






Deep Learning Algorithm for Cyberbullying Detection
网络欺凌检测的深度学习算法
Abstract
Abstract—Cyberbullying is a crime where one person becomes the target of harassment and hate. Many cyberbullying detection approaches have been introduced, however, they were largely based on textual and user features. Most of the research found in the literature aimed at improving detection through introducing new features. However, as the number of features increases, the feature extraction and selection phases have become harder. On the other hand, no study has examined the meaning of words and semantics in cyberbullying. In order to bridge this gap, we propose a novel algorithms CNN-CB that eliminate the need for feature engineering and produce better prediction than traditional cyberbullying detection approaches. The proposed algorithm adapts the concept of word embedding where similar words have similar embedding. Therefore, bullying tweets will have similar representations and this will advance the detection. CNN-CB is based on convolutional neural network (CNN) and incorporates semantics through the use of word embedding. Experiments showed that CNN-CB algorithm outperform traditional content-based cyberbullying detection with an accuracy of 95%.
摘要:网络欺凌是一种犯罪,使一个人成为骚扰和仇恨的目标。已经引入了许多网络欺凌检测方法,但是,它们主要基于文本和用户特征。文献中发现的大多数研究旨在通过引入新特征来改进检测。然而,随着特征数量的增加,特征提取和选择阶段变得更加困难。另一方面,没有研究检查网络欺凌中单词和语义的含义。为了弥合这一差距,我们提出了一种新的算法 CNN-CB,它消除了对特征工程的需求,并且比传统的网络欺凌检测方法产生了更好的预测。所提出的算法适应了词嵌入的概念,其中相似的词具有相似的嵌入。因此,欺凌推文将具有相似的表示,这将促进检测。 CNN-CB 基于卷积神经网络 (CNN),并通过使用词嵌入来结合语义。实验表明,CNN-CB 算法优于传统的基于内容的网络欺凌检测,准确率为 95%。
Keywords—Cyberbullying; convolutional neural network; CNN; detection; deep learning
1、Introduction
With the proliferation of the internet and its anonymity nature, many ethical issues have emerged. Cyberbullying is among the most widely acknowledged problems by individuals and communities. It is defined as any violent, intentional action conducted by individuals or groups, using online channels repeatedly against a victim who does not have the potential to react [1]. Even though bullying has always been a critical issue and received much attention; the internet along with social media has only made the issue more critical and wide spread. This is because they open doors for predators and give them a 24/7 access to victims from all ages and backgrounds while keeping their identities anonymous [2]. For all the danger imposed by cyberbullying on victims and communities, this field of study is maturing, with a wealth of research and findings evolving every day. The vast range of existing cyberbullying studies are spanning fields like psychology, linguistics and computer science.
随着互联网的普及及其匿名性,出现了许多伦理问题。网络欺凌是个人和社区最广泛承认的问题之一。它被定义为由个人或团体实施的任何暴力、故意行为,反复使用在线渠道针对没有反应能力的受害者 [1]。尽管欺凌一直是一个关键问题并受到很多关注;互联网和社交媒体只会让这个问题变得更加重要和广泛传播。这是因为他们为掠食者敞开大门,让他们可以 24/7 全天候访问来自所有年龄和背景的受害者,同时保持他们的身份匿名 [2]。尽管网络欺凌给受害者和社区带来了所有危险,但这一研究领域正在成熟,每天都有大量的研究和发现在发展。现有的大量网络欺凌研究涉及心理学、语言学和计算机科学等领域。
Psychologists recognized cyberbullying as being a phenomenon closely related to the well being of individuals. A study found in [3] where a total of 7000 students were examined, concluded that bullying contributes to higher levels of loneliness and lower levels of social well-being . Many psychologists were asked in [4] about the appropriate actions that need to be taken in response to the growing number of cyberbullying incidents and they were in favour of the automatic monitoring of cyberbullying.
心理学家认为网络欺凌是一种与个人幸福密切相关的现象。在 [3] 中发现的一项研究对 7000 名学生进行了检查,得出的结论是,欺凌会导致更高水平的孤独感和更低水平的社会幸福感。许多心理学家在 [4] 中被问及需要采取的适当行动以应对日益增多的网络欺凌事件,他们赞成对网络欺凌进行自动监控。
Automatic monitoring of cyberbullying has gained considerable interest in the computer science field. The aim has been to develop efficient mechanisms that mitigate cyberbullying incidents. Most of the literature considered it to be a binary classification task, where text is classified as bullying or non bullying [5]. This is achieved through extracting features from text and feeding them to a classification algorithm. Many studies have addressed cyberbullying detection from different perspective, however, all falls under four features categories: content-based, userbased, emotion-based and social-network based features.
