










CSAPP 第六章读书笔记 part2
Set Associative Caches
A cache with 1<E <C/B is often called an E-way set associative cache.
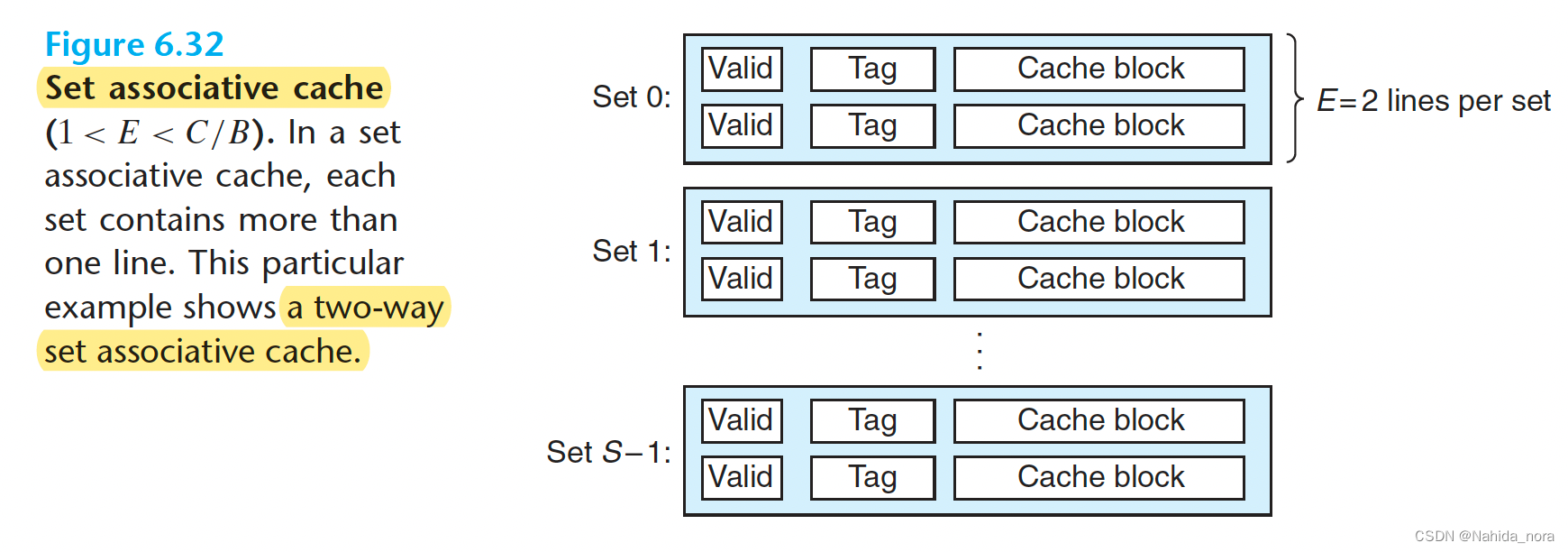
Set Selection in Set Associative Caches
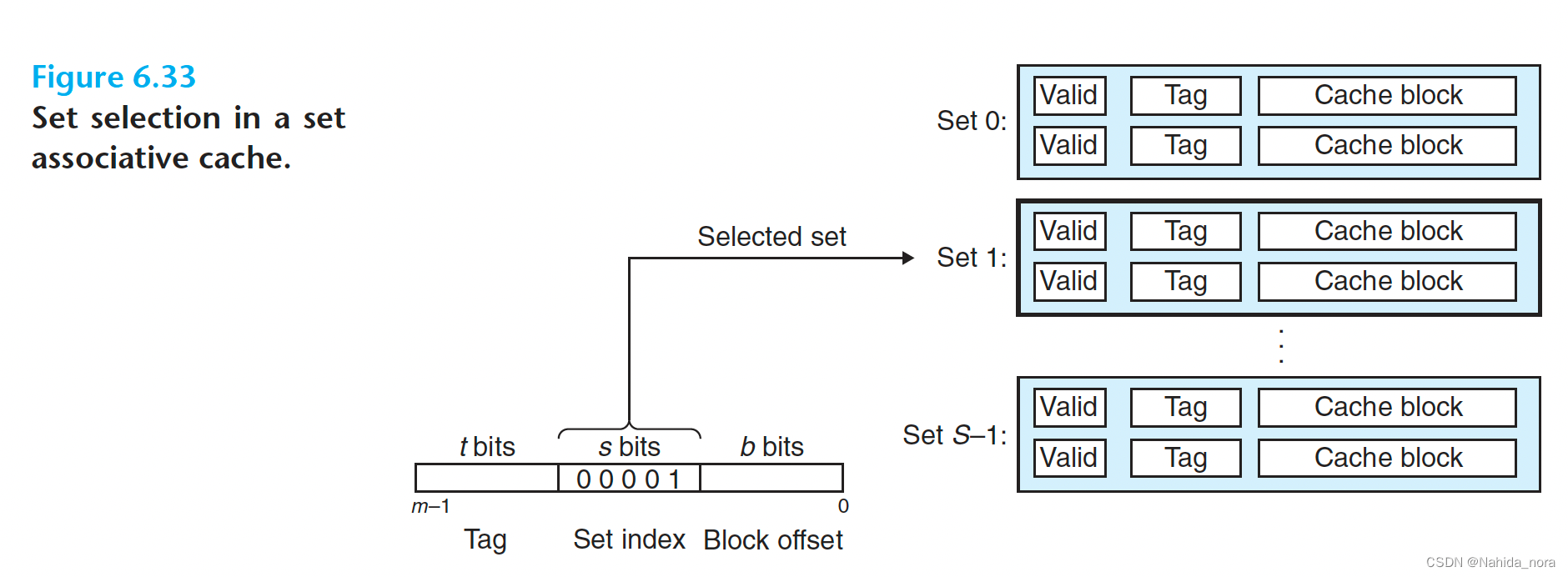
two-way set associative cache
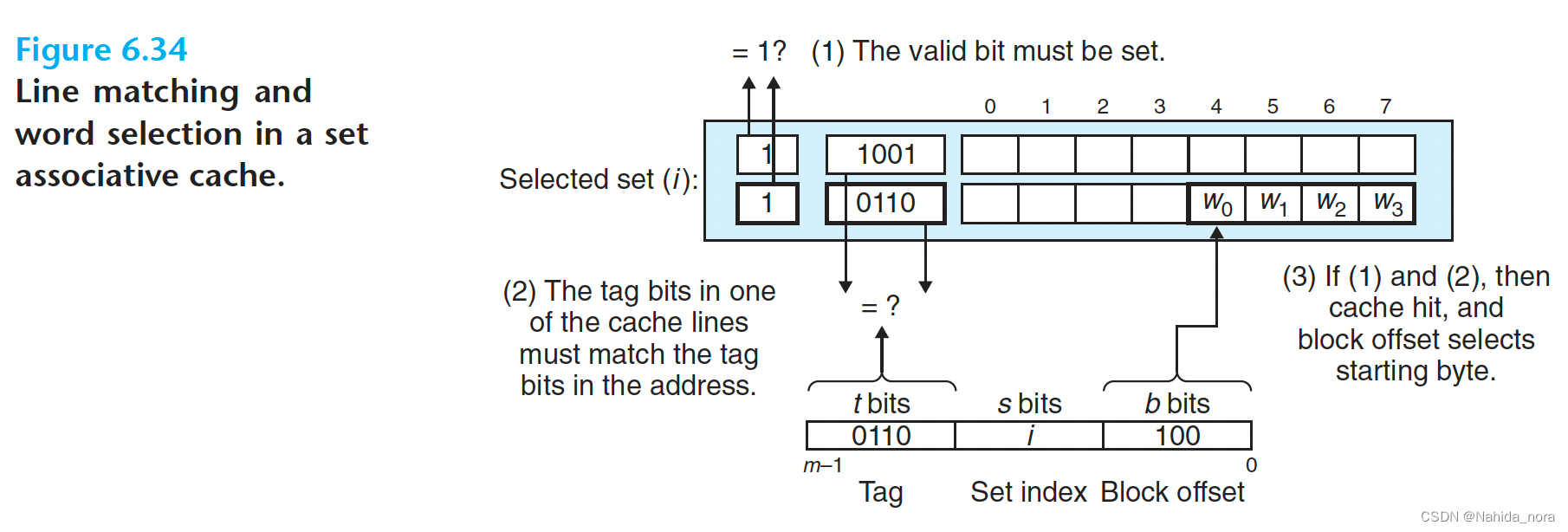
Line Matching and Word Selection in Set Associative Caches
A conventional memory is an array of values that takes an address as input and returns the value stored at that address.
conventional memory
传统内存通常指的是计算机系统中的主存储器,也称为随机存取存储器(RAM)。传统内存是指非持久性的存储介质,其内容在断电后会丢失。传统内存通常包括动态随机存取存储器(DRAM)和静态随机存取存储器(SRAM)。
动态随机存取存储器(DRAM)是一种常见的传统内存类型,它通过电容来存储数据,并且需要周期性地刷新以保持数据的完整性。DRAM具有较高的存储密度和相对较低的成本,但速度较慢。
静态随机存取存储器(SRAM)是另一种常见的传统内存类型,它使用触发器来存储数据,无需刷新操作,并且速度更快。然而,SRAM比DRAM更昂贵且存储密度较低。
传统内存通常用于存储正在运行的程序、操作系统和数据,以便CPU可以快速访问和操作这些信息。传统内存的大小通常受到硬件和操作系统的限制,但是它是计算机系统中至关重要的一部分,直接影响到系统的性能和响应速度。
An associative memory, on the other hand, is an array of (key, value) pairs that takes as input the key and returns a value from one of the (key, value) pairs that matches the input key.
associative memory
关联存储器是一种计算机存储器,它允许数据项被存储在任意位置,并且可以通过数据项的内容而不是地址来检索。这种存储器类型通常用于高速缓存系统中,其中数据可以根据其内容而不是其地址进行检索。关联存储器允许数据项在存储器中的位置不是固定的,而是根据数据的内容进行动态的分配。这种存储器类型通常用于提高存取速度和减少冲突。
每一个set associative caches的set作为一个小的associative memory, key是tag, valid bits, 和block的内容。
介绍下conventional memory 和 associative memory 的区别
传统内存和关联内存的输入和输出有一些区别。
传统内存的输入和输出是通过地址来进行的。当CPU需要读取或写入传统内存中的数据时,它会发送一个地址信号,以指示所需数据的位置。传统内存会根据这个地址信号来读取或写入相应的数据。
关联内存的输入和输出则是通过标签来进行的。关联内存中的数据是通过标签进行检索的,而不是通过具体的地址。当CPU需要访问关联内存中的数据时,它会发送一个标签信号,关联内存会根据这个标签信号来查找匹配的数据。
因此,传统内存和关联内存在输入和输出方面的区别在于,传统内存是通过地址进行访问的,而关联内存是通过标签进行访问的。
Line Replacement on Misses in Set Associative Caches
cache replacement policy
高速缓存替换策略是指在高速缓存中选择哪些块应该被替换掉以便为新的数据块腾出空间。当高速缓存已满并且需要将新的数据加载到其中时,替换策略确定了要被替换的旧数据块。
常见的高速缓存替换策略包括:
- 最近最少使用(Least Recently Used, LRU):根据最近使用的时间来决定哪个块被替换掉。最近被访问的块会被保留在高速缓存中,而最久未被访问的块可能会被替换。
- 先进先出(First-In-First-Out, FIFO):最先被加载到高速缓存中的块会被最先替换掉。
- 随机替换(Random Replacement):随机选择要被替换的块。
- 最少使用(Least Frequently Used, LFU):根据块被访问的频率来决定替换哪个块。
每种替换策略都有其优点和缺点,选择合适的替换策略取决于具体应用场景和性能需求。
Fully Associative Caches

A fully associative cache consists of a single set (i.e., E = C/B) that contains all of the cache lines.
