







1.Elasticsearch 数据分区和路由策略介绍
1.1 数据分区
Elasticsearch 是一个分布式搜索引擎,可以将索引和数据分片存储在多个节点上。数据分区是指将索引的数据分成多个分片,以实现分布式的数据存储和查询。每个分片都是一个完整的索引,可以独立于其他分片进行操作和查询。
数据分区的主要目的是提高系统的容量和性能。通过将数据分布在多个分片上,可以以并行方式处理大量的请求,提高查询的响应速度和吞吐量。此外,数据分区还可以增加系统的可靠性和可用性。当一个节点发生故障时,其他节点上的分片仍然可以继续提供服务。
Elasticsearch 使用哈希算法将文档分配到不同的分片上。默认情况下,每个索引有 5 个主分片和 1 个副本分片,可以根据需求进行调整。
1.2 路由策略
路由策略是指确定文档应该被分配到哪个分片的规则。Elasticsearch 提供了两种路由策略:hash 和 custom。
- `hash` 路由策略:通过对文档的 `_id` 进行哈希运算,将文档分配到不同的分片上。这种策略可以保证相同 `_id` 的文档被分配到相同的分片上,可以轻松实现精确的文档查询操作。但是,如果文档的分布不均匀,可能会导致一些分片的负载较高,影响系统的性能。
- `custom` 路由策略:可以根据文档的特定字段值进行路由。例如,可以根据用户 ID 或地理位置将文档分配到不同的分片上。这种策略需要应用程序来确定文档的路由值,并将其指定在索引请求中。
2.Elasticsearch 数据分区和路由策略示例代码
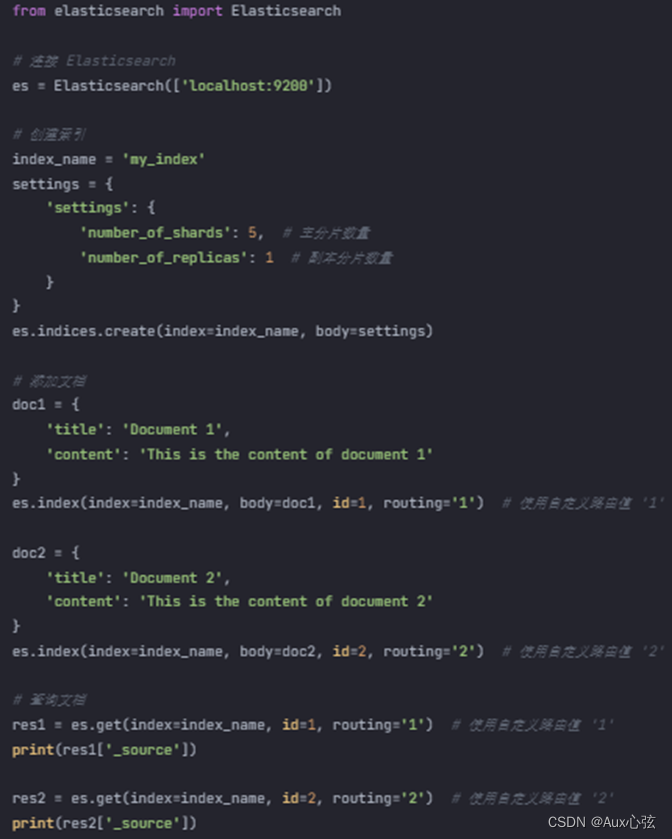
| from elasticsearch import Elasticsearch # 连接 Elasticsearch es = Elasticsearch(['localhost:9200']) # 创建索引 index_name = 'my_index' settings = { 'settings': { 'number_of_shards': 5, # 主分片数量 'number_of_replicas': 1 # 副本分片数量 } } es.indices.create(index=index_name, body=settings) # 添加文档 doc1 = { 'title': 'Document 1', 'content': 'This is the content of document 1' } es.index(index=index_name, body=doc1, id=1, routing='1') # 使用自定义路由值 '1' doc2 = { 'title': 'Document 2', 'content': 'This is the content of document 2' } es.index(index=index_name, body=doc2, id=2, routing='2') # 使用自定义路由值 '2' # 查询文档 res1 = es.get(index=index_name, id=1, routing='1') # 使用自定义路由值 '1' print(res1['_source']) res2 = es.get(index=index_name, id=2, routing='2') # 使用自定义路由值 '2' print(res2['_source']) |
3.参数介绍
- number_of_shards: 指定索引的主分片数量,默认值为 5。创建索引时设置,后续无法修改。
- number_of_replicas: 指定每个主分片的副本分片数量,默认值为 1。创建索引时设置,可以后续动态修改。
- routing: 文档的路由值,在索引文档时使用。对于哈希路由策略,使用 _id 进行哈希运算,保证相同 _id 的文档被分配到相同的分片上。对于自定义路由策略,使用应用程序指定的值作为路由值进行分片。
4.总结
Elasticsearch 的数据分区和路由策略是实现分布式存储和查询的基础。通过将索引的数据分片存储在多个节点上,并使用适当的路由策略,可以实现高容量、高性能、高可用的搜索引擎。在实际应用中,根据数据量和性能需求,可以灵活地设置主分片和副本分片的数量,以及选择合适的路由策略。



















 2244
2244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