网络欺凌的自动监控在计算机科学领域引起了相当大的兴趣。目的是开发有效的机制来减轻网络欺凌事件。大多数文献认为它是一个二元分类任务,其中文本被分类为欺凌或非欺凌[5]。这是通过从文本中提取特征并将它们提供给分类算法来实现的。许多研究从不同的角度解决了网络欺凌检测,但是,它们都属于四个特征类别:基于内容、基于用户、基于情感和基于社交网络的特征。
Even though the state of art in cyberbullying detection is rapidly evolving, there are many problems that has arisen. A fundamental issue still present is that most research attempt to improve the detection process by suggesting new features. However, this approach might generate huge number of features that require careful feature extraction and selection phases which lead to computational overhead. Moreover, features are not always easy to be extracted. In fact, features can be easily fabricated [6]. Another drawback is that they fail to adapt to the changing nature of language. Offensive words that are considered features in most detection approaches are not static and change over time. As a result, detection approaches must not rely on static features rather on more automated mechanisms. Despite the success of current approaches, a core problem has not been addressed. The semantic of words, their meaning and relations have been overlooked.
尽管网络欺凌检测的最新技术正在迅速发展,但也出现了许多问题。仍然存在的一个基本问题是,大多数研究试图通过提出新特征来改进检测过程。然而,这种方法可能会产生大量特征,这些特征需要仔细的特征提取和选择阶段,从而导致计算开销。此外,特征并不总是容易提取的。事实上,特征可以很容易地制造[6]。另一个缺点是它们无法适应语言不断变化的性质。在大多数检测方法中被认为是特征的冒犯性词不是静态的,并且会随着时间而变化。因此,检测方法不能依赖静态特征,而是依赖更自动化的机制。尽管目前的方法取得了成功,但一个核心问题还没有得到解决。单词的语义,它们的含义和关系被忽略了。

In this article, we propose a convolutional neural network cyberbullying detection (CNN-CB) algorithm, which remedy the current unsolved problems. The primary goal is to develop an efficient detection approach capable of dealing with semantics and meaning and produces accurate result while keeping computational time and cost to a minimum. CNN-CB is based on deep learning which was on of MIT 10 Breakthrough Technologies Review in the year 2017 and 2013[7]. It is built upon the concept of convolutional neural network (CNN) which showed great success when applied to many classification tasks [8] [9] [10]. The most remarkable contribution is that CNN-CB is a cyberbullying detection algorithm that has shorten the classical detection workflow; it makes detections without any features. It transforms text into word embeddings and feeds them to a CNN. Previously, detection always started with feature extraction followed by, feature selection. Interestingly, CNN-CB has excluded these two steps and yet produced better result. Fig1 illustrates the traditional versus CNN-CB workflow.
在本文中,我们提出了一种卷积神经网络网络欺凌检测 (CNN-CB) 算法,该算法解决了当前未解决的问题。主要目标是开发一种能够处理语义和含义并产生准确结果的有效检测方法,同时将计算时间和成本降至最低。 CNN-CB 基于 2017 年和 2013 年的 MIT 10 Breakthrough Technologies Review [7] 中的深度学习。它建立在卷积神经网络 (CNN) 的概念之上,该概念在应用于许多分类任务时取得了巨大的成功 [8] [9] [10]。最显着的贡献是CNN-CB是一种网络欺凌检测算法,缩短了经典检测工作流程;它在没有任何特征的情况下进行检测。它将文本转换为词嵌入并将它们提供给 CNN。以前,检测总是从特征提取开始,然后是特征选择。有趣的是,CNN-CB 排除了这两个步骤,却产生了更好的结果。图 1 说明了传统算法与 CNN-CB 的工作流程。
This paper is organized as follows. Section II states the related work in cyberbullying. Then, section III describes CNN-CB in details. Section IV reports the experiments along with their results. Section V discusses the reported results. Finally, section VI concludes and summarizes this paper.
本文组织如下。第二节阐述了网络欺凌的相关工作。然后,第三节详细描述了 CNN-CB。第四节报告了实验及其结果。第五节讨论了报告的结果。最后,第六节总结了本文。
2、RELATED WORK(相关工作)
Cyberbullying detection has a rapidly growing literature, even though researches addressing bullying are traced back to early 2010. The rich literature in this field can be divided into three categories: content-based, user-based and network based detection. Each category will be covered briefly, and comprehensive summary is presented in table I.