Set Selection in Fully Associative Caches
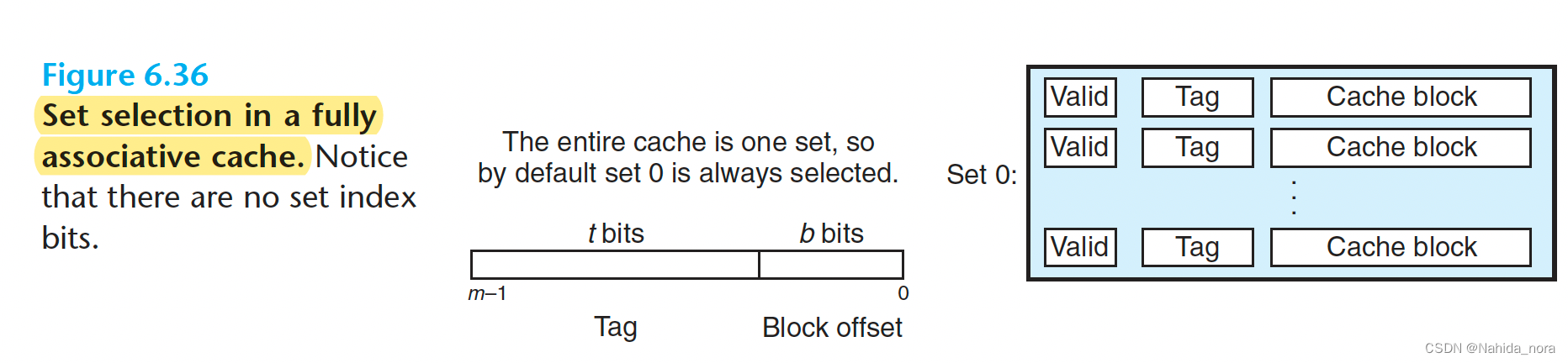
只有一个set, 所以no set index bits in the address
Line Matching and Word Selection in Fully Associative Caches
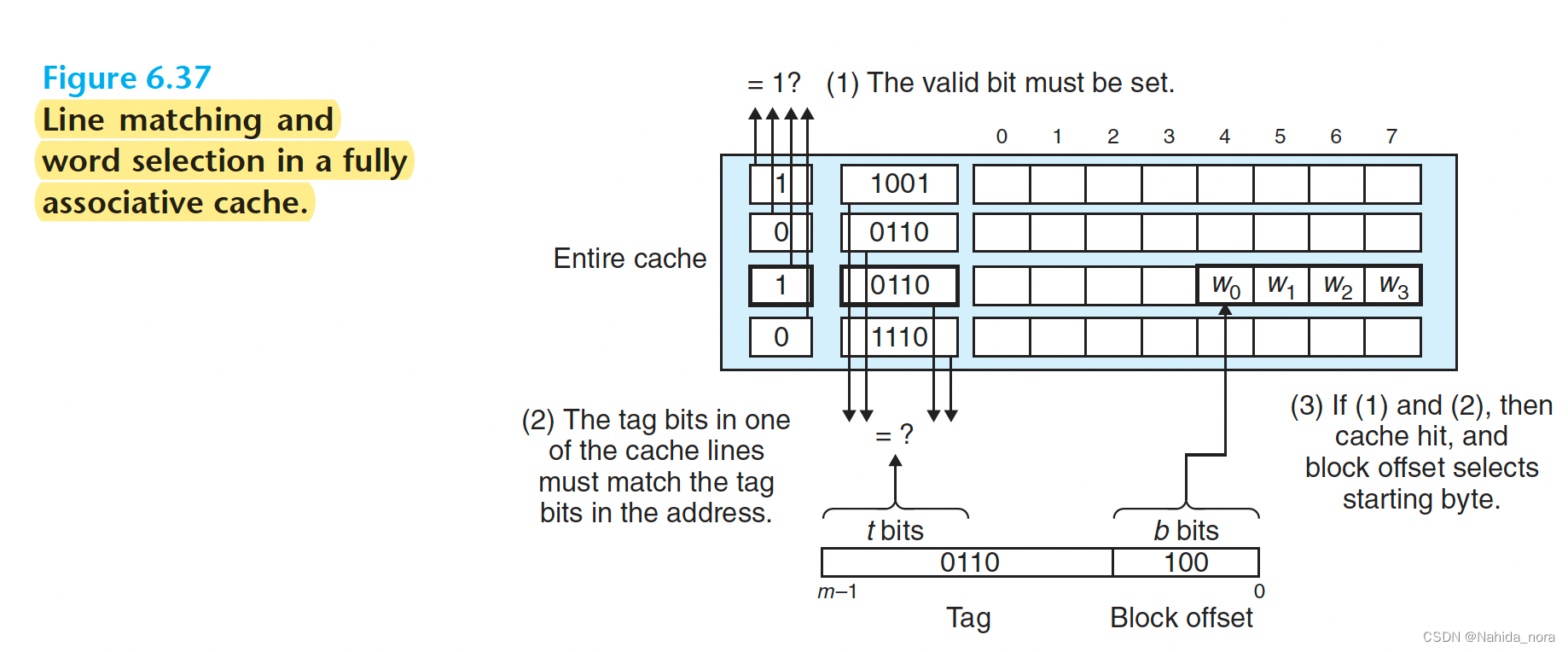
Line matching and word selection 对于fully associative cache 和 set associative cache 是一样的。
区别在于规模, 因为缓存电路必须并行搜索许多匹配的标签,所以构建一个既大又快的关联缓存是困难和昂贵的。因此,全关联缓存只适用于小型缓存,比如虚拟内存系统中缓存页表项的转换后备缓冲区(TLB)(第9.6.2节)。
全关联缓存通常只用于小型缓存,比如虚拟内存系统中的TLB,用于缓存页表项。TLB的大小相对较小,因此可以使用全关联缓存来提高访问速度。
Issues with Writes
因为会对已经缓存的word w进行些操作(write hit), 所以需要考虑如何更新cache和主存的值, 有很多写入策略,最简单的做法是write-through。
write hit的写入策略
write-through
Write-through是一种用于缓存系统的写入策略。在Write-through策略下,每当数据被写入到缓存时,同时也会将数据写入到主存储器中。这意味着写操作会同时更新缓存和主存储器中的数据。
Write-through策略的优点是数据的一致性较高,因为每次写操作都会立即更新主存储器中的数据,确保了缓存和主存储器中的数据保持一致。这对于需要高数据一致性的应用程序非常重要,如数据库系统。
然而,Write-through策略的缺点是写操作的延迟较高。由于每次写操作都需要更新主存储器,写操作的完成时间会受制于主存储器的速度。这可能会导致性能下降,特别是在大量写操作的情况下。
为了解决Write-through策略的性能问题,可以结合使用写缓冲区(write buffer)或写合并(write combining)等技术来优化写操作的延迟。这些技术可以将多个写操作合并为一个较大的写操作,从而减少对主存储器的访问次数,提高写操作的效率。
总而言之,Write-through是一种写入策略,它将写操作同时更新缓存和主存储器中的数据,以提高数据一致性,但可能会导致写操作的延迟较高。
write-back
Write-back是一种用于缓存系统的写入策略。在Write-back策略下,当数据被写入到缓存时,只会更新缓存中的数据,而不会立即将数据写回到主存储器中。相反,缓存会保持被修改的数据,直到该数据被替换出缓存或者在缓存中发生了读取该数据的操作时,才会将数据写回到主存储器。
Write-back策略的主要优点是可以减少对主存储器的写操作次数,从而降低了写操作的延迟,提高了系统的性能。因为在Write-back策略下,只有在数据被替换出缓存或者发生了读取该数据的操作时,才会将数据写回到主存储器,避免了每次写操作都需要更新主存储器的开销。
然而,Write-back策略也存在一定的缺点。由于数据在缓存中被修改后,并不会立即写回到主存储器,可能会导致缓存中的数据与主存储器中的数据不一致,需要额外的机制来维护数据的一致性。此外,如果发生系统崩溃或断电等情况,尚未写回主存储器的数据可能会丢失,造成数据完整性问题。
因此,在使用Write-back策略时,需要仔细考虑数据一致性和系统可靠性的问题,并采取相应的措施来确保数据的完整性和一致性。
write miss的写入策略
write-allocate
Write-allocate是一种缓存写入策略,通常与缓存系统的写操作相关。在使用Write-allocate策略时,如果需要写入的数据不在缓存中,系统会首先将相应的数据块从主存储器读取到缓存中,然后再在缓存中进行写操作。
这种策略的优点在于,即使数据不在缓存中,仍然会首先将数据加载到缓存中进行写操作,这有助于提高写操作的性能和效率。因为在Write-allocate策略下,写操作总是在缓存中进行,而不是直接写入主存储器,从而减少了对主存储器的访问次数,提高了写操作的速度。
然而,Write-allocate策略也可能会导致额外的读操作,因为如果需要写入的数据不在缓存中,就需要先将数据加载到缓存中,这可能会增加读操作的开销。此外,如果写操作的数据块很大,可能会占用较多的缓存空间,从而影响到其他数据的缓存命中率。
总的来说,Write-allocate策略适合于写操作较为频繁且数据块较小的情况,可以提高写操作的性能和效率。但在一些特定的场景下,可能需要权衡考虑数据块的大小、缓存空间的利用率等因素,以确定是否采用Write-allocate策略。
no-write-allocate
No-write-allocate是一种缓存写入策略,与Write-allocate相对应。在使用No-write-allocate策略时,如果需要写入的数据不在缓存中,系统会直接将数据写入主存储器,而不是先将数据加载到缓存中再进行写操作。
这种策略的优点在于,可以减少对缓存的读操作,因为如果需要写入的数据不在缓存中,就会直接写入主存储器,避免了额外的读操作。这有助于提高写操作的效率,尤其是对于大数据块的写操作,可以减少对缓存空间的占用,提高了缓存的利用率。
然而,No-write-allocate策略可能会导致写操作的性能较低,因为每次写操作都需要直接访问主存储器,可能会增加写操作的延迟。此外,如果写操作的数据块较小,可能会导致频繁的主存储器访问,影响系统整体的性能。
