就跟我们“不想让它太强”的想法有矛盾了,所以实际操作中用 regularization 等方法很难做到好的效果。
第二种情况: 就是数据本身的特性
一般来说,生成器产生的数据都是一个映射到高维空间的低维流型。而低维流型之间本身就“不是那么容易”产生重叠的。也就是说,想要让两个概率分布“碰”到一起的概率并不是很高,他们之间的 “Divergence” 永远是 log2。这会导致整个训练过程中,JSD 作为距离评判标准无法为训练提供指导。
解决办法有两种
1.给数据加噪声,让生成器和真实数据分布更容易重叠在一起。但是加入噪声势必会影响我们生产数据的质量,比较简单的操作方法是让噪声的幅度随着时间缩小。(注意:加噪后的JS散度受到噪声方差的影响,随着噪声的退火,前后面的数值就没法比较了,所以它不能成为P_r和P_g距离的本质性衡量。
2.既然JSD 效果不好,我们就更换一个Loss function,使得哪怕两个分布一直毫无重叠,但是都能提供一个不同的连续的的“距离的度量” —— WGAN。
1.2 Mode Collapse
训练中可能遇到的另一个问题:所有的输出都一样!这个现象被称为 Mode Collapse。这个现象产生的原因可能是由于真实数据在空间中很多地方都有一个较大的概率值,但是我们的生成模型没有直接学习到真实分布的特性。为了保证最小化损失,它会宁可永远输出一样但是肯定正确的输出,也不愿意尝试其他不同但可能错误的输出。也就是说,我们的生成器有时可能无法兼顾数据分布的所有内部模式,只会保守地挑选出一个肯定正确的模式。
补充:对于上述两个结论更为数学化的证明可见WGAN (原理解析)
二、WGAN
2.1 Wasserstein距离
Wasserstein距离又叫Earth-Mover(EM)距离,定义如下:
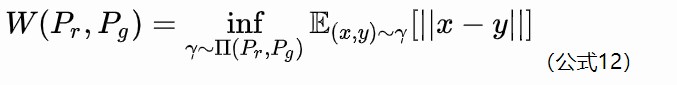
具体的数学介绍还是详见WGAN (原理解析)
这里只讲一下直观的含义:
直观上可以把
E
(
x
,
y
)
∼
γ
[
∣
∣
x
−
y
∣
∣
]
理
\mathbb{E}_{(x, y) \sim \gamma} [||x - y||]理
E(x,y)∼γ[∣∣x−y∣∣]理解为在
γ
\gamma
γ这个“路径规划”下把
P
r
P_r
Pr这堆“沙土”挪到
P
g
P_g
Pg“位置”所需的“消耗”,而W(
P
r
P_r
Pr,
P
g
P_g
Pg)就是“最优路径规划”下的“最小消耗”,所以才叫Earth-Mover(推土机)距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
我们举个例子:
考虑如下二维空间中的两个分布
P
1
P_1
P1和
P
2
P_2
P2,
P
1
P_1
P1在线段AB上均匀分布,
P
2
P_2
P2在线段CD上均匀分布,通过控制参数
θ
\theta
θ可以控制着两个分布的距离远近。


KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的,如果我们要用梯度下降法优化\theta这个参数,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则KL和JS既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。
2.2 WGAN
由上述,我们可知,如果能够将Wasserstein定义为生成器的loss,不就可以产生有意义的梯度来更新生成器,使得生成分布被拉向真实分布吗?
但是对于Wasserstein距离定义中的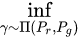
没法直接求解,作者通过证明,将Wasserstein公式改为了如下形式:
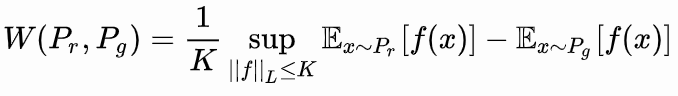
先介绍Lipschitz连续这个概念:
Lipschitz连续。它其实就是在一个连续函数
f
f
f上面额外施加了一个限制,要求存在一个常数
K
≥
0
K\geq 0
K≥0使得定义域内的任意两个元素
x
1
x_1
x1和
x
2
x_2
x2都满足
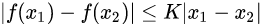
此时称函数f的Lipschitz常数为K.