尽管针对欺凌的研究可以追溯到 2010 年初,但网络欺凌检测的文献数量迅速增长。该领域的丰富文献可分为三类:基于内容的检测、基于用户的检测和基于网络的检测。每个类别都将被简要介绍,综合总结见表一。
A. Content-Based Detection(基于内容的检测)
Among the first to tackle bullying in social media is [11], where a framework was built to incorporate Twitter streaming API for collecting tweets and then classifying them according to the content. Their work combined the essence of sentiment analysis and bullying detection. As a first phase, tweets are classified as being positive or negative and then they are further classified as positive containing bullying content, positive without bullying content, negative containing bullying content, and negative without bullying content. For the sake of classification, Naïve Bayes was implemented and resulted in a relatively high accuracy (70%). Another later research found in [12], incorporated statistical measures namely (TFIDF) and (LDA) along with topic models in order to extract relevance in documents. However, they did not rely on statistical measures only but extracted content features like: bad words and pronouns. Other researchers in [13], continued to pursue cyberbullying detection from content-based perspective however, they introduced new features like: emotions icon and dictionary of hieroglyphs. Their approach was tested using many learning algorithms: Naïve Bayes, SVM and J 48. And the best result was recorded with SVM achieving an accuracy of 81%. Another research [14], presented a prototype system to be used by organization members to monitor social network sites and detect bullying incidents. The approach followed relied on recording bullying words and storing them in a database and then incorporate Twitter API to capture tweets and compare their content to the bullying material recorded earlier. Beside the promising innovative idea in their work, this prototype system has not been implemented yet.
最早解决社交媒体欺凌问题的是 [11],其中构建了一个框架来整合 Twitter 流 API,用于收集推文,然后根据内容对其进行分类。他们的工作结合了情绪分析和欺凌检测。作为第一阶段,推文被分类为正面或负面,然后将它们进一步分类为正面包含欺凌内容、正面没有欺凌内容、负面包含欺凌内容和负面没有欺凌内容。为了分类,实现了朴素贝叶斯并产生了相对较高的准确率(70%)。
[12] 中发现的另一项后来的研究结合了统计度量,即 (TFIDF) 和 (LDA) 以及主题模型,以提取文档中的相关性。然而,他们并不仅仅依赖于统计测量,而是提取了内容特征,比如:坏词和代词。
[13] 中的其他研究人员继续从基于内容的角度进行网络欺凌检测,但是,他们引入了新功能,例如:情绪图标和象形文字字典。他们的方法使用多种学习算法进行了测试:朴素贝叶斯、SVM 和 J 48。最好的结果是使用 SVM 记录,准确率达到 81%。
[14] 提出了一个原型系统,供组织成员用来监控社交网站和检测欺凌事件。随后的方法依赖于记录欺凌词并将它们存储在数据库中,然后结合 Twitter API 来捕获推文并将其内容与之前记录的欺凌材料进行比较。除了他们工作中很有前途的创新想法外,该原型系统尚未实施。
B. User-Based Detection(基于用户的检测)
Many researchers believed that user information like age and number of tweets could indicate potentiality to harm others. In [15], researchers incorporated user information like number of tweets, number of followers and number of followings into the detection process. Their total features -user based and others- resulted in good predictions with an accuracy of 85%. Similarly, in [14] they added user age as feature along with a history of a user as a feature. They assume that if a user bullied in the past it is more likely for him to engage in bullying again. They investigated the effect of adding user features and concluded that it advances the recall with 5%. User-based features were also adopted in [16], where they added user gender and age to the feature set. The assumption was that different gender use different language and the people from different ages have different writing styles. Moreover, a new user feature was incorporated which was the user location.
许多研究人员认为,年龄和推文数量等用户信息表明有可能会伤害他人。在 [15] 中,研究人员将用户信息(如推文数量、关注者数量和关注者数量)纳入检测过程。他们的总特征——基于用户的和其他的——产生了良好的预测,准确率为 85%。
同样,在 [14] 中,他们将用户年龄作为特征以及用户的历史作为特征添加。他们认为,如果用户过去曾被欺凌,他更有可能再次参与欺凌。他们调查了添加用户特征的效果,并得出结论认为它将召回率提高了 5%。
[16] 中还采用了基于用户的特征,他们在特征集中添加了用户性别和年龄。假设是不同性别使用不同的语言,不同年龄的人有不同的写作风格。此外,还加入了一个新的用户特征,即用户位置。
C. Network based Detection(基于网络的检测)
An interesting perspective to cyberbullying detection studies the social structure of users. This starts by drawing network structure and deriving features from the graph. In [17], they focused on deriving features from social network graph. Features included: number of nodes indicating how large is the community and number of edges indicating how well connected is the community. Another research that addressed network based features is found in [12]. They used (Gephi) a graphical interface to visualise a user‟s connectivity based on the bullying posts. Then, they investigated the participants‟ role in the bullying, whether they are victims or predators.