总的来说,No-write-allocate策略适合于写操作相对较少或者写操作的数据块较大的情况,可以减少对缓存的读操作,提高了缓存的利用率。但在一些特定的场景下,可能需要权衡考虑写操作的频率、数据块的大小等因素,以确定是否采用No-write-allocate策略。
本书作者建议采用一种模型,假设采用写回、写分配的缓存。这一建议有几个原因:一般来说,存储器层次结构中较低级的缓存更有可能采用写回(write-back)而不是写直通(write-through),因为传输时间更长。例如,虚拟内存系统(使用主存储器作为磁盘上存储块的缓存)完全使用写回。但随着逻辑密度的增加,写回的复杂性变得不再是障碍,在现代系统的所有级别都看到了写回缓存。因此,这种假设符合当前的趋势。假设采用写回、写分配方法的另一个原因是,它对读取处理的对称性,即写回、写分配试图利用局部性(locality)。因此,在高层次上开发的程序,以展现良好的空间和时间局部性,而不是试图针对特定的存储器系统进行优化。
Anatomy of a Real Cache Hierarchy
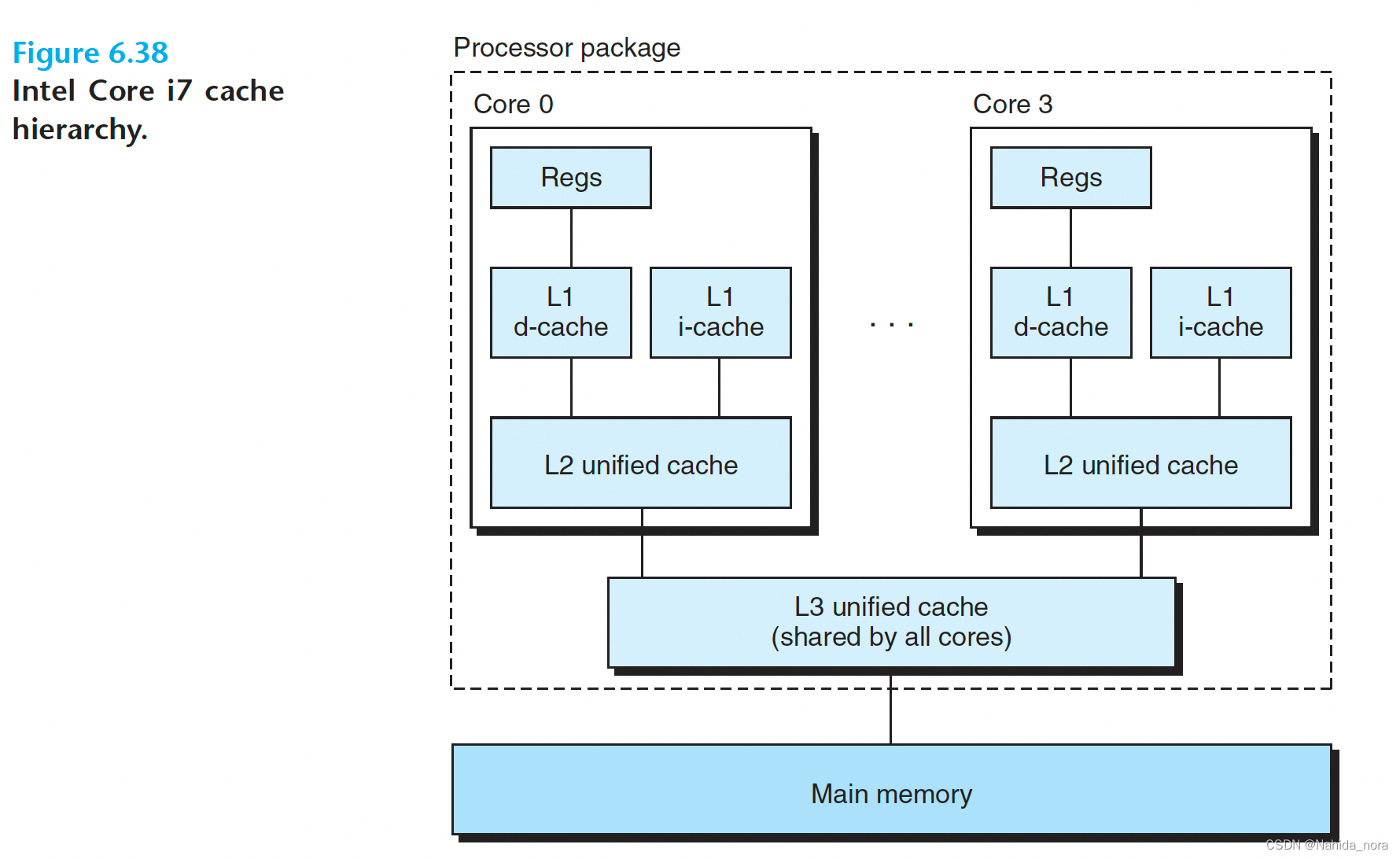
cache 不仅缓存程序数据,也缓存指令。i-cache缓存指令。d-cache缓存程序数据。unified cache既能缓存程序数据也能缓存指令。
现代处理器包括独立的指令缓存(i-cache)和数据缓存(d-cache)。这样做有几个原因。通过两个独立的缓存,处理器可以同时读取指令字(instruction word)和数据字(data word)。指令缓存通常是只读的,因此更简单。两个缓存通常针对不同的访问模式进行优化,并且可以具有不同的块大小、关联度和容量。此外,独立的缓存确保数据访问不会与指令访问产生冲突缺失,反之亦然,但可能会增加容量缺失的可能性。
图6.38显示了Intel Core i7处理器的缓存层次结构。每个CPU芯片有四个核心。每个核心都有自己的私有L1指令缓存、L1数据缓存和L2统一缓存。所有核心共享一个片上L3统一缓存。这个层次结构的一个有趣特点是,所有的SRAM缓存存储器都包含在CPU芯片中。
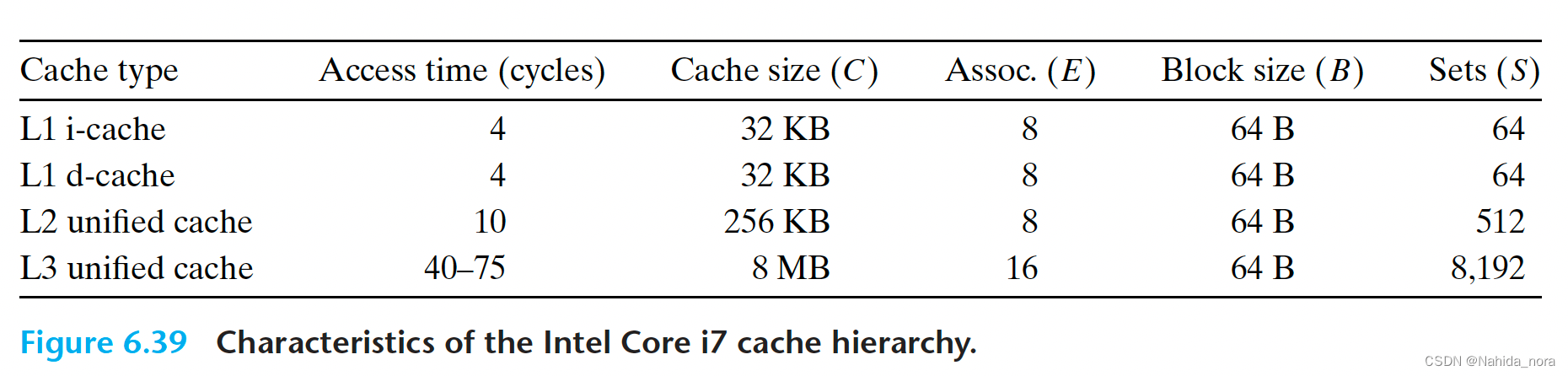
图6.39总结了Core i7缓存的基本特性。
SRAM cache memories
SRAM(静态随机存储器)缓存存储器通常位于CPU芯片上,而不是主存储器或其他外部存储器中,有以下几个原因:
-
访问速度:SRAM具有快速的访问速度和低延迟,这使得它非常适合作为缓存存储器使用。将缓存存储器放置在CPU芯片上可以减少访问延迟,从而提高处理器的性能。
-
带宽:将缓存存储器放置在CPU芯片上可以通过高速的内部总线和连接器提供更大的带宽,从而更有效地传输数据。
-
电源消耗:SRAM相对于其他存储器技术(如DRAM)来说,功耗较低。将缓存存储器放置在CPU芯片上可以减少功耗,提高能效。
-
空间效率:将缓存存储器集成到CPU芯片上可以节省空间,并减少芯片之间的连接线路,从而提高整体系统的紧凑性和可靠性。
综上所述,将SRAM缓存存储器放置在CPU芯片上是为了提供更快的访问速度、更大的带宽、更低的功耗和更高的空间效率,以提高处理器的性能和整体系统的效能。
SRAM
SRAM(静态随机存储器)一般用作高速缓存存储器,特别是在计算机系统中。它通常用于存储处理器的指令和数据,以提供快速的访问速度和低延迟。
SRAM的快速访问速度和低功耗使其成为处理器缓存的理想选择。处理器缓存是一种位于处理器内部的小型存储器,用于暂时存储最常用的指令和数据,以减少对主存储器的访问次数。通过将数据存储在SRAM缓存中,处理器可以更快地访问和处理数据,从而提高系统的性能和响应速度。
除了作为处理器缓存,SRAM还可以用于其他需要快速访问和低功耗的应用,如网络路由器、嵌入式系统、图形处理器(GPU)等。在这些应用中,SRAM通常用于存储临时数据、缓冲区和数据缓存,以支持高速数据处理和传输。
Main memory
主存储器一般指的是计算机系统中用于存储程序和数据的主要存储设备,也称为RAM(随机存取存储器)。主存储器通常是由DRAM(动态随机存储器)组成,而不是SRAM(静态随机存储器)。
DRAM和SRAM都是随机存取存储器,但它们有一些关键区别。SRAM比DRAM更快,但也更昂贵,并且占用更多的空间。因此,SRAM通常用于高速缓存存储器,而DRAM用于主存储器,因为DRAM可以提供更大的存储容量,并以更低的成本实现。
总的来说,主存储器一般是由DRAM组成,而不是SRAM。
Performance Impact of Cache Parameters
缓存性能是通过多个指标来评估的:
缺失率(Miss rate):在程序执行过程中或某个部分中,缺失的内存引用占总引用的比例。计算公式为: 缺失次数/引用次数。
命中率(Hit rate):命中的内存引用占总引用的比例。计算公式为: 1 - 缺失率。
命中时间(Hit time):将缓存中的数据(word)传递给CPU所需的时间,包括集合选择(set selection)、行识别(line identification)和字选择(word selection)的时间。对于L1缓存,命中时间大约为几个时钟周期。
缺失惩罚(Miss penalty):由于缺失(cache miss)而需要额外的时间。L1缓存从L2缓存获取数据的惩罚大约为10个周期;从L3缓存获取数据的惩罚为50个周期;从主存获取数据的惩罚为200个周期。
优化缓存内存的成本和性能权衡是一个复杂的过程,需要在真实的基准代码上进行广泛的模拟。比较复杂,但是可以考虑一些可以量化的trade-offs:
- Impact of Cache Size: 一方面,较大的缓存往往会增加命中率。另一方面,让较大的内存运行速度更快总是更加困难的。因此,较大的缓存往往会增加命中时间。这解释了为什么L1缓存比L2缓存小,而L2缓存比L3缓存小。
