









已经好几天没接着看faster rcnn的源代码了,前几天试了一下可以成功训练了。
jwyang’s github: https://github.com/jwyang/faster-rcnn.pytorch
记录一下怎么做的吧。凭印象回忆一下吧。
虚拟环境
安装虚拟环境 pip install --user virtualenv
进入虚拟环境 source zyfenv/bin/activate
(注,后来我用conda创建的虚拟环境可以这样进:source activate zyfenv)
退出虚拟环境 deactivate
在虚拟环境里面配置自己需要的环境
pip install numpy torchvision_nightly
pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu90/torch_nightly.html
conda install pytorch=0.4.1 cuda90 -c pytorch
wget https://repo.anaconda.com/archive/Anaconda2-2018.12-Linux-x86_64.sh
pip install https://download.pytorch.org/whl/cu90/torch-0.4.0-cp36-cp36m-linux_x86_64.whl
faster rcnn主目录下操作
mkdir data
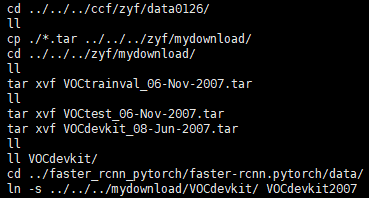
这里编译时nvcc好像有问题,我是直接把里面的nvcc换成了具体地址。
插一句,如何在服务器跑matlab的m文件

预训练vgg模型
vgg16_caffe.pth 有些连接还得翻墙,很麻烦,就是他,我在百度网盘找的。
因为有一些参数都有默认值,最后我运行train的代码就OK了
python trainval_net.py --save_dir ./data/voc_2007_trainval/ --cuda
这里得强调一下需要修改的有

这个路径下有一堆txt文件,训练的图片的name好像就是在trainval.txt里面,自己可以改里面的内容确定用哪些来训练。
训练的样子是这样的,GPU资源不足,我暂时用20个图片训练
啊哦 有问题

不过这就是我之前训练的模型

2019.5.3
后来test也跑通了,上次没跑通是因为没有[‘width’]的错误,也不太清楚是什么错误,反正清一下缓存就行了。训练的时候有可能也出现断言错误,还是清一下缓存就好了。我也不知道为什么清缓存就可以了。怎么清缓存,就是data/cache路径下的那个。
训练时要记得改一下
/fasterrcnn.pytorch/data/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt里面的图片名字(这里用1673个),因为有些不存在。
CUDA_VISIBLE_DEVICES=3 python trainval_net.py --save_dir ./data/voc_2007_trainval/ --cuda

测试时要改一下跟trainval.txt同路径下的test.txt文件(我这里有3009个)
CUDA_VISIBLE_DEVICES=3 python ./test_net.py --load_dir ./data/voc_2007_trainval/ --checksession 1 --checkepoch 20 --checkpoint 1673 --net vgg16 --cuda
这里要加上vgg16因为默认好像是resnet。

啊哦,test又出错了。
那我删除一些,留999个,再试试。
还是000008这个KeyError。
然后faster-rcnn.pytorch/data/VOCdevkit2007/annotations_cache这里面的我也删了,还不行。
找了好一会,感觉没问题了啊。。。。。。。。
那我把test.txt里面的000008删了试试呢。
还是不行,又是000010了。
运行demo
CUDA_VISIBLE_DEVICES=3 python ./demo.py --load_dir ./data/voc_2007_trainval/ --checksession 1 --checkepoch 20 --checkpoint 1673 --net vgg16 --cuda
他可以把images文件夹里所有的图片都给处理了。


还行,把人像给框起来了,还是0.996。
2019.5.18
#####conda create -n tensorflow-gpu python=3.6
test的问题没解决,我重新复现。这次安装github上的步骤来。上次是自己从其他博客上学的。
安装github上的步骤来,操作。
CUDA_VISIBLE_DEVICES=0 python trainval_net.py --dataset pascal_voc --net vgg16 --bs 5 --nw 1 --lr 0.001 --lr_decay_step 100 --cuda

这边为啥有10022个image,我看了一下trainval.txt文件下有5011个数据,所以有可能是我没删cache中的文件就直接训练导致的。

服务器扛不住
bs nw都小一点


训练每次save模型时有个小报错,但是不影响后续训练


试试test





wc,终于能够没bug跑通test了。
之前是什么问题?不知道。可能之前自己太菜了。
这次我是完全从头来做的,所谓的破而后立。
-------------补充一下-----------------------------------------
在主目录output里面有pkl格式的检测结果
在主目录data/VOCdevkit/results/VOC2007/Main里面有每个类别的txt文件,包含五列,第一列是名字,第二列是该类别得分,剩下四列是框的坐标。
每个名字可能会对应很多行,但是存在很多得分是接近0的,这种就不算属于这种类别了。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