网络欺凌检测的一个有趣视角是研究用户的社会结构。这首先要绘制网络结构并从图中派生特征。在 [17] 中,他们专注于从社交网络图派生特征。特征包括:表示社区有多大的节点数和表示社区连接程度的边数。
在 [12] 中发现了另一项解决基于网络的特征的研究。他们使用(Gephi)图形界面来可视化基于欺凌帖子的用户连接。然后,他们调查了参与者在欺凌中的角色,无论他们是受害者还是掠夺者。

3、PROPOSED ALGORITHM(推荐的算法)
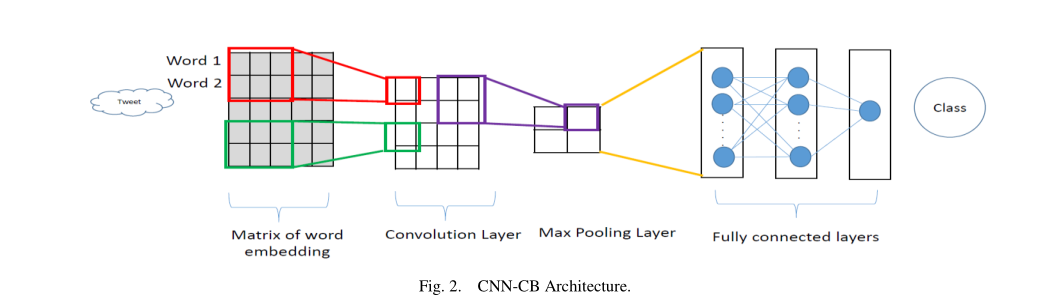
A. Word Embedding
Word embeddings are a class of techniques used to generate numerical representation of textual material. A striking feature of word embedding is that they generate similar representations for semantically similar words. This remarkable feature enables a machine to actually understand what text means rather than dealing with it as strings of random numbers. In order to illustrate this great potential, fig 3 shows the similar words to word „smart‟ along with their similarity score using word embedding provided by Glove. Glove [25] is one method of word embedding provided by google. This works by collecting millions of words and training a neural network to learn the similarity or differences in meaning.
词嵌入是一类用于生成文本材料的数字表示的技术。词嵌入的一个显着特征是它们为语义相似的词生成相似的表示。这一非凡的功能使机器能够真正理解文本的含义,而不是将其作为随机数字符串处理。为了说明这一巨大潜力,图 3 使用 Glove 提供的词嵌入显示了与词“smart”相似的词以及它们的相似度得分。 Glove [25] 是谷歌提供的一种词嵌入方法。这通过收集数百万个单词并训练神经网络来学习含义的相似性或差异来工作。

In the proposed CNN-CB, embedding layer provided by Keras [26] was adopted rather than pre trained embedding like Glove. What distinguish this specific choice of embedding (keras) is that it is task specific. In other words, it takes all text (cleaned tweets in this case) and generates a vector space of vocabulary. Thus, it is easier -both in time and resource-to compute. The use of word embedding made CNN-CB’s more advanced compared to traditional detection approaches since they incorporate semantics not just features extracted from raw text [27]. Keras embedding layer requires three parameters to be set prior to the construction of the vector space:
- Input dimension: specifies the total number of words in the vocabulary (whole corpus). This number is derived from the following. Let T be all tweets in the corpus.
T= {t1,t2,t3…tn}, n=number of tweets
Input dimension = length (Tokenized (T))
-
Output dimension: specifies the size of the output vector from this layer.
-
Input length: the length of each vector (maximum number of words per tweet). Twitter fixed maximum tweet length was not set, since this might change over time. Input length is calculated by using the following functions.
Input length = max (length for t in T)
在提出的 CNN-CB 中,采用了 Keras [26] 提供的嵌入层,而不是像 Glove 这样的预训练嵌入。这种嵌入(keras)的特定选择的区别在于它是特定于任务的。换句话说,它获取所有文本(在本例中为已清理的推文)并生成词汇向量空间。因此,在时间和资源上都更容易计算。与传统检测方法相比,词嵌入的使用使 CNN-CB 更先进,因为它们包含语义而不仅仅是从原始文本中提取的特征 [27]。 Keras 嵌入层需要在构建向量空间之前设置三个参数:
- 输入维度:指定词汇表(整个语料库)中的单词总数。这个数字是从以下推导出来的。令 T 为语料库中的所有推文。
T= {t1,t2,t3…tn},n=推文数
-
输入维度 = 长度(标记化 (T))
-
输出维度:指定该层的输出向量的大小。
-
输入长度:每个向量的长度(每条推文的最大字数)。未设置 Twitter 固定的最大推文长度,因为这可能会随着时间而改变。
-
输入长度使用以下函数计算。输入长度 = max(T 中 t 的长度)
B. Convolutional Layer
The second layer after the embedding layer (in case of text) is the convolutional layer. It is the heart of a convolutional neural network. Its task is to convolve around the input vector to detect features, therefore, it compresses the original input vector while preserving valuable features. This is achieved by creating a set of matrices called filters of random numbers called weights. Each filter is then independently convolved around the original input vector creating many feature maps through elementwise multiplication with the part of the input it is currently on [28]. In order to calculate the resulting feature map, Let V be the input vector of words, and F be the filter of size h*w, then the elementwise multiplication is calculated according to the following equation.
