







1简介
Kafka是一个分布式流处理平台,其设计目标是提供高吞吐量、低延迟的数据传输,具有良好的可扩展性和容错性。在Kafka中,存储和缓存策略是非常重要的,它们直接影响到Kafka的性能和可靠性。本章将详细介绍Kafka的存储和缓存策略。
2存储策略
2.1 磁盘存储
Kafka使用磁盘存储消息数据,它将消息分成一个个的分区,每个分区对应一个日志文件(log file),并将日志文件存储在磁盘上。每个日志文件由多个日志段(log segment)组成,每个日志段的大小可以配置。当一个日志段写满后,Kafka会创建一个新的日志段,并将新的消息写入其中。旧的日志段会被异步地清理掉,以释放磁盘空间。
2.2 文件系统缓存
Kafka利用操作系统的文件系统缓存来加速数据的读取和写入。当消息被写入磁盘时,操作系统会将其缓存在内存中,并在需要时进行读取,避免了频繁的磁盘IO操作。这种利用文件系统缓存的方式可以显著提高Kafka的读写性能。
2.3 零拷贝技术
Kafka使用了零拷贝技术,即在消息传输过程中避免了数据的复制操作。传统的方式是将数据从一个缓冲区复制到另一个缓冲区,而零拷贝技术通过操作系统的DMA(Direct Memory Access)功能,将数据直接从磁盘读取到内存中,或者从内存中直接写入磁盘,避免了数据的多次复制,提高了数据传输的效率。
3.缓存策略
3.1 内存缓存
Kafka使用内存来作为消息的缓存,通过将消息缓存在内存中,可以实现低延迟的读写操作。Kafka的内存缓存分为两个部分:消息的读缓存和消息的写缓存。读缓存用于缓存已经被消费者读取的消息,以便下次读取时可以快速返回。写缓存用于缓存待写入磁盘的消息,以提高数据的写入速度。
3.2 堆外内存
Kafka还使用了堆外内存来存储消息,堆外内存是直接分配在操作系统的内存中,不受JVM堆内存的限制。堆外内存的好处是可以避免对象在JVM堆内存中的创建和销毁,减少了GC的压力,提高了Kafka的性能。
4.参数介绍和代码案例
以下是一些与存储和缓存相关的Kafka配置参数:
4.1 log.segment.bytes
该参数用于配置每个日志段的大小,默认为1GB。较小的日志段大小可以提高消息的写入速度,但会增加磁盘空间的使用。
4.2 log.flush.interval.messages
该参数用于配置每隔多少条消息就将消息刷写到磁盘,默认为0,即每条消息都会被刷写到磁盘。可以调整该参数的值来控制消息的写入速度。
4.3 log.flush.interval.ms
该参数用于配置每隔多少毫秒就将消息刷写到磁盘,默认为null,即不主动刷写。可以调整该参数的值来控制消息的写入速度。
4.4 log.segment.ms
该参数用于配置每个日志段的最大生存时间,默认为7天。超过该时间的日志段会被删除,以释放磁盘空间。
下面是一个简单的Kafka生产者代码示例:
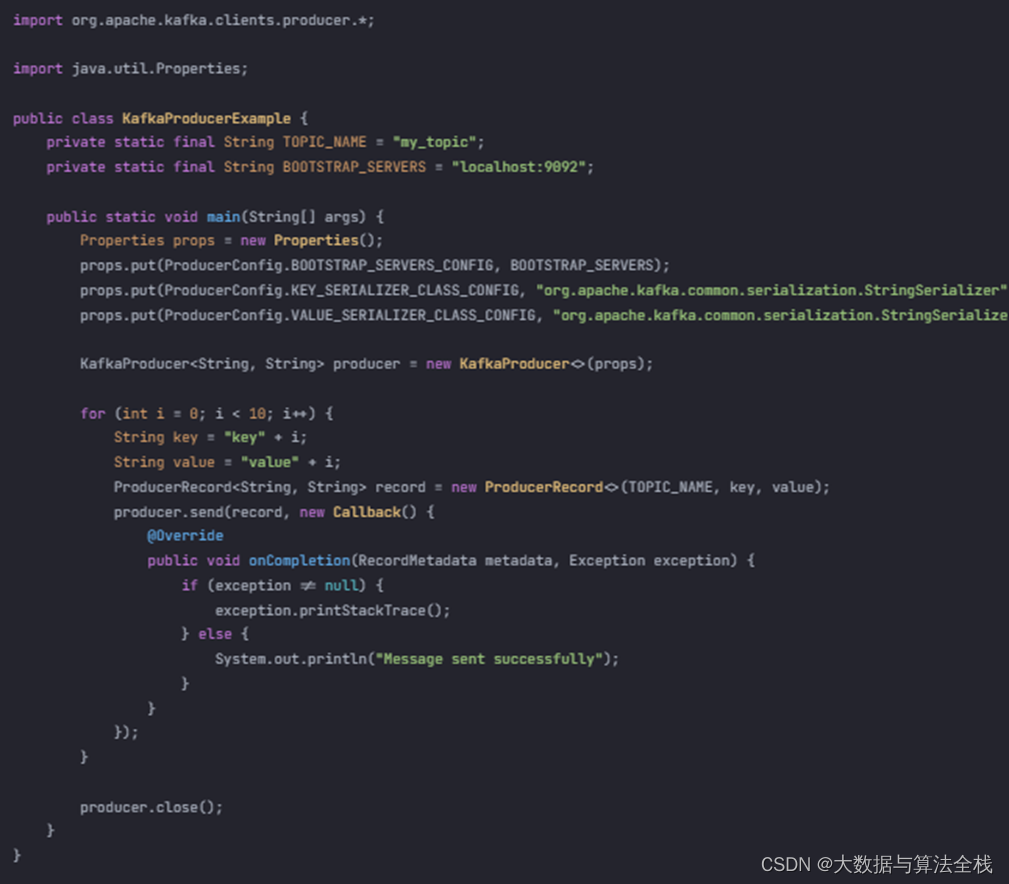
| import org.apache.kafka.clients.producer.*; import java.util.Properties; public class KafkaProducerExample { private static final String TOPIC_NAME = "my_topic"; private static final String BOOTSTRAP_SERVERS = "localhost:9092"; public static void main(String[] args) { Properties props = new Properties(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 10; i++) { String key = "key" + i; String value = "value" + i; ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, key, value); producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception != null) { exception.printStackTrace(); } else { System.out.println("Message sent successfully"); } } }); } producer.close(); } } |
以上代码演示了一个简单的Kafka生产者,它会向名为"my_topic"的主题发送10条消息。其中,BOOTSTRAP_SERVERS是Kafka集群的地址,ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG和ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG分别指定了消息的键和值的序列化器。
通过设置合适的存储和缓存策略,可以提高Kafka的性能和可靠性。合理配置存储策略可以充分利用磁盘空间,避免数据丢失和过多的磁盘IO操作。而适当调整缓存策略可以提高数据的读写速度和响应时间。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











