










csapp 第五章读书笔记 part2
Program Profiling
gprof是一种性能分析工具,用于分析程序的运行时间和函数调用关系。它可以帮助开发人员找出程序中的瓶颈和性能问题,从而进行优化。
gprof的工作原理是通过在程序中插入计时器和计数器来收集数据。它会在程序运行时记录函数的调用次数、运行时间和调用关系。然后,通过分析这些数据,gprof生成一个报告,显示每个函数的运行时间和调用次数,以及函数之间的调用关系图。
gprof报告中的一些重要信息包括:
- 执行时间百分比:显示每个函数在总运行时间中所占的百分比,帮助确定哪些函数是程序的热点。
- 函数调用关系图:显示函数之间的调用关系,帮助开发人员理解程序的结构和流程。
- 函数运行时间:显示每个函数的运行时间,帮助确定哪些函数需要优化。
使用gprof可以帮助开发人员找出程序中的性能问题,优化程序的运行时间和资源利用率。它是Unix系统中常用的性能分析工具之一。
Profiling with gprof requires three steps
- The program must be compiled and linked for profiling, 在编译的时候使用-pg 和 -0g

- 执行程序,会生成 gmon.out
- 调用gprof 分析 gmon.out
第一部分按照降序列出了执行不同函数所花费的时间。

第二部分显示了函数的调用历史。

158,655,725 次是find_ele_rec 调用自己, and 965,027 次是被insert_string调用,find_ele_rec 调用了save_string 和 new_ele 函数。
分析莎士比亚的文章的词条出现次数

“to be” 出现了1020次。“I am” 出现了1892次。
n-gram 包含4个步骤:

- lower1函数调用strlen函数,将字符转为小写,strlen是o(n), 所以lower1函数是o(n ^2)
- 将字符串通过hash函数映射到bucket,一共有s个bucket
- 每一个bucket都对应一个linked list, 程序会扫描list, 如果这个字符串存在,更细频次;否则,增加新的 list元素;
- 根据频次排序
程序主要花费的时间可以分成4部分:


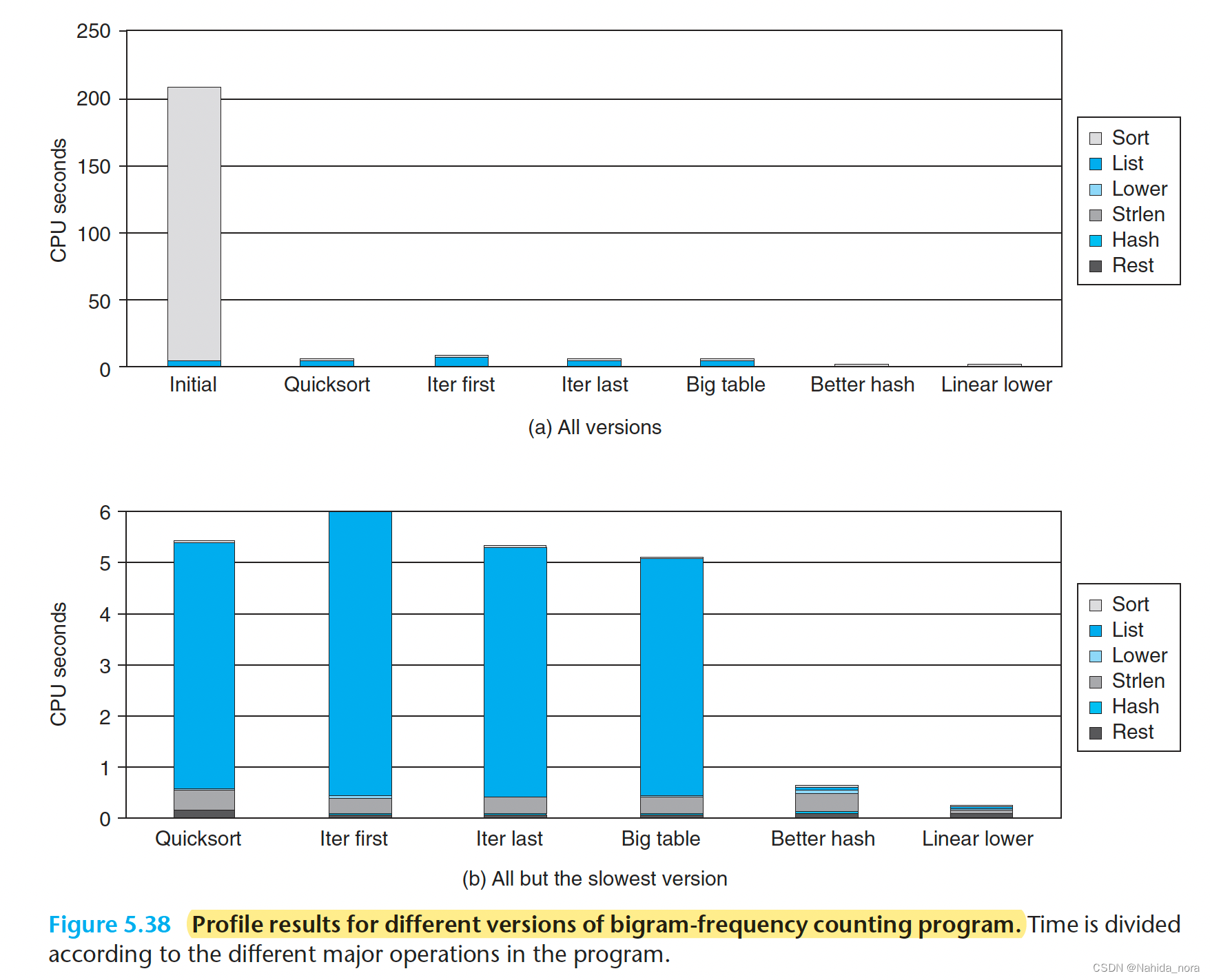
根据图a, initial的大部分时间花费在sorting,insert sort的时间复杂度是o(n ^2); 下一版本使用quick sort, quick sort的运行时间是 o(nlogn),对于这个版本的时间花费主要在list部分,list scanning becomes the bottleneck;
在下一个版本,iter first版本,如果直接将recursive structure替换为iterative的数据结构, 但是时间反而花费更多了, 和新增元素插入位置又关系。The recursive version inserted new elements at the end of the list, while the iterative one inserted them at the front;
为了最大化性能,我们期望一般出现频次最高的单词,出现list的开头部分。所以新元素插在尾部,性能更好些。
假设n-gram在文档中均匀分布,我们预期频繁的n-gram的首次出现将会在不频繁的n-gram之前。通过将新增的元素添加到list的尾部,第一个函数倾向于降序,第二个函数刚好相反。第三个函数,使用iteration的方式做list-scanning。第四个函数, iter last, 和 iter first不同,将新增元素插在尾部,时间下降到5.3s,比递归方式更优秀的时间。
这些测量结果表明,在优化过程中运行实验对程序的重要性。我们最初假设将递归代码转换为迭代代码会提高其性能,并没有考虑添加到列表末尾或开头的区别。
接下来,考虑the hash table structure,第一个函数,只有1021个buckets, 但是有363039个entries, 所以大概会有 363039/1021 = 355.6次个load。当bucket的数量增加到199999, 之后平均load的次数是1.8。奇怪的是,性能值提高了0.2s。
那么进行更深层次的思考吧,仅有0.2s的性能提高是因为hash function的选择,字符z对应的ascii数值是122, 字符a对应是97,所以对于长度为n的字符串的最大值是122n。考虑下最长的字符串是"honorificabilitudinitatibus thou", 这个字符串的数字总和是3371, 所以大部分的bucket处于没有使用的状态。对于可交换的hash function, 字符串tar 和 字符串rat会产生相同的sum。
当开始使用shift和xor(异或)的hash function, 称之为better hash, 时间下降到0.6s。更好的hash函数可以让输出更加平均,不会出现某一个key访问次数过多。
最后,发现时间花费在调用strlen函数上,考虑到lower1是o(n ^2), 使用lower2 替换 lower1, 将时间降低到 0.2s。
可以看到,profiling是有用的工具,但不应该是唯一的工具。时间测量是不完美的,特别是对于较短(少于1秒)的运行时间。更重要的是,这些结果仅适用于特定的测试数据。例如,如果在由较少数量但较长字符串组成的数据上运行原始函数,会发现小写转换程序是主要的性能瓶颈。更糟糕的是,如果只对包含短单词的文档进行性能分析,可能永远无法检测到隐藏的瓶颈,例如lower1。一般来说,通过性能分析可以帮助针对典型测试用例进行优化,假设在代表性用例上运行程序,还应确保程序在所有可能情况下都具有可观的性能。这主要涉及避免算法(如插入排序)和糟糕的编程实践(如lower1),这些会导致糟糕的渐进性能。
第五章总结
complier 无论怎样优化代码,都不会替换数据结构和算法。
要在基本水平之上调优性能,需要对处理器的微体系结构有一定的了解,描述了处理器实现其指令集体系结构的基本机制。对于乱序处理器的情况,了解一些关于功能单元的操作、能力、延迟和发射时间等方面的知识,可以建立一个基准,用于预测程序的性能。
其他的工具
Valgrind
Valgrind是一个开源的内存调试和性能分析工具集,主要用于检测内存泄漏、内存错误和线程错误等问题。它提供了一系列的工具,包括Memcheck、Cachegrind、Callgrind、Helgrind和Massif等。
其中,最常用的工具是Memcheck,它是Valgrind的默认工具。Memcheck可以检测程序中的内存错误,如使用未初始化的内存、访问已释放的内存、内存泄漏等。它通过在运行时对程序进行动态分析,记录和检测内存访问情况,并给出详细的报告。