- Impact of Block Size: 较大的块有好有坏。一方面,较大的块可以通过利用程序中可能存在的空间局部性来增加命中率。然而,对于给定的缓存大小,较大的块意味着较少的缓存行数,这可能会降低具有更多时间局部性而不是空间局部性的程序的命中率。较大的块还会对缺失惩罚产生负面影响,因为较大的块导致较长的传输时间。像Core i7这样的现代系统使用包含64字节的缓存块来权衡这一问题。
- Impact of Associativity: 问题在于参数E的选择对缓存每组的缓存行数的影响。更高的关联度(即E的较大值)的优势在于它减少了由于冲突缺失而导致的缓存抖动的脆弱性。然而,更高的关联度会带来显著的成本。更高的关联度实现起来更昂贵,速度更难提高。它需要每行更多的标记位、每行额外的LRU状态位和额外的控制逻辑。更高的关联度可以增加命中时间,因为由于复杂性的增加,它也可以增加缺失惩罚,以选择受害者行。关联度的选择最终归结为命中时间和缺失惩罚之间的权衡。传统上,推动时钟频率的高性能系统会选择较小的关联度用于L1缓存(其中缺失惩罚仅为几个周期),而较低级别的缓存则选择更高的关联度,因为那里的缺失惩罚更高。例如,在英特尔Core i7系统中,L1和L2缓存是8路关联的,而L3缓存是16路关联的。
- Impact of Write Strategy: 写穿透缓存(Write-through caches)更容易实现,并且可以使用独立于缓存的写缓冲区(write buffer)来更新内存。此外,读缺失(read misses)的成本更低,因为它们不会触发内存写操作。另一方面,写回缓存会导致更少的传输,这可以为执行DMA的I/O设备提供更多的内存带宽。此外,随着我们向下移动层次结构并且传输时间增加,减少传输次数变得越来越重要。一般来说,层次结构中较低级别的缓存更有可能使用写回而不是写穿透。
DMA
DMA(Direct Memory Access,直接内存访问)是一种计算机技术,用于在不需要CPU干预的情况下,直接将数据在外部设备和内存之间传输。DMA可以提高数据传输的效率,减少CPU的负担,并允许CPU同时执行其他任务。
在传统的I/O操作中,数据的传输通常需要CPU的介入。CPU需要从外部设备读取数据,并将其存储到内存中,或者从内存中读取数据,并将其发送到外部设备。这样的数据传输过程需要消耗大量的CPU时间和资源。
而DMA技术通过直接访问内存,绕过CPU,实现数据的直接传输。在DMA控制器的管理下,外部设备可以直接读取或写入内存中的数据,而无需CPU的干预。DMA控制器负责管理数据传输的地址、计数和控制信号,以及处理传输过程中的错误和中断。
使用DMA进行数据传输的好处包括:
- 提高传输速度:由于无需CPU的干预,DMA可以实现高速的数据传输,从而提高系统的整体性能。
- 减轻CPU负担:CPU无需花费大量时间和资源来处理数据传输,可以同时执行其他任务。
- 支持大容量数据传输:DMA可以处理大容量的数据传输,例如音频、视频和图像等。
DMA常用于需要高速数据传输的应用中,如音频和视频处理、磁盘读写、网络数据传输等。现代计算机系统通常都配备了DMA控制器,以支持高效的数据传输。
Writing Cache-Friendly Code
cache friendly:
- Make the common case go fast: 关注影响运行时间的函数的loop
- Minimize the number of cache misses in each inner loop: cache miss 越低性能越好

这个函数是“cache friendly”(对缓存友好)的。首先,注意到在循环体中,局部变量i和sum与时间局部性有很好的关联。事实上,由于这些是局部变量,任何合理的优化编译器都会将它们缓存在寄存器文件中,这是内存层次结构中最高级别的存储器。现在考虑对向量v的步长为1的引用。一般来说,如果缓存的块大小为B字节,那么步长为k的引用模式(其中k以字为单位)会导致每次循环迭代平均发生min (1, (word size × k)/B)次缺失。对于k = 1,这个值最小,所以对v的步长为1的引用确实是对缓存友好的。例如,假设v是块对齐的,字长为4字节,缓存块为4个字,并且缓存最初为空(冷缓存)。然后,无论缓存的组织方式如何,对v的引用将导致以下命中和缺失的模式
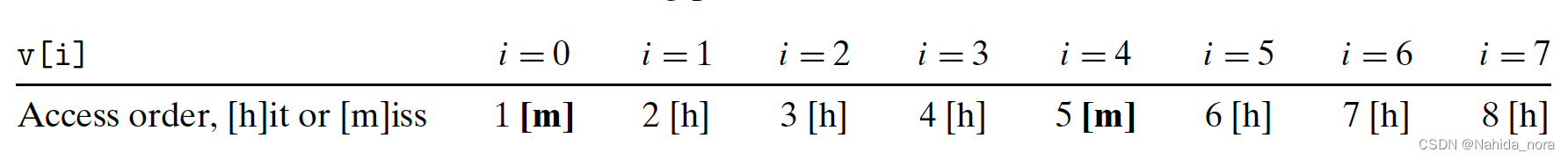
在这个例子中,对v[0]的引用缺失,包含v[0]–v[3]的块从内存加载到缓存中。因此,接下来的三个引用都是命中。对v[4]的引用导致另一个缺失,因为新的块从内存加载到缓存中,接下来的三个引用都是命中,依此类推。一般来说,四个引用中有三个会命中,这是在这种情况下使用冷缓存的最佳结果。
总结一下,我们简单的sumvec示例说明了编写对缓存友好代码的两个重要点:
- 对局部变量的重复引用是好的,因为编译器可以将它们缓存在寄存器文件中(时间局部性)。
- 步长为1的引用模式是好的,因为内存层次结构中所有级别的缓存都将数据存储为连续的块(空间局部性)。
空间局部性在操作多维数组的程序中尤为重要。例如,考虑在第6.2节中介绍的以行优先顺序对二维数组求和的sumarrayrows函数:

由于C以行优先顺序存储数组,该函数的内部循环具有与sumvec相同的理想步长为1的访问模式。例如,假设我们对缓存做出与sumvec相同的假设。那么对数组a的引用将导致以下命中和缺失的模式:
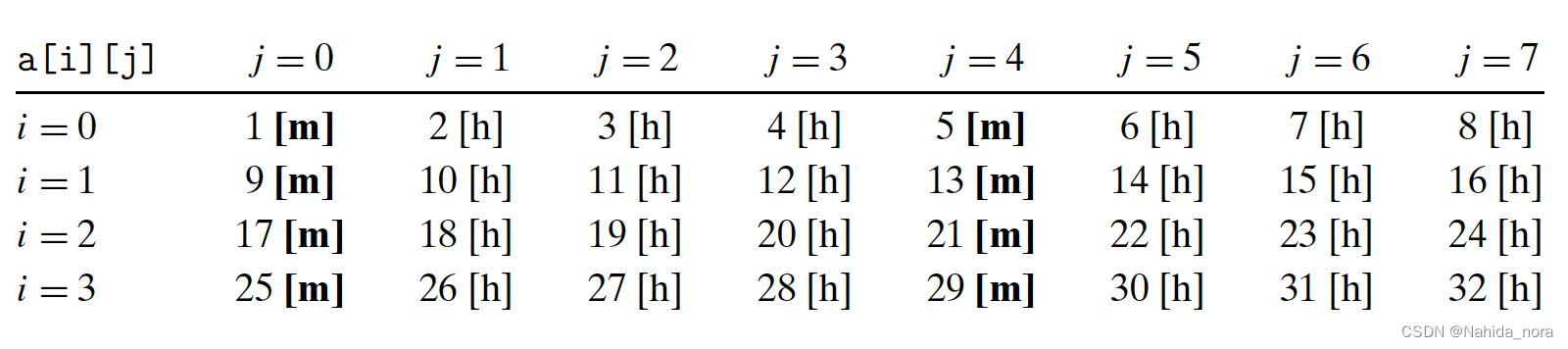
不按照行访问,按照列访问:

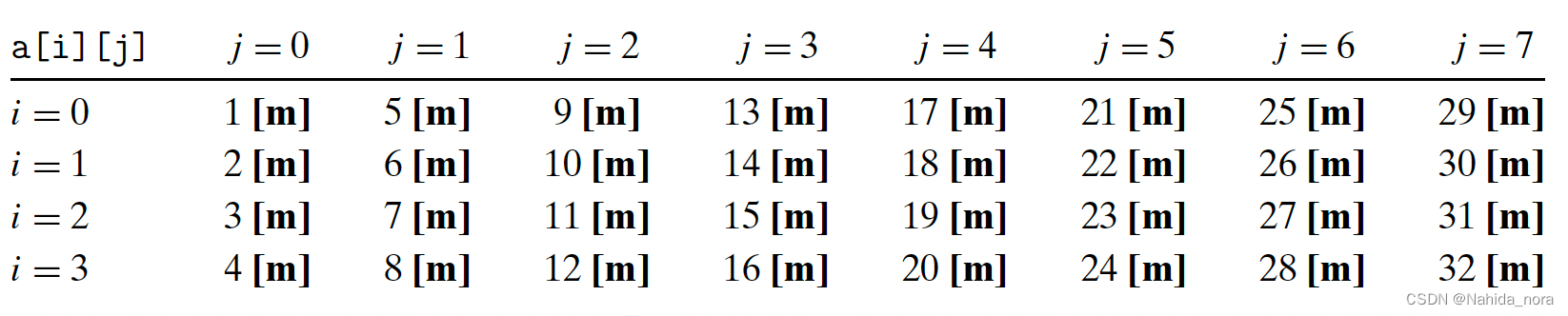
在这种情况下,按列而不是按行扫描数组。如果整个数组适合缓存,那么我们将享受相同的1/4的缺失率。然而,如果数组大于缓存(更有可能的情况),那么每次访问a[i][j]都会缺失!