我们直观的来理解上述概念:
比如说f的定义域是实数集合,那上面的要求就等价于f的导函数绝对值不超过
K
K
K。再比如说
log
(
x
)
\log (x)
log(x)就不是Lipschitz连续,因为它的导函数没有上界。Lipschitz连续条件限制了一个连续函数的最大局部变动幅度。
作者改动后的Wasserstein距离公式的意思就是:在要求函数f的Lipschitz常数
∣
∣
f
∣
∣
L
||f||_L
∣∣f∣∣L不超过
K
K
K的条件下,对所有可能满足条件的f取到
E
x
∼
P
r
[
f
(
x
)
]
−
E
x
∼
P
g
[
f
(
x
)
]
\mathbb{E}_{x \sim P_r} [f(x)] - \mathbb{E}_{x \sim P_g} [f(x)]
Ex∼Pr[f(x)]−Ex∼Pg[f(x)]的上界,然后再除以
K
K
K。特别地,我们可以用一组参数
w
w
w来定义一系列可能的函数
f
w
f_w
fw,此时求解公式13可以近似变成求解如下形式
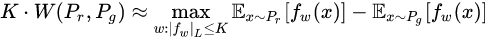
这里就可以使用神经网络来拟合
f
w
f_w
fw,
最后,还不能忘了满足公式14中
∣
∣
f
w
∣
∣
L
≤
K
||f_w||_L \leq K
∣∣fw∣∣L≤K这个限制。我们其实不关心具体的
K
K
K是多少,只要它不是正无穷就行,因为它只是会使得梯度变大
K
K
K倍,并不会影响梯度的方向。所以作者采取了一个非常简单的做法,就是限制神经网络
f
θ
f_\theta
fθ的所有参数
w
i
w_i
wi的不超过某个范围[-c, c],此时关于输入样本x的导数
∂
f
w
∂
x
\frac{\partial f_w}{\partial x}
∂x∂fw也不会超过某个范围,所以一定存在某个不知道的常数
K
K
K使得
f
w
f_w
fw的局部变动幅度不会超过它,Lipschitz连续条件得以满足。具体在算法实现中,只需要每次更新完
w
w
w后把它clip回这个范围就可以了。
综上:
我们可以构造一个含参数
w
w
w、最后一层不是非线性激活层的判别器网络
f
w
f_w
fw,在限制
w
w
w不超过某个范围的条件下,使得
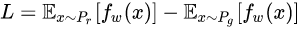
尽可能取到最大,此时L就会近似真实分布与生成分布之间的Wasserstein距离(忽略常数倍数K)。注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器f_w做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
接下来生成器要近似地最小化Wasserstein距离,可以最小化L,由于Wasserstein距离的优良性质,我们不需要担心生成器梯度消失的问题。再考虑到L的第一项与生成器无关,就得到了WGAN的两个loss。
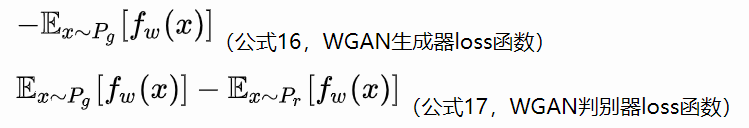
由此,我们得到了WGAN的具体算法:

补充:
WGAN与原始GAN的区别:
1、判别器最后一层去掉Sigmoid
2、生成器和判别器的loss不去log
3、每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
4、不要使用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行。(RMSProp适合梯度不稳定的情况。)
三、代码实现
Discriminator:
class Discriminator_EM(nn.Module):
"""
WGAN Discriminator
"""
def __init__(self, in_channel: int, last_out_channel: int, stride: List[int] = [2, 2, 2, 2],
padding: List[int] = [2, 2, 2, 2], kernel_size: List[int] = [5, 5, 5, 5]):
"""
initialization Discriminator
:param in_channel:
:param last_out_channel:
:param stride:
:param padding:
:param kernel_size:
"""
super(Discriminator_EM, self).__init__()
self.main = self._make_layer(in_channel, last_out_channel, stride, padding, kernel_size)
self.fc1 = nn.Linear(4 * 4 * 512, 1)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, 0.0, 0.02)
if isinstance(m, nn.BatchNorm2d):
nn.init.normal_(m.weight, 1.0, 0.02)
def _make_layer(self, in_channel, last_out_channel, stride: List[int], padding: List[int], kernel_size: List[int]):
"""
make the main layer
:param in_channel:
:param last_out_channel:
:param stride:
:param padding:
:param kernel_size:
:return:
"""
layers = []