嵌入层后的第二层(文本)是卷积层。它是卷积神经网络的核心。它的任务是围绕输入向量进行卷积以检测特征,因此,它在压缩原始输入向量的同时保留有价值的特征。这是通过创建一组称为随机数过滤器(称为权重)的矩阵来实现的。然后每个过滤器独立地围绕原始输入向量进行卷积,通过元素乘法与它当前在[28]上的输入部分创建许多特征图。为了计算得到的特征图,设V为单词的输入向量,F为大小为h*w的滤波器,然后根据以下等式计算元素乘法。

C. Max Pooling Layer
What distinguishes CNN and gives it robustness and ability to deal with complex data like image and large corpus, is that it compresses the input to smaller matrices. This remarkable ability is achieved by both convolutional and max pooling layers; thus, they are used after one another. Max pooling matrix simply slides across the output of a convolutional layer and finds the maximum value of the selected area. In this way, only meaningful and clear features are preserved.
最大池化层 :CNN 的不同之处在于它具有鲁棒性和处理复杂数据(如图像和大型语料库)的能力,在于它将输入压缩为更小的矩阵。这种非凡的能力是通过卷积层和最大池化层实现的;因此,它们一个接一个地使用。最大池化矩阵简单地滑过卷积层的输出并找到所选区域的最大值。这样,只保留有意义和清晰的特征。
D. Dense Layer
All layers described so far were concerned with shaping data (tweets in our case) and compressing them in a meaningful way. So far, no classification has been done. This is exactly the job of dense layers. As in neural network, dense layers are set of fully connected layers [14]. In other words, each neuron is connected to all other neurons in the following layer. The number of dense layers varies, however, the last one must have 2 neurons corresponding to the number of classes in this case.
全连接层: 到目前为止描述的所有层都关注于塑造数据(在我们的例子中是推文)并以有意义的方式压缩它们。到目前为止,还没有进行分类。这正是全连接的工作。与神经网络一样,全连接层是一组完全连接的层[14]。换句话说,每个神经元都连接到下一层中的所有其他神经元。全连接层的数量各不相同,但是,在这种情况下,最后一层必须有 2 个与类别数量相对应的神经元。

4、EVALUATION(模型评估)
Evaluation of the proposed algorithm aims to experimentally investigate crucial facts. First, that CNN-CB gives better results than traditional cyberbullying detection. Second, to evaluate other metrices like loss and recall. In order to have subjective evaluation, content-based detection was implemented for comparison with SVM algorithm. SVM was considered because a survey in [5], revealed that it is the mostly used in this domain. All experiments were run using Windows PC with 12 GB of RAM. All algorithms were programmed in Python [30] using Spyder environment [31]. CNN-CB was implemented using Keras [26] [29].
对所提出算法的评估旨在通过实验研究关键事实。首先,CNN-CB 提供了比传统网络欺凌检测更好的结果。其次,评估损失和召回等其他指标。为了进行主观评价,实现了基于内容的检测与SVM算法进行比较。之所以考虑 SVM,是因为 [5] 中的一项调查显示,它是该领域中最常用的。所有实验均使用具有 12 GB RAM 的 Windows PC 运行。所有算法都使用 Spyder 环境 [31] 在 Python [30] 中编程。 CNN-CB 是使用 Keras [26] [29] 实现的。
A. Content-Based Detection (Cont)
There are many detection methods, however, a survey found in [5] stated that content-based methods are the most common with a total of 41 papers. Also, it has reported that SVM was the most common learning algorithm. The features included were: 1) the presence of bad words (bad words were retrieved from noswearing.com [32]); 2)the tweet‟s length;; 3)the presence of question marks since they indicate profane words; 4) the presence of exclamation marks since they indicate anger; 5) the presence of capital letters since they indicate anger.
A. 基于内容的检测(续)
检测方法有很多种,然而,在 [5] 中发现的一项调查表明,基于内容的方法是最常见的,共有 41 篇论文。此外,据报道,SVM 是最常见的学习算法。包括的特征是:
1)不好的词的存在(从 noswearing.com [32] 检索到的坏词);
2)推文的长度;
3)“?”的存在,因为它们表示亵渎的词;
4)“!”的存在,因为它们表示愤怒;
5)大写字母的存在,因为它们表示愤怒。
B. Dataset
The data set used in experiments were fetched from Twitter using Twitter streaming API [33]. A total of 39,000 tweets were retrieved from twitter public timeline. However, after annotating tweets, we found that there was an imbalanced class problem (very few bullying tweets). This has been solved by querying Twitter API with bad words from [32] so that it was more likely to return bullying tweets. After that, data were inspected and cleaned, removing duplicates and tweets with only pictures or URLs. A summary of the data collected for training and testing is presented in table III .