较高的缺失率对运行时间有显著影响。例如,在我们的台式机上,对于较大的数组大小,sumarrayrows的运行速度比sumarraycols快25倍。总之,程序员应该意识到程序中的局部性,并尽量编写能够利用局部性的程序。




register file
寄存器文件(Register File)是计算机体系结构中的一种重要组件,用于存储和操作CPU中的寄存器数据。它是一个高速的、可读写的存储器,用于存储CPU中的寄存器值。
寄存器文件通常由多个寄存器组成,每个寄存器都有一个唯一的编号或地址。它们可以用于存储临时数据、操作数、地址等。寄存器文件的大小和组织方式取决于特定的计算机体系结构。
寄存器文件具有以下特点和功能:
- 高速访问:寄存器文件通常是位于CPU内部的高速存储器,可以快速读取和写入寄存器的值。这使得寄存器文件成为存储临时数据和操作数的理想选择,以便CPU能够快速访问和处理这些数据。
- 并行操作:寄存器文件中的多个寄存器可以同时读取和写入,从而支持并行操作。这对于同时执行多条指令或多个线程非常重要,可以提高计算机的并行性和性能。
- 快速数据传输:寄存器文件通常与CPU的执行单元直接相连,可以快速传输数据。这使得寄存器文件成为CPU内部数据传输的关键组件,可以有效地支持指令的执行和数据的处理。
- 寄存器操作:寄存器文件支持各种寄存器操作,如读取、写入、加载、存储、清零等。这些操作可以通过特定的指令或指令序列来实现,以实现对寄存器文件的操作和控制。
- 上下文切换:寄存器文件可以用于保存和恢复CPU的上下文信息,包括程序计数器、状态寄存器、通用寄存器等。这对于实现多任务处理和上下文切换非常重要。
寄存器文件在计算机体系结构中起着重要的作用,它提供了高速访问和操作CPU中的寄存器数据的能力。通过合理设计和优化寄存器文件,可以提高计算机的性能和效率。
介绍下计算机的register file 和 缓存的关系
寄存器文件(Register File)和缓存(Cache)是计算机系统中两个不同的存储组件,它们在计算机的层次结构中扮演不同的角色,但也存在一定的关系。
寄存器文件是位于CPU内部的高速存储器,用于存储和操作CPU中的寄存器数据。它具有快速访问、并行操作和快速数据传输等特点,用于存储临时数据、操作数和地址等。寄存器文件的容量通常较小,但访问速度非常快。
缓存是位于CPU和主存之间的中间存储器,用于加速对主存的访问。它通过存储最近使用的数据和指令,以便CPU能够更快地访问这些数据,而不必每次都从主存中读取。缓存的容量通常比寄存器文件大,但访问速度比主存快,但比寄存器文件慢。
寄存器文件和缓存之间存在一定的关系:
- 数据传输:寄存器文件用于存储和传输CPU中的寄存器数据,而缓存用于存储和传输主存中的数据。当CPU需要读取或写入数据时,它首先会查找寄存器文件,如果数据不在寄存器文件中,则会继续在缓存中查找。如果数据也不在缓存中,则需要从主存中加载数据。
- 数据共享:寄存器文件是CPU内部的私有存储器,每个CPU核心都有自己的寄存器文件。而缓存是共享的,多个CPU核心可以同时访问和共享缓存中的数据。这样可以提高数据的共享和利用效率,减少对主存的访问。
- 访问速度:寄存器文件的访问速度比缓存更快,因为寄存器文件位于CPU内部,与CPU核心直接相连。而缓存的访问速度比主存更快,但比寄存器文件慢。因此,CPU会首先尝试从寄存器文件中读取数据,然后再尝试从缓存中读取数据。
- 层次结构:寄存器文件和缓存都是计算机系统中存储组件的一部分,它们在计算机的层次结构中处于不同的层次。寄存器文件位于最高层,是最快速的存储器,用于存储最常用的数据。而缓存位于主存和寄存器文件之间,用于加速对主存的访问。
总之,寄存器文件和缓存在计算机系统中扮演不同的角色,但也存在一定的关系。它们都用于存储和传输数据,但寄存器文件更接近CPU核心,而缓存更接近主存。它们共同助力于提高计算机的性能和效率。
寄存器文件和寄存器的关系
寄存器文件(Register File)和寄存器在计算机体系结构中有密切的关系。寄存器文件可以看作是存储和管理寄存器的组件。
寄存器是CPU中的一种特殊的高速存储器,用于存储和操作临时数据、操作数和地址等。寄存器是CPU内部的存储器,与CPU核心直接相连,可以快速读取和写入数据。
寄存器文件是一个包含多个寄存器的存储器组件。它是CPU中的一个重要组成部分,用于存储和管理寄存器数据。寄存器文件通常由多个寄存器组成,每个寄存器都有一个唯一的编号或地址。寄存器文件可以支持对多个寄存器同时进行读取和写入操作,从而实现并行操作。
寄存器文件和寄存器之间的关系可以总结如下:
- 寄存器文件存储寄存器数据:寄存器文件用于存储和管理CPU中的寄存器数据。寄存器文件中的每个寄存器都可以存储一个特定的值,如临时数据、操作数等。
- 寄存器文件提供寄存器操作:寄存器文件支持对寄存器的各种操作,如读取、写入、加载、存储、清零等。这些操作可以通过特定的指令或指令序列来实现,以实现对寄存器文件中寄存器的操作和控制。
- 寄存器文件与CPU核心直接相连:寄存器文件位于CPU内部,与CPU核心直接相连,可以快速传输数据。这使得寄存器文件成为CPU内部数据传输的关键组件,可以支持指令的执行和数据的处理。
- 寄存器文件是寄存器的集合:寄存器文件由多个寄存器组成,每个寄存器都有自己的编号或地址。寄存器文件提供了一种组织和管理寄存器的方式,使得CPU可以方便地访问和操作多个寄存器。
总之,寄存器文件和寄存器在计算机体系结构中密切相关。寄存器文件是存储和管理寄存器数据的组件,而寄存器是存储临时数据和操作数等的存储器。通过寄存器文件,CPU可以方便地访问和操作多个寄存器,以实现各种计算和数据处理操作。
寄存器文件有缓存功能吗?
寄存器文件本身并没有缓存功能。寄存器文件是位于CPU内部的高速存储器,用于存储和操作CPU中的寄存器数据。它具有快速访问、并行操作和快速数据传输等特点,但并不涉及数据的缓存。
然而,在某些计算机体系结构中,寄存器文件和缓存可以结合起来使用,以提高计算机系统的性能和效率。这种结合通常是通过将寄存器文件的一部分作为缓存来实现的。这种寄存器文件缓存(Register File Cache)的设计可以在寄存器文件和主存之间增加一层缓存,以加速对寄存器数据的访问。
寄存器文件缓存的工作方式类似于其他缓存。当CPU需要读取或写入寄存器数据时,它首先会查找寄存器文件缓存。如果数据在寄存器文件缓存中,则可以直接读取或写入数据,从而避免了对寄存器文件的访问。如果数据不在寄存器文件缓存中,则需要从寄存器文件中加载数据。
寄存器文件缓存的大小通常比寄存器文件小,但比主存大。它可以存储最常用的寄存器数据,以提高数据的访问速度和效率。寄存器文件缓存通常由硬件逻辑实现,与寄存器文件和CPU核心紧密集成。