for i in range(len(stride) - 1):
out_channel = max(in_channel * 2, 64)
layer = [
nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size[i], padding=padding[i], stride=stride[i],
bias=False),
nn.BatchNorm2d(out_channel),
nn.LeakyReLU(0.2, inplace=True),
]
in_channel = out_channel
layers.extend(layer)
layers.extend(
[nn.Conv2d(in_channel, last_out_channel, kernel_size=kernel_size[i], padding=padding[i], stride=stride[i]),
])
return nn.Sequential(*layers)
def forward(self, inputs: Tensor) -> Tensor:
out = self.main(inputs)
out = torch.flatten(out, start_dim=1)
out=self.fc1(out)
return out
train:
def train_EM(epochs:int=10,lr=2e-4,clamp_num:float=0.01):
real_label = 1
fake_label = 0
device = "cuda:0" if torch.cuda.is_available() else "cpu"
my_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
one = torch.FloatTensor([1]).to(device)
mone = -1 * one
mone.to(device)
dataset = MyDataset(transform=my_transform)
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
NetD = Discriminator_EM(3, last_out_channel=512).to(device)
NetG = Generator_EM(100, 3).to(device)
# loss_func = nn.BCELoss()
optimizer_D = torch.optim.RMSprop(NetD.parameters(), lr=lr)
optimizer_G = torch.optim.RMSprop(NetG.parameters(), lr=lr)
for epoch in range(epochs):
train_bar = tqdm(train_loader)
for idx,data in enumerate(train_bar):
data = Variable(data)
b_size = data.shape[0]
# 分两步训练 是 ganhacks的建议
for parm in NetD.parameters():
parm.data.clamp_(-clamp_num, clamp_num)
NetD.zero_grad()
output_real= NetD(data.to(device)).view(-1).to(device)
d_loss_real = output_real.mean(0).view(1).to(device)
d_loss_real.backward(one)
noise = torch.randn(b_size, 100).to(device)
noise=Variable(noise).to(device)
fake = NetG(noise).to(device)
output_fake = NetD(fake.detach()).view(-1).to(device)
d_loss_fake=output_fake.mean(0).view(1).to(device)
d_loss_fake.backward(mone)
d_loss = d_loss_fake - d_loss_real
optimizer_D.step()
NetG.zero_grad()
output_g= NetD(fake).view(-1).to(device)
loss_g=output_g.mean(0).view(1).to(device)
loss_g.backward(one)
optimizer_G.step()
# if (idx+1)%5==0:
# NetG.zero_grad()
# output_g= NetD(fake).view(-1)
# output_g.backward()
# optimizer_G.step()
train_bar.desc = "train epoch[{}/{}] loss_D:{:.3f} loss_G:{:.3f}".format(epoch + 1,
epochs,
d_loss.item(), loss_g.item())
torch.save(NetD.state_dict(),"./weights/NetD"+str(epoch)+".pth")
torch.save(NetG.state_dict(),"./weights/NetG"+str(epoch)+".pth")















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