For data annotation, Figure 8 [34] human intelligence website was used. A job was posted, and sufficient instructions were given, and for quality purposes a test of 25 questions were required for a contributor to be accepted. Eventually, from those who succeeded the test with a percentage of 95%, two contributors were selected.
B. 数据集
实验中使用的数据集是使用 Twitter 流 API [33] 从 Twitter 获取的。从推特公共时间线共检索到 39,000 条推文。然而,在对推文进行注释之后,我们发现存在一个不平衡的类别问题(很少有欺凌推文)。这已通过使用 [32] 中的坏词查询 Twitter API 来解决,这样它更有可能返回欺凌推文。之后,对数据进行检查和清理,删除仅包含图片或 URL 的重复项和推文。为训练和测试收集的数据摘要见表 III。
对于数据注释,使用了图 8 [34] 人类智能网站。发布了一份工作,并给出了足够的说明,并且出于质量目的,需要对 25 个问题进行测试才能使贡献者被接受。最终,从那些以 95% 的百分比通过测试的人中选出了两名贡献者。
C. Evaluation
Metrics Since cyberbullying detection is a classification task, the obvious choice of metric will be classification accuracy. However, this is an imbalanced class problem; so if we consider accuracy only as a metric then we might get an accuracy of 80% just be labelling all testing tweets with the majority class. This issue has been solved by considering two other metrics: recall and precision. All metrics are listed in the following equations. accuracy= (2) recall= (3) precision= (4)
评估指标 :
由于网络欺凌检测是一项分类任务,因此指标的明显选择将是分类准确性。然而,这是一个不平衡的类问题;因此,如果我们仅将准确度视为一个指标,那么我们可能会获得 80% 的准确度,只需将所有测试推文标记为多数类。这个问题已经通过考虑另外两个指标得到解决:召回率和准确率。所有指标都列在以下等式中。准确率= (2) 召回率= (3) 准确率= (4)

D. Result
In this section, comprehensive comparison between three cyberbullying detection approaches was conducted. The aim here is to prove that the proposed algorithm CNN-CB advances the current state of cyberbullying detection by providing better predictions (higher accuracy) although it eliminates the need for feature engineering. The series of experiments starts by testing CNN-CB with different values of filters, kernels, pooling and neurons to prove that changing values changes the quality of prediction. This experiment is reported in table IV. Moreover, further experiments are conducted to test the CNN-CB model. Fig.4 and fig. 5 shows the model accuracy and loss during every epoch respectively. The loss used in here is the mean squared error The third experiment shown in table V, is conducted with the traditional approach of cyberbullying detection, specifically contentbased detection cont, and provides a summarized overview about its performance. Remarkably, the advancement of CNNCB over traditional approach is clearly reported in fig.5, fig.6 and fig.7.
结果:
在本节中,对三种网络欺凌检测方法进行了综合比较。这里的目的是证明所提出的算法 CNN-CB 通过提供更好的预测(更高的准确性)来推进网络欺凌检测的当前状态,尽管它消除了对特征工程的需要。这一系列实验首先使用不同值的过滤器、内核、池化和神经元测试 CNN-CB,以证明改变值会改变预测的质量。该实验报告在表IV中。此外,还进行了进一步的实验来测试 CNN-CB 模型。图 4 和图图 5 分别显示了每个 epoch 的模型精度和损失。这里使用的损失是均方误差表 V 中显示的第三个实验是使用传统的网络欺凌检测方法进行的,特别是基于内容的检测 cont,并提供了关于其性能的总结概述。值得注意的是,CNNCB 相对于传统方法的进步在图 5、图 6 和图 7 中得到了清晰的报告。




5、DISCUSSION(讨论)
Cyberbullying detection has been addressed in the literature with classical machine learning approaches, mainly content-based ones. However, the conducted experiments showed that cont-SVM gave an accuracy of 81%, like results reported by others in the literature.
文献中已经使用经典的机器学习方法(主要是基于内容的方法)解决了网络欺凌检测问题。然而,进行的实验表明,cont-SVM 的准确度为 81%,与文献中其他人报告的结果相似。
The performance of CNN-CB during epochs, was always raising. This is because learning is evolving with every epoch. The model started with an accuracy of 65% but rose to 95% after 10 epochs. Model loss which represents a measurement of miss classifications also proved that increasing the number of epoch improve quality of predictions.