需要注意的是,寄存器文件缓存是特定计算机体系结构的设计选择,不是所有计算机系统都会使用寄存器文件缓存。它的使用与计算机的架构和设计有关,不同的计算机体系结构可能具有不同的缓存层次结构和设计方案。
Putting It Together: The Impact of Caches on Program Performance
一个程序从内存系统读取数据的速率被称为读取吞吐量(read throughput),有时也称为读取带宽(read bandwidth)。如果一个程序在s秒内读取了n个字节,那么该时期的读取吞吐量就是n/s,通常以每秒兆字节(MB/s)的单位表示。

如果编写一个程序,从一个紧密的程序循环中发出一系列的读请求,那么测量的读取吞吐量将提供关于该特定读取序列的内存系统性能的一些见解。图6.40显示了一对函数,用于测量特定读取序列的读取吞吐量。
fcyc2函数
fcyc2函数是一个用于估计函数执行时间的函数。它通过测量一系列空循环的执行时间来估计CPU时钟周期的数量。具体来说,fcyc2函数执行以下步骤:
- 初始化计数器:首先,它会执行一次空循环,以便初始化计数器,并确保计数器的值不在缓存中。
- 测量空循环的执行时间:然后,它执行一系列空循环,并测量执行这些空循环所花费的时间。
- 估计CPU时钟周期数量:根据测得的执行时间,fcyc2函数估计CPU时钟周期的数量。这个估计值可以用来度量其他函数的执行时间。
总的来说,fcyc2函数是一个用于测量CPU时钟周期数量的工具函数,它可以帮助我们估计其他函数的执行时间。
测试函数通过以步长stride扫描一个数组的前elems个元素来生成读取序列。为了增加内部循环中的可用并行性,它使用了4×4的展开(第5.9节)。run函数是一个调用测试函数并返回测量的读取吞吐量的包装函数。第37行中对测试函数的调用预热了缓存。第38行中的fcyc2函数使用elems参数调用测试函数,并估计测试函数的运行时间(以CPU周期为单位)。请注意,run函数中的size参数以字节为单位,而测试函数中相应的elems参数以数组元素为单位。此外,请注意,第39行将MB/s计算为10 ^ 6字节/秒,而不是2 ^ 20字节/秒。
mb
MB(兆字节)通常是指1024^2字节,也就是1048576字节 或者 2 ^ 20字节/秒对应的单位也是兆字节每秒(MB/s)。
run函数中的size和stride参数允许我们控制所得到的读取序列中的时间和空间局部性的程度。较小的size值会导致较小的工作集大小,从而获得更好的时间局部性。较小的stride值会导致更好的空间局部性。如果我们重复使用不同的size和stride值调用run函数,那么我们可以恢复一个有趣的二维函数,即读取吞吐量与时间和空间局部性之间的关系。这个函数被称为内存山(memory mountain)。
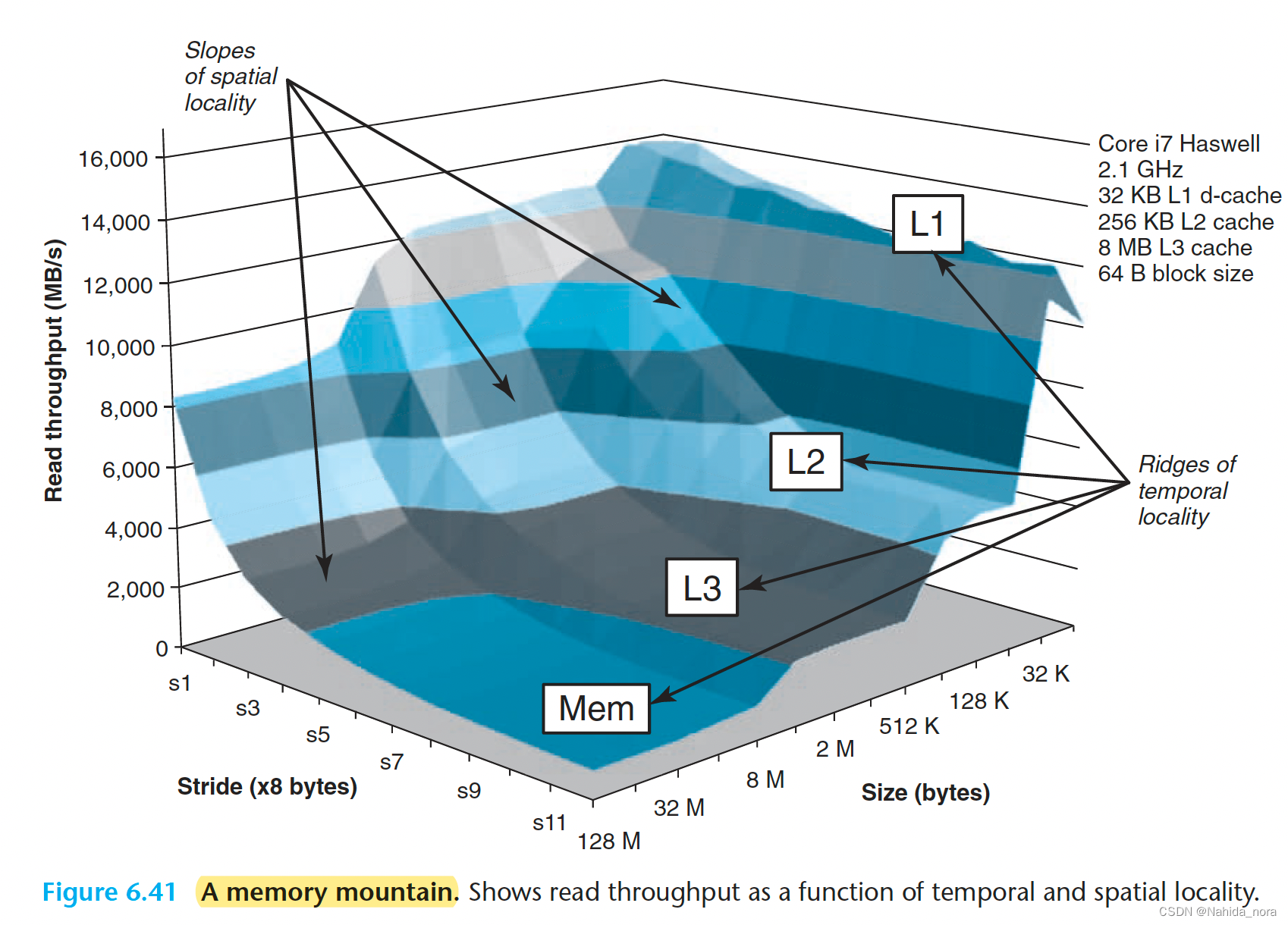
每台计算机都有一个独特的内存山,用来描述其内存系统的能力。例如,图6.41显示了Intel Core i7 Haswell系统的内存山。在这个例子中,size的变化范围从16 KB到128 MB,stride的变化范围从1到12个元素,其中每个元素是一个8字节的长整型。
Core i7山的地理特征揭示了丰富的结构。在size轴的垂直方向上,有四个山脊,分别对应于工作集完全适应L1缓存、L2缓存、L3缓存和主内存的时间局部性区域。请注意,L1山脊的最高峰,CPU的读取速率超过14 GB/s,与主内存山脊的最低点相比,CPU的读取速率为900 MB/s,存在超过一个数量级的差异。
在L2、L3和主内存山脊上,随着步长的增加和空间局部性的减小,存在一个空间局部性的斜坡。请注意,即使工作集太大而无法适应任何缓存,主内存山脊的最高点仍比其最低点高出8个数量级。因此,即使程序具有较差的时间局部性,空间局部性仍然可以起到救命稻草的作用,并产生显着的影响。
有一个特别有趣的平坦山脊线,垂直于步长轴,步长为1时,读取吞吐量相对稳定,约为12 GB/s,即使工作集超过了L1和L2的容量。这显然是由于Core i7内存系统中的硬件预取机制,该机制自动识别顺序步长为1的引用模式,并在访问之前尝试将这些块预取到缓存中。虽然具体的预取算法的细节没有记录,但从内存山可以清楚地看出,该算法对小步长效果最好,这是在代码中偏爱顺序步长为1的访问的又一个原因。
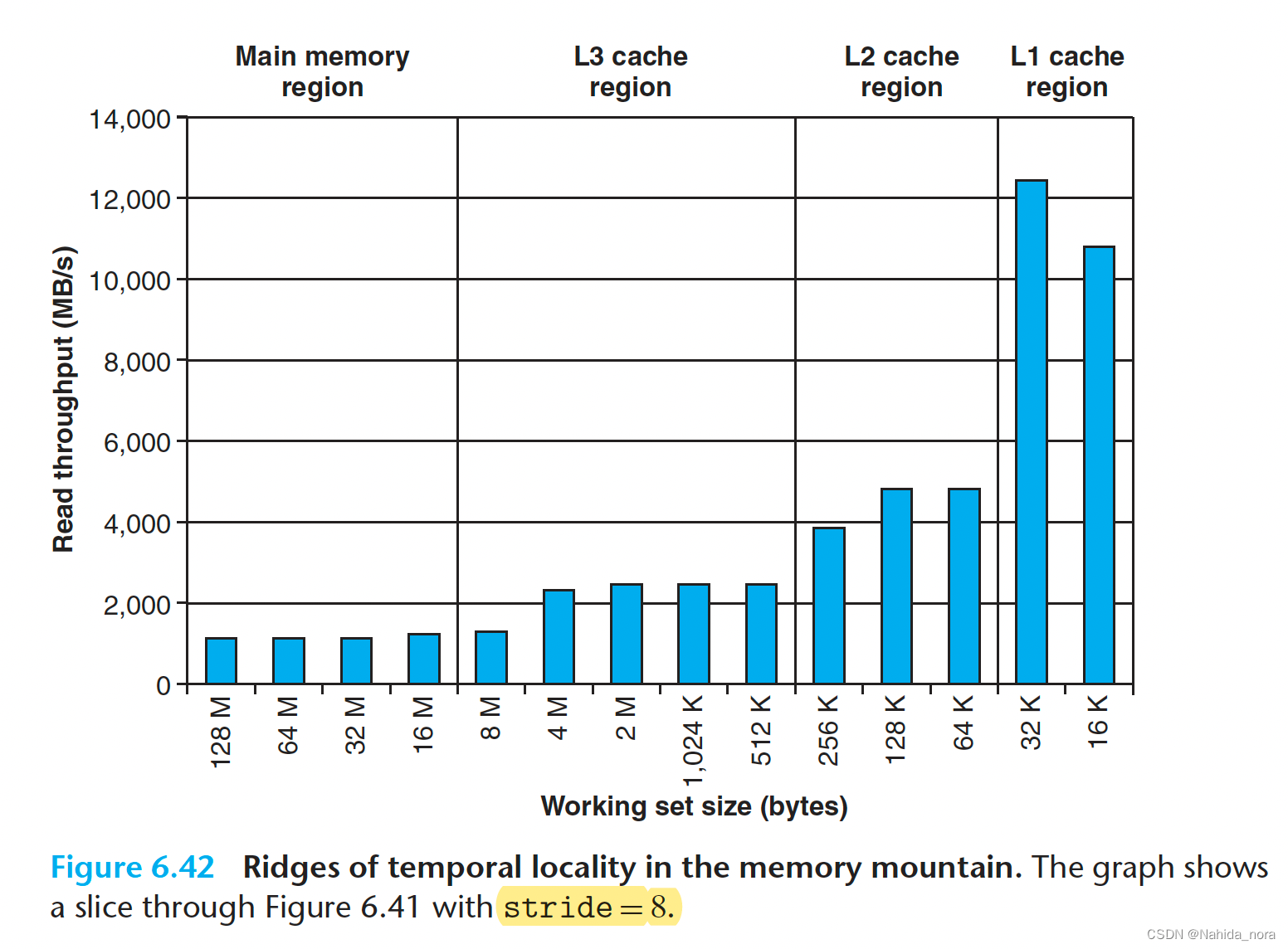
如果我们在山上切割一片,将步长保持恒定,如图6.42所示,我们可以看到缓存大小和时间局部性对性能的影响。对于大小不超过32 KB的工作集,工作集完全适应于L1 d-cache,因此读取通过L1以约12 GB/s的吞吐量提供。对于大小不超过256 KB的工作集,工作集完全适应于统一的L2缓存,对于大小不超过8 MB的工作集,工作集完全适应于统一的L3缓存。较大的工作集主要从主内存中提供。
L2和L3缓存区域最左边边缘的读取吞吐量下降(256 KB和8 MB的工作集大小等于各自的缓存大小)是有趣的。这些下降发生的原因还不完全清楚。唯一确定的方法是进行详细的缓存模拟,但很可能这些下降是由于与其他代码和数据线的冲突引起的。
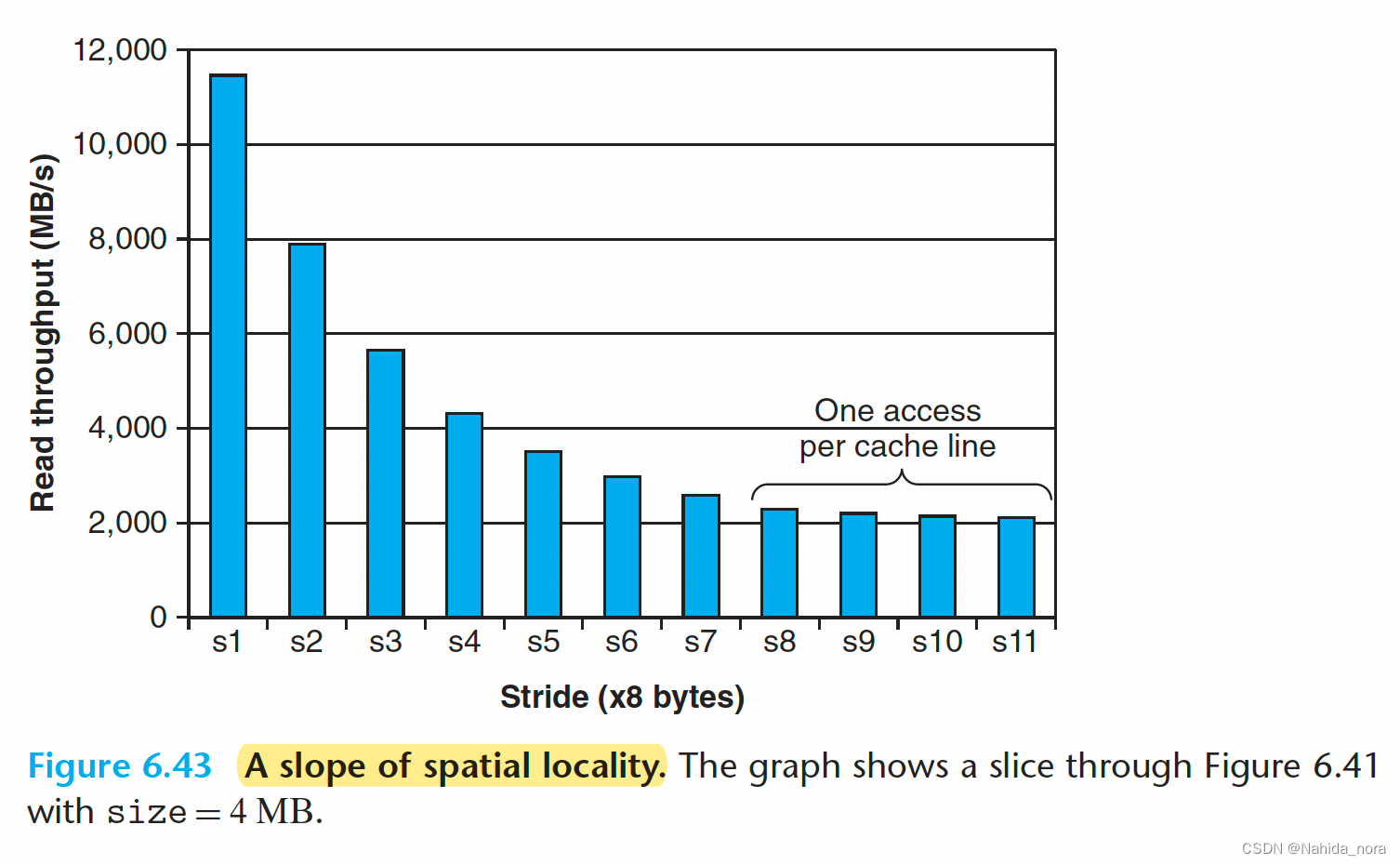
在相反的方向上切割内存山,保持工作集大小恒定,可以让我们对空间局部性对读取吞吐量的影响有一些了解。例如,图6.43显示了固定工作集大小为4MB的切片。这个切片沿着图6.41中的L3山脊切割。在L2缓存中,根据步长的不同,对应的块会有所不同。随着步长的增加,L2缓存未命中与命中的比例也会增加。由于未命中的处理速度比命中慢,读取吞吐量会减少。一旦步长达到了8个8字节的字(在这个系统中等于64字节的块大小),每个读取请求都会在L2缓存中未命中,必须从L3缓存中提供服务。因此,至少为8的步长的读取吞吐量是由从L3缓存传输到L2缓存的缓存块的速率决定的恒定速率。
总结我们对内存山的讨论,内存系统的性能不是由单个数字来描述的。相反,它是一个时间和空间局部性的山脉,其高度可以相差一个数量级。聪明的程序员会尝试结构化他们的程序,使其在高峰而不是低谷运行。目标是利用时间局部性,使频繁使用的字从L1缓存中获取,并利用空间局部性,使尽可能多的字从单个L1缓存行中访问。
Rearranging Loops to Increase Spatial Locality
n * n 矩阵乘法,n 等于2时:
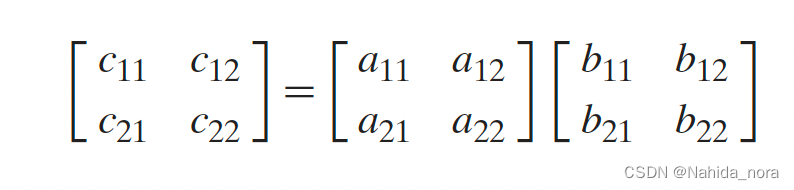