Cachegrind是另一个常用的工具,用于分析程序的缓存使用情况。它可以显示缓存命中率、缓存行使用情况、缓存访问模式等信息,帮助开发者优化程序的缓存性能。
Callgrind则是用于分析程序的函数调用关系和性能瓶颈的工具。它可以生成函数调用图和函数调用次数、执行时间等信息,帮助开发者找出程序中的热点函数和性能瓶颈。
Helgrind是用于检测多线程程序中的并发错误的工具。它可以检测到线程间的竞争条件、死锁和数据竞争等问题,并提供相应的报告和调试信息。
Massif是用于分析程序的堆内存使用情况的工具。它可以显示程序在不同时间点的堆内存分配情况,帮助开发者找出内存泄漏和内存使用不当的问题。
总之,Valgrind是一个强大的工具集,可以帮助开发者进行内存调试和性能分析,提高程序的质量和性能。
VTune
Intel VTune是一款用于性能分析和调优的工具,它可以帮助开发者了解和改善应用程序的性能。
VTune提供了多种分析方法和工具,包括硬件事件采样、线程分析、内存分析、I/O分析等。它可以在不同层次上进行性能分析,包括应用程序、系统和硬件层面。
使用VTune,开发者可以通过硬件事件采样来了解程序在CPU上的执行情况。它可以收集和分析指令、缓存、分支预测等硬件事件的数据,帮助开发者找出性能瓶颈和优化机会。
线程分析是VTune的另一个重要功能,它可以帮助开发者识别和解决多线程程序中的性能问题。VTune可以分析线程的并发性、同步机制、线程间的竞争条件等,帮助开发者优化多线程程序的性能。
内存分析是VTune的另一个强大功能,它可以帮助开发者找出内存泄漏、内存访问冲突和内存使用不当等问题。VTune可以分析程序的内存分配和释放情况,帮助开发者优化内存使用和减少内存泄漏。
此外,VTune还提供了I/O分析、能耗分析等功能,帮助开发者了解和优化程序的I/O操作和能耗情况。
总之,Intel VTune是一款功能强大的性能分析和调优工具,可以帮助开发者找出性能瓶颈、优化程序的性能,并提高应用程序的质量和效率。
排序
插入排序
插入排序是一种简单直观的排序算法。它的基本思想是将待排序的元素分为已排序和未排序两部分,每次从未排序部分选择一个元素插入到已排序部分的正确位置,直到所有元素都被插入完成。
具体的插入排序算法步骤如下:
- 从第一个元素开始,该元素可以认为已经被排序。
- 取出下一个元素,在已经排序的元素序列中从后向前扫描。
- 如果该元素(已排序)大于新元素,将该元素移到下一位置。
- 重复步骤3,直到找到已排序的元素小于或等于新元素的位置。
- 将新元素插入到该位置后。
- 重复步骤2~5,直到所有元素都被插入到正确的位置。
插入排序的时间复杂度为O(n^2),其中n是待排序元素的个数。它是一种稳定的排序算法,适用于小规模数据或部分有序的数据集。插入排序在实现上比较简单,且对于小规模数据集的排序效率较高。
快速排序可以是升序或降序,具体取决于实现时的比较操作。在快速排序的过程中,根据比较操作将元素分为较小和较大的两部分,然后对这两部分分别进行递归排序。在升序排序中,较小的元素会排在较大的元素之前,而在降序排序中,较大的元素会排在较小的元素之前。因此,通过调整比较操作,可以使快速排序按照升序或降序排列。
快速排序
快速排序是一种常用的排序算法,它采用了分治的策略来对待排序的元素进行排序。快速排序的基本思想是通过一趟排序将待排序的元素分割成独立的两部分,其中一部分的元素都比另一部分小,然后再对这两部分分别进行排序,最终将整个序列排序完成。
具体的快速排序算法步骤如下:
- 从待排序的元素序列中选择一个基准元素(通常选择第一个或最后一个元素)。
- 将序列中的元素分成两部分,比基准元素小的放在左边,比基准元素大的放在右边。这个过程称为分区操作。
- 对左右两个分区重复步骤1和步骤2,直到每个分区只剩下一个元素。
- 最后将所有分区的元素按照顺序合并起来,即得到排序后的序列。
快速排序的时间复杂度为O(nlogn),其中n是待排序元素的个数。它是一种不稳定的排序算法,适用于大规模数据集的排序。快速排序的优势在于它的平均时间复杂度较低,并且在实践中通常比其他排序算法表现更好。然而,最坏情况下快速排序的时间复杂度可能达到O(n^2),这种情况下可以通过优化算法来避免。
links
https://www.cs.cmu.edu/afs/cs/academic/class/15213-f15/www/lectures/10-optimization.pdf















 858
858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