CNN-CB 在各个时期的表现一直在提高。这是因为学习在每个时代都在发展。该模型以 65% 的准确率开始,但在 10 个 epoch 后上升到 95%。代表未分类测量的模型损失也证明了增加 epoch 的数量可以提高预测的质量。
When CNN-CB is compared to traditional cyberbullying approach cont-SVM, CNN-CB, reported better results in the three metrics accuracy, precision and recall. This is true for all variations of parameters proving that feature engineering elimination did not degrade the performance but in fact there was a noticeable improvement of about 12% accuracy. Among the three studied metrics, accuracy shows the most noticeable difference. On the other hand, recall has slightly differed between the two algorithms with them being in the 70s.
当 CNN-CB 与传统的网络欺凌方法 cont-SVM 进行比较时,CNN-CB 在准确度、精确度和召回率三个指标上报告了更好的结果。这适用于所有参数变化,证明特征工程消除不会降低性能,但实际上有大约 12% 的准确度显着提高。在研究的三个指标中,准确性显示出最明显的差异。另一方面,这两种算法在 70 年代的召回率略有不同。
It also has been evident from table IV that changing the CNN structure has a strong impact on the resulting accuracy. Some variations produced an accuracy of 66% whereas, some produced 95%.
从表 IV 中也可以明显看出,改变 CNN 结构对结果的准确性有很大的影响。一些变化产生了 66% 的准确度,而一些变化产生了 95%。
6、CONCLUSION (结论)
Technology revolution advanced the quality of life, however, it gave predators a solid ground to conduct their harmful crimes. Internet crimes have become very dangerous since victims are targeted all the time and there are no chances for escape. Cyberbullying is one of the most critical internet crimes and research proved its critical consequences on victims. From suicide to lowering victims‟ self-esteem, cyberbullying control has been the focus of many psychological and technical research.
技术革命提高了生活质量,然而,它为掠食者提供了实施有害犯罪的坚实基础。网络犯罪已经变得非常危险,因为受害者一直是目标,没有逃脱的机会。网络欺凌是最严重的互联网犯罪之一,研究证明其对受害者的严重后果。从自杀到降低受害者的自尊心,网络欺凌控制一直是许多心理和技术研究的重点。
In this article, the issue of cyberbullying detection on Twitter has been tackled. The aim was to advance the current state of cyberbullying detection by shedding light on critical problems that have not been solved yet. To the best of our knowledge, there has been no research that considered eliminating features from the detection process and automating the process with a CNN. The proposed algorithm makes cyberbullying detection a fully automated process with no human expertise or involvement while guaranteeing better result. Comprehensive experiments proved that deep learning outperformed classical machine learning approaches in cyberbullying problem.
在本文中,已经解决了 Twitter 上的网络欺凌检测问题。其目的是通过揭示尚未解决的关键问题来推进网络欺凌检测的当前状态。据我们所知,还没有研究考虑从检测过程中消除特征并使用 CNN 使过程自动化。所提出的算法使网络欺凌检测成为一个完全自动化的过程,无需人工专业知识或参与,同时保证更好的结果。综合实验证明,深度学习在网络欺凌问题上优于经典机器学习方法。
As for future work, we would like to adapt the proposed algorithms for Arabic content. Arabic language has different structure and rules so comprehensive Arabic natural language processing should be incorporated.
至于未来的工作,我们希望针对阿拉伯语内容调整提议的算法。阿拉伯语具有不同的结构和规则,因此应纳入全面的阿拉伯语自然语言处理。
7、参考文献
[1] R. Shetgiri, “Bullying and Victimization Among Children,” Adv. Pediatr., vol. 60, no. 1, pp. 33–51, Jul. 2013.
[2] R. Donegan, “Bullying and cyberbullying: History, statistics, law, prevention and analysis,” Elon J. Undergrad. Res. Commun., vol. 3, no. 1, pp. 33–42, 2012.
[3] D. Halpern, M. Piña, and J. Vásquez, “Loneliness, personal and social well-being: towards a conceptualization of the effects of cyberbullying/Soledad, bienestar social e individual: hacia una conceptualización de los efectos del cyberbullying,” Cult. y Educ., vol. 29, no. 4, pp. 703–727, 2017.
[4] K. Van Royen, K. Poels, W. Daelemans, and H. Vandebosch, “Telematics and Informatics Automatic monitoring of cyberbullying on social networking sites : From technological feasibility to desirability,” Telemat. INFORMATICS, 2014.
[5] S. Salawu, Y. He, and J. Lumsden, “Approaches to Automated Detection of Cyberbullying : A Survey,” vol. 3045, no. c, pp. 1–20, 2017.
[6] T. Wu, S. Liu, J. Zhang, and Y. Xiang, “Twitter spam detection based on deep learning,” Proc. Australas. Comput. Sci. Week Multiconference - ACSW ‟17, pp. 1–8, 2017.