则有:
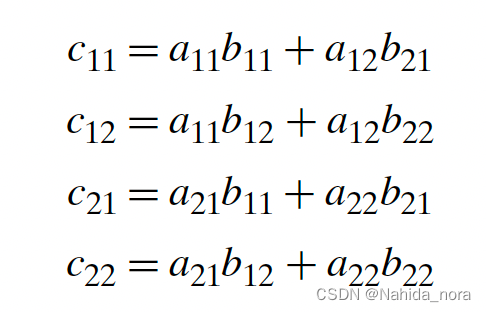
矩阵乘法的算法实现需要3个loop, 通过排列组合遍历i,j,k 的顺序,实现了6种计算矩阵乘法的算法,都是O(N ^3)的算法,但是当研究loop的迭代后,发现局部性(locality) 和 访问(access) 数量不一样,为了进行这种分析,做出以下假设:
- 每个数组都是一个n × n的双精度数组,sizeof(double) = 8。
- 有一个带有32字节块大小(B = 32)的单个缓存。
- 数组大小n非常大,以至于单个矩阵行无法容纳在L1缓存中。
- 编译器将局部变量存储在寄存器中,因此循环内部对局部变量的引用不需要任何加载或存储指令。

根据每个版本的第五行,可以看到最里层的loop, 访问的是不一样的数组,根据最里层的数组值的引用分为3类。
如果缓存的块大小为B字节,那么步长为k的引用模式(其中k以字为单位)会导致每次循环迭代平均发生min (1, (word size × k)/B)次缺失。
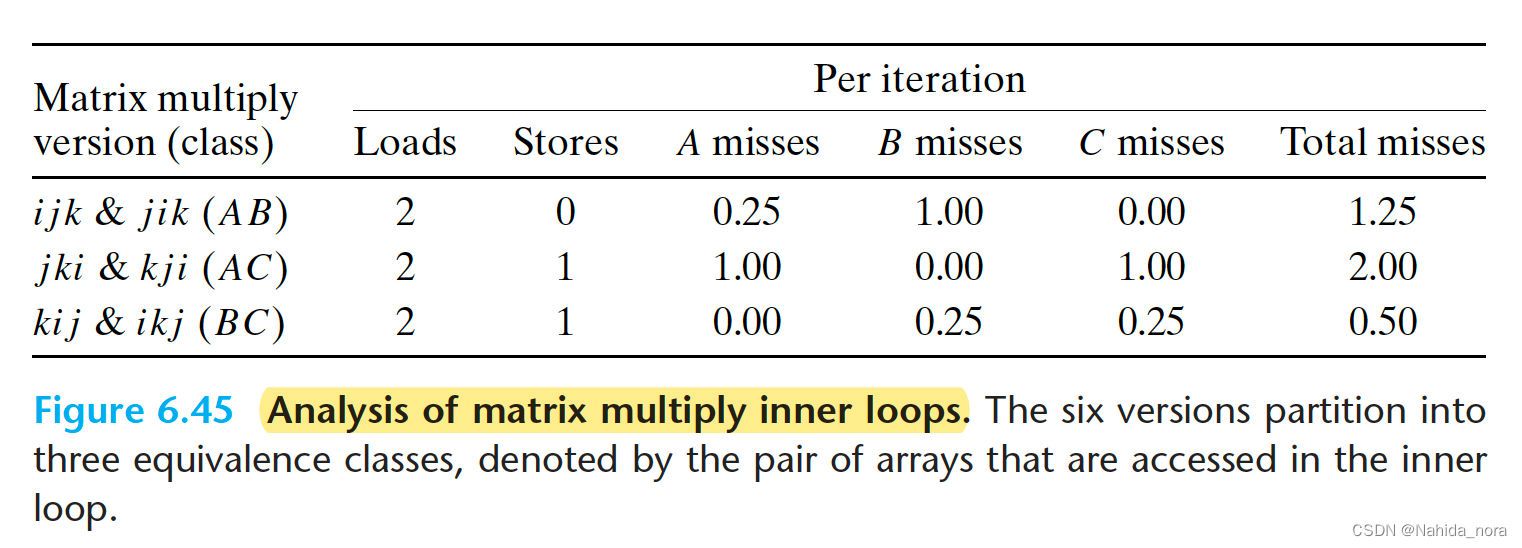
在AB类的内部循环中(图6.44(a)和(b)),使用步长为1来扫描数组A的一行。由于每个缓存块可以容纳四个8字节的数据,所以A的缺失率为每次迭代0.25次缺失。另一方面,内部循环使用步长为n来扫描数组B的一列。由于n很大,每次访问数组B都会导致缺失,因此每次迭代会有1.25次缺失。
在AC类的内部循环中(图6.44©和(d)),存在一些问题。每次迭代执行两次加载和一次存储(与AB类的循环相比,AB类循环执行两次加载而没有存储)。其次,内部循环使用步长为n来扫描数组A和C的列。结果是每次加载都会导致缺失,每次迭代会有两次缺失。注意到与AB类循环相比,交换了循环导致了空间局部性的减少。
BC类的循环(图6.44(e)和(f))呈现出一个有趣的权衡:它们比AB类循环多执行一次内存操作(两次加载和一次存储)。另一方面,由于内部循环以步长1的方式逐行扫描B和C数组,每个数组的缺失率仅为每次迭代0.25次缺失,每次迭代总共有0.50次缺失。
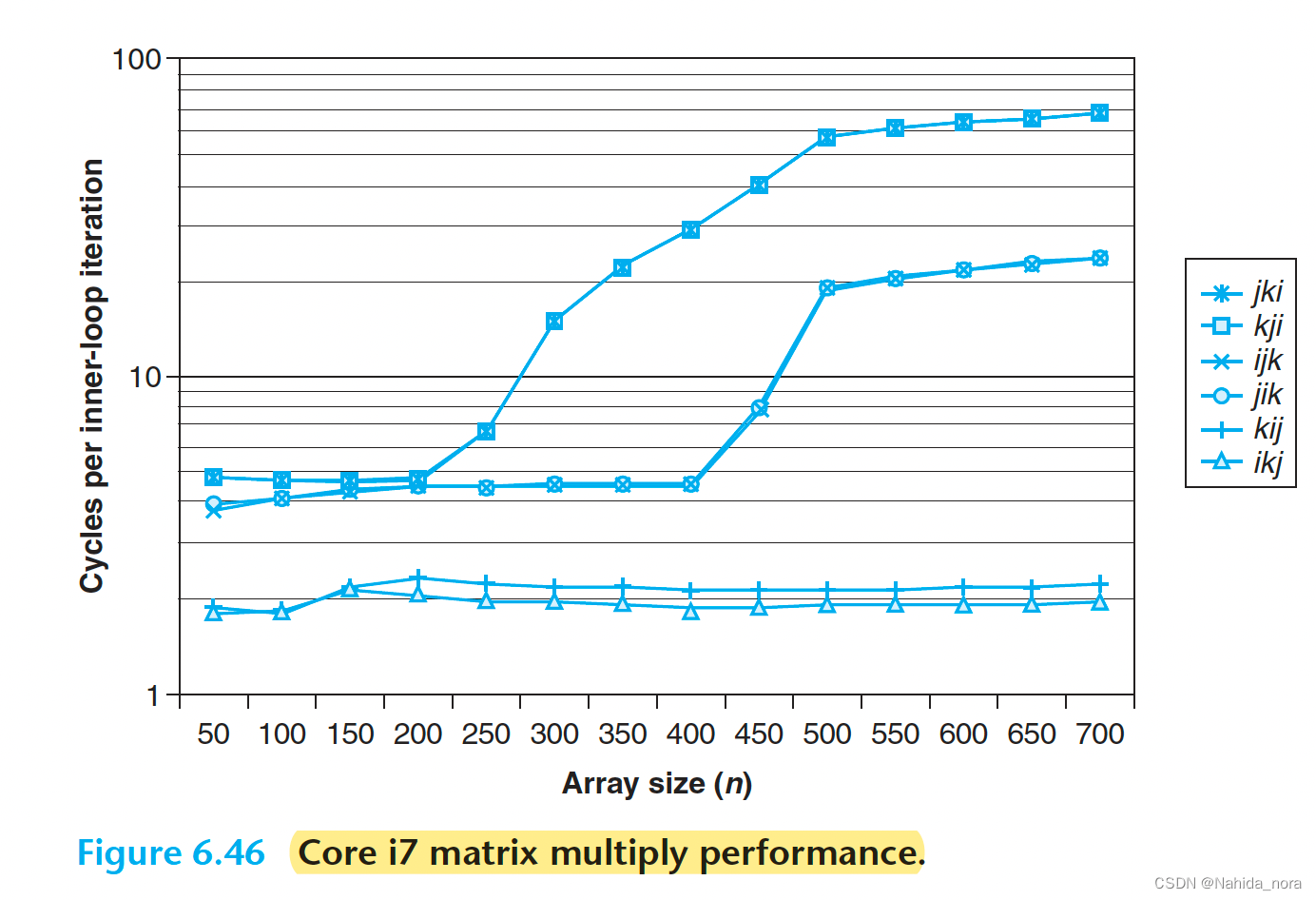
图6.46总结了在Core i7系统上不同版本的矩阵乘法的性能。图中绘制了每个内部循环迭代的CPU周期数与数组大小(n)的关系。
关于这个图表,有一些有趣的观点值得注意:
对于较大的n值,最快版本的运行速度比最慢版本快了近40倍,尽管它们执行相同数量的浮点运算操作。
- 具有相同内存引用和每次迭代缺失次数的版本对应的测量性能几乎相同。
- 在内存行为方面最差的两个版本(以每次迭代的访问次数和缺失次数衡量)比其他四个版本运行速度慢得多,这四个版本具有较少的缺失或较少的访问次数,或者两者都有。
- 矩阵乘法的例子里,缺失率比总的内存访问次数更好地预测性能。例如,BC类循环的每次迭代有0.5次缺失,比AB类循环的每次迭代有1.25次缺失,但BC类循环在内部循环中执行了更多的内存引用(两次加载和一次存储)。
- 对于较大的n值,最快一对版本(kij和ikj)的性能是恒定的。即使数组远大于任何SRAM缓存内存,预取硬件足够智能,能够识别到步长为1的访问模式,并且足够快速以跟上内部循环中的内存访问。这是Intel工程师设计这个内存系统的惊人成就,为程序员提供了更多的动力来开发具有良好空间局部性的程序。
Exploiting Locality in Your Programs
内存系统被组织成一个存储设备的层次结构,顶部是较小、速度较快的设备,底部是较大、速度较慢的设备。由于这种层次结构,程序可以访问内存位置的有效速率不是由一个单一的数字来描述的。相反,它是一个关于程序局部性(称之为内存山)的极其变化的函数,可以相差几个数量级。具有良好局部性的程序大部分数据都从快速缓存中访问。具有较差局部性的程序大部分数据都从相对较慢的DRAM主内存中访问。
了解内存层次结构的程序员可以利用这种理解来编写更高效的程序,而不管具体的内存系统组织如何。推荐以下技术:
- 将注意力集中在内部循环上,因为大部分计算和内存访问都发生在这里。
- 通过按照内存中存储的顺序以步长1顺序读取数据对象,尽量最大化程序中的空间局部性。
- 一旦从内存中读取了数据对象,尽可能多地使用它,以最大化程序中的时间局部性。
Summary
基本的存储技术包括随机存取存储器(RAM)、非易失性存储器(ROM)和磁盘。RAM有两种基本形式。静态RAM(SRAM)速度更快、价格更高,用于缓存存储器。动态RAM(DRAM)速度较慢、价格较低,用于主存和图形帧缓冲区。ROM即使在供电关闭时也能保留其信息。它们用于存储固件。旋转磁盘是机械非易失性存储设备,以低成本每位的方式存储大量数据,但访问时间比DRAM长得多。基于非易失性闪存的固态硬盘(SSD)正在成为某些应用中越来越有吸引力的替代品。
一般来说,速度更快的存储技术每位的成本更高,容量更小。这些技术的价格和性能特性的变化速度截然不同。特别是,DRAM和磁盘的访问时间比CPU周期时间大得多。系统通过将内存组织为存储设备的层次结构来弥合这些差距,顶部是较小、速度较快的设备,底部是较大、速度较慢的设备。由于良好编写的程序具有良好的局部性,大多数数据都从较高级别的存储设备中提供,结果是内存系统以较高级别的速度运行,但以较低级别的成本和容量运行。
程序员可以通过编写具有良好的空间和时间局部性的程序来显著提高程序的运行时间。特别重要的是利用基于SRAM的缓存存储器。从缓存存储器中获取数据的程序比主存中获取数据的程序运行速度要快得多。
主存除了作为缓存,还有哪些功能?
主存(也称为内存)在计算机系统中具有多种功能,其中缓存是其中之一。除了作为缓存,主存还具有以下功能:
- 存储程序和数据:主存用于存储当前正在执行的程序和相关数据。计算机的操作系统、应用程序和用户数据都存储在主存中。
- 数据交换:主存用于数据在计算机内部和外部设备之间的交换。当计算机需要从硬盘、网络或其他外部设备读取或写入数据时,数据通常会通过主存进行中转。
- 内存管理:主存用于存储操作系统和应用程序所需的内存空间。操作系统通过内存管理机制,将可用的物理内存分配给不同的程序和进程,并进行内存保护和内存回收等操作。
- 虚拟内存:主存在虚拟内存系统中发挥重要作用。虚拟内存允许计算机将部分程序和数据存储在主存中,而将其余部分存储在硬盘或其他辅助存储设备上。这样可以扩展可用的内存空间,提高系统性能。
- 数据缓存:主存中的一部分通常被用作数据缓存,以提高计算机系统的性能。数据缓存用于存储最近使用的数据,以便更快地访问。
总的来说,主存不仅用作缓存,还承担着存储程序和数据、数据交换、内存管理和虚拟内存等多种功能。缓存只是其中的一部分。
正在执行的程序的相关数据,没有全部放到cpu里吗?
正在执行的程序的相关数据并非全部放置在CPU中。CPU(中央处理器)是计算机系统的核心,负责执行指令和进行计算操作。虽然CPU中有一级缓存(L1 Cache)用于存储指令和数据,但其容量有限,无法容纳所有正在执行的程序和相关数据。
相反,大部分正在执行的程序和相关数据存储在主存(内存)中。主存是计算机系统中用于存储程序和数据的主要存储器。当程序被执行时,CPU从主存中读取所需的指令和数据,并将其加载到CPU的缓存中进行处理。CPU通过总线(Bus)与主存进行数据交换。
主存的容量通常比CPU的缓存大得多,可以容纳更多的程序和数据。主存的访问速度相对较慢,但比较CPU与硬盘之间的访问速度要快得多。因此,主存在计算机系统中起到了连接CPU和其他外部设备的桥梁作用,提供了临时存储和数据交换的功能。
cpu上有多级缓存,是如何缓存的?缓存什么数据?使用什么缓存策略?
是的,CPU通常具有多级缓存,包括一级缓存(L1 Cache)、二级缓存(L2 Cache)和三级缓存(L3 Cache)。这些缓存层级的目的是提供更快的数据访问速度,以减少对主存的访问。
不同级别的缓存通常具有不同的容量和访问速度。一级缓存是最接近CPU核心的缓存,容量较小但访问速度非常快。二级缓存容量较大,速度稍慢一些。三级缓存是一些高端处理器才具备的,容量更大但速度较慢。
缓存的目标是尽可能存储经常访问的数据,以提高CPU对这些数据的访问速度。缓存通常使用缓存行(Cache Line)的概念来存储数据。缓存行是一块连续的内存区域,通常为64字节或者128字节。当CPU需要读取或写入数据时,它会首先检查缓存行是否包含所需的数据。如果缓存行中包含所需数据,CPU可以直接从缓存中读取,而不需要访问主存。如果缓存行中没有所需数据,CPU会从主存中加载整个缓存行到缓存中,并从中提取所需数据。
缓存使用的策略包括缓存替换策略和缓存写入策略。常见的替换策略有最近最少使用(Least Recently Used,LRU)和随机替换(Random Replacement)。缓存写入策略包括写回(Write Back)和写直达(Write Through)。写回策略是先将数据写入缓存,然后在某个时刻再将数据写回主存。写直达策略是在写入缓存的同时直接写入主存。这些策略的选择取决于缓存的设计和应用场景的需求。
ROM和磁盘的区别
ROM(只读存储器)和磁盘是两种不同的存储设备,它们有以下区别:
- 功能:ROM是一种非易失性存储器,它在断电情况下也可以保留存储的数据。它通常用于存储固件、操作系统和其他永久性数据。磁盘是一种机械存储设备,用于存储大量数据,可以在断电情况下读取和写入数据。
- 可写性:ROM是只读的,即存储在其中的数据无法直接修改或删除。它的内容在制造过程中被编程,之后无法更改。磁盘是可写的,可以读取、写入和删除数据。
- 访问速度:由于ROM是固态存储器,它的访问速度通常比磁盘更快。ROM的访问时间通常以纳秒级别计算,而磁盘的访问时间通常以毫秒级别计算。
- 容量:ROM的容量通常较小,通常以几兆字节或几十兆字节为单位。磁盘的容量通常较大,可以存储数百GB、TB甚至更多的数据。
- 成本:ROM的成本通常较高,因为它是一种专门制造的存储器。磁盘的成本相对较低,因为它是一种机械设备。
总的来说,ROM适用于存储固定的、不需要经常修改的数据,而磁盘适用于存储大量的可读写数据。
SSD和磁盘有什么区别
SSD(固态硬盘)和磁盘(传统硬盘)是两种不同类型的存储设备,它们有以下区别:
- 技术原理:SSD使用非易失性闪存存储技术,而磁盘使用机械旋转磁盘和读写磁头的技术。
- 访问速度:SSD的访问速度比磁盘更快。由于SSD使用闪存芯片进行数据存取,没有机械部件,因此具有更快的数据传输速度和更低的访问延迟。
- 耐用性:SSD比磁盘更耐用。由于磁盘使用机械部件,如旋转磁盘和移动读写磁头,容易受到物理冲击和磁场干扰的影响。而SSD没有机械部件,因此更耐用,对冲击和磁场干扰的抵抗能力更强。
- 噪音和能耗:SSD没有机械部件,因此没有旋转磁盘和读写磁头产生的噪音。此外,SSD的能耗也比磁盘更低。
- 容量和成本:磁盘的容量通常比SSD更大,而且磁盘的价格相对较低。虽然SSD的价格逐渐下降,但以每GB计算,磁盘仍然比SSD更经济实惠。
总的来说,SSD适用于需要快速访问速度、高耐用性和低能耗的应用,如操作系统和应用程序的安装盘。磁盘适用于需要大容量存储和相对较低成本的应用,如大量数据存储和备份。
aside
Cache lines, sets, and blocks: What’s the difference?
sizeof 函数
sizeof是C和C++中的一个运算符,用于获取数据类型或变量的大小(以字节为单位)。在C语言中,sizeof是一个关键字,而在C++中,sizeof是一个运算符。
sizeof的语法如下:
sizeof (type)
sizeof expression
其中,type可以是任何数据类型,包括基本数据类型(如int、float、char等)、用户定义的结构体、数组、指针等。expression可以是任何有效的表达式,包括变量、常量、函数调用等。
sizeof返回的结果是size_t类型的无符号整数,表示给定类型或表达式所占用的内存大小(以字节为单位)。这个值在不同的平台上可能会有所不同,因为它取决于编译器和操作系统的实现。
sizeof的一些常见用途包括:
- 在动态内存分配中,用于确定分配内存块的大小。
- 在数组操作中,用于计算数组的长度。
- 在编写通用代码时,用于确定数据类型的大小,以便进行正确的内存操作。
需要注意的是,sizeof是一个在编译时求值的运算符,因此它的结果是在编译时确定的,而不是在运行时。
link
https://www.cs.cmu.edu/afs/cs/academic/class/15213-f15/www/lectures/11-memory-hierarchy.pdf
https://www.cs.cmu.edu/afs/cs/academic/class/15213-f15/www/lectures/12-cache-memories.pdf
https://zhuanlan.zhihu.com/p/111613441
https://zhuanlan.zhihu.com/p/111015165














 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