[7] MIT Technology Review, “These are the 10 breakthrough technologies you need to know about right now,” 2018. [Online]. Available: https://www.technologyreview.com/lists/technologies/2017/. [Accessed: 02-Mar-2018].
[8] R. Johnson and T. Zhang, “Effective use of word order for text categorization with convolutional neural networks,” arXiv Prepr. arXiv1412.1058, 2014.
[9] X. Zhang, J. Zhao, and Y. LeCun, “Character-level convolutional networks for text classification,” in Advances in neural information processing systems, 2015, pp. 649–657.
[10] A. J. McMinn, Y. Moshfeghi, and J. M. Jose, “Building a large-scale corpus for evaluating event detection on twitter,” in Proceedings of the 22nd ACM international conference on Information & Knowledge Management, 2013, pp. 409–418.
[11] H. Sanchez and S. Kumar, “Twitter bullying detection,” ser. NSDI, vol. 12, p. 15, 2011.
[12] V. Nahar, X. Li, and C. Pang, “An effective approach for cyberbullying detection,” Commun. Inf. Sci. Manag. Eng., vol. 3, no. 5, p. 238, 2013.
[13] C. Paper, “Methods for detection of cyberbullying : A survey,” no. October, 2016.
[14] M. Dadvar, D. Trieschnigg, R. Ordelman, and F. De Jong, “Improving cyberbullying detection with user context,” pp. 2–5.
[15] E. A. Abozinadah, A. V Mbaziira, and J. H. J. Jr, “Detection of Abusive Accounts with Arabic Tweets,” vol. 1, no. 2, 2015.
[16] V. Nahar, S. Al-Maskari, X. Li, and C. Pang, “Semi-supervised learning for cyberbullying detection in social networks,” in Australasian Database Conference, 2014, pp. 160–171.
[17] P. K. Atrey, “Cyber Bullying Detection Using Social and Textual Analysis,” pp. 3–6, 2014.
[18] S. O. Sood, E. F. Churchill, and J. Antin, “Automatic Identification of Personal Insults on Social News Sites,” vol. 63, no. 4, pp. 270–285, 2012.
[19] Q. Huang, V. K. Singh, and P. K. Atrey, “Cyber bullying detection using social and textual analysis,” in Proceedings of the 3rd International Workshop on Socially-Aware Multimedia, 2014, pp. 3–6.
[20] R. Sugandhi, “Automatic Monitoring and Prevention of Cyberbullying Automatic Monitoring and Prevention of Cyberbullying,” no. June, 2016.
[21] K. Reynolds, A. Kontostathis, and L. Edwards, “Using Machine Learning to Detect Cyberbullying.”
[22] H. Hosseinmardi, S. A. Mattson, R. I. Rafiq, R. Han, Q. Lv, and S. Mishra, “Detection of Cyberbullying Incidents on the Instagram Social Network,” 2014.
[23] B. S. Nandhini and J. I. Sheeba, “Online Social Network Bullying Detection Using Intelligence Techniques,” vol. 45, pp. 485–492, 2015.
[24] K. Dinakar, B. Jones, C. Havasi, and H. Lieberman, “Common Sense Reasoning for Detection , Prevention , and Mitigation of Cyberbullying,” vol. 2, no. 3, 2012.
[25] J. Pennington, R. Socher, and C. Manning, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543.
[26] F. Chollet, “Keras,” GitHub, 2015. [Online]. Available: https://github.com/fchollet/keras. [Accessed: 26-Aug-2018].
[27] Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin, “A neural probabilistic language model,” J. Mach. Learn. Res., vol. 3, no. Feb, pp. 1137–1155, 2003.
[28] N. Majumder, A. Gelbukh, I. P. Nacional, and E. Cambria, “Deep learning-based document modeling for personality detection from text,” IEEE Intell. Syst., vol. 32, no. 2, pp. 74–79, 2017.
[29] A. Géron, Hands-on machine learning with Scikit-Learn and TensorFlow: concepts, tools, and techniques to build intelligent systems. “ O‟Reilly Media, Inc.,” 2017.
[30] “Python.” [Online]. Available: http://www.python.org. [Accessed: 28Aug-2018].
[31] “The Scientific Python Development Environment,” 2018. [Online]. Available: https://www.spyder-ide.org/. [Accessed: 28-Aug-2018].
[32] “Swear Word List.” [Online]. Available: https://www.noswearing.com/. [Accessed: 28-Aug-2018].
[33] “Python Twitter,” 2016. [Online]. Available: https://pythontwitter.readthedocs.io. [Accessed: 28-Aug-2018].
[34] Figure Eight Inc, “Figure Eight,” 2018. [Online]. Available: https://www.figure-eight.com/. [Accessed: 28-Aug-2018].














 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









