










csapp cache lab part A
valgrind --log-fd=1 --tool=lackey -v --trace-mem=yes ls -l
valgrind --log-file=./ls_l_output.txt --tool=lackey -v --trace-mem=yes ls -l
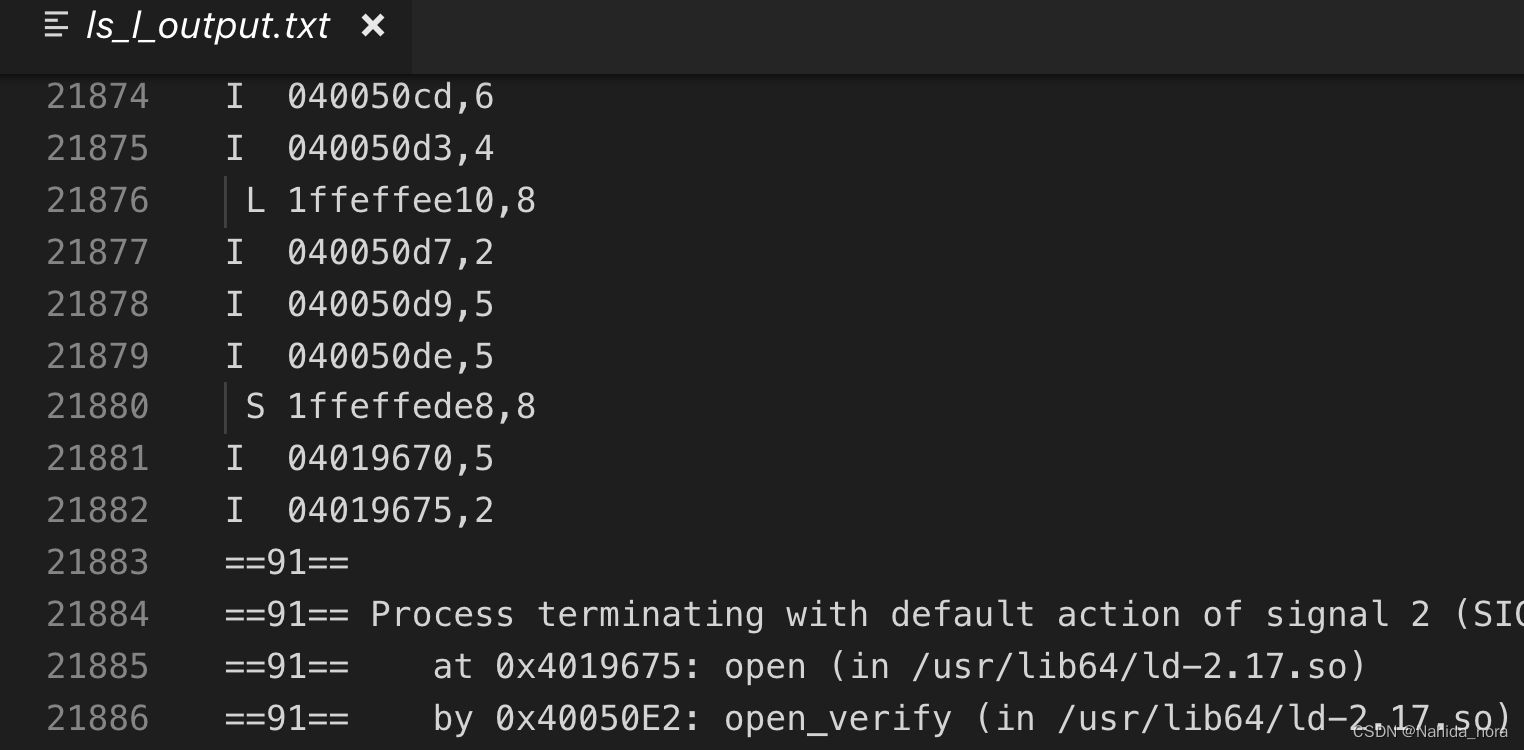
21882 行之前,每行表示一个或两个内存访问。每行的格式为
[空格] 操作 地址,大小
操作字段表示内存访问的类型:“I”表示指令加载,“L”表示数据加载,“S”表示数据存储,“M”表示数据修改(即数据加载后跟数据存储)。每个“I”之前都没有空格。每个“M”、“L”和“S”之前都有一个空格。地址字段指定一个64位的十六进制内存地址。大小字段指定操作访问的字节数。
part A Writing a Cache Simulator
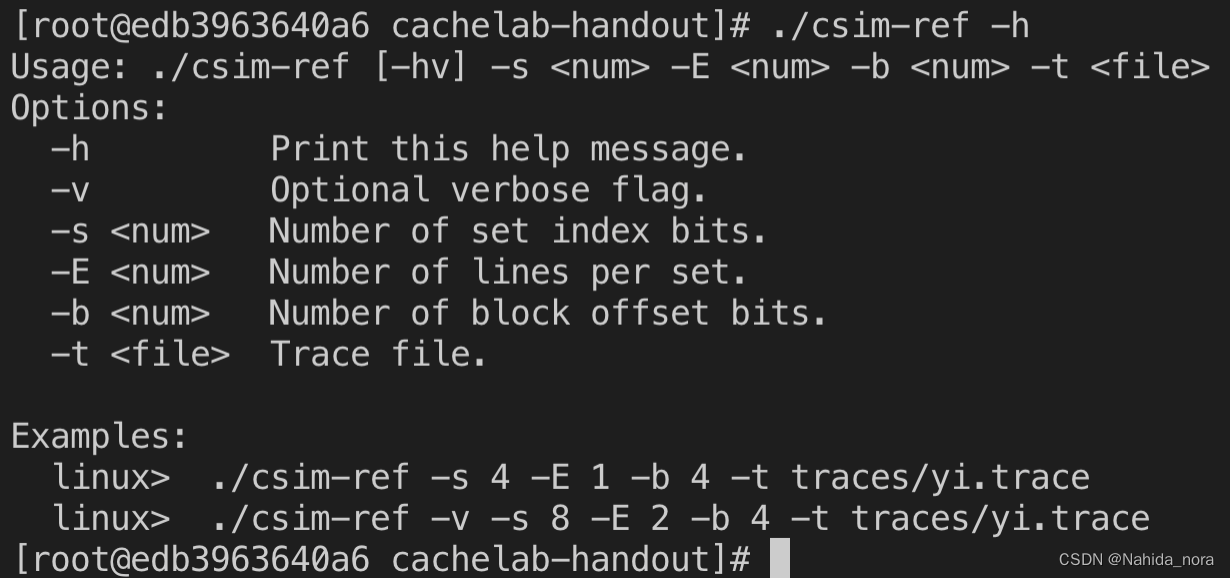
例子:

假设有一个由(s, E, b) = (4, 1, 4) 表示该缓存有2 ^ s个组,每个组有1行,每个块有2 ^4个比特。 t是valgrind 的trace 文件。
需要实现可以和csim-ref一样的结果的cache simulator。
cache 介绍
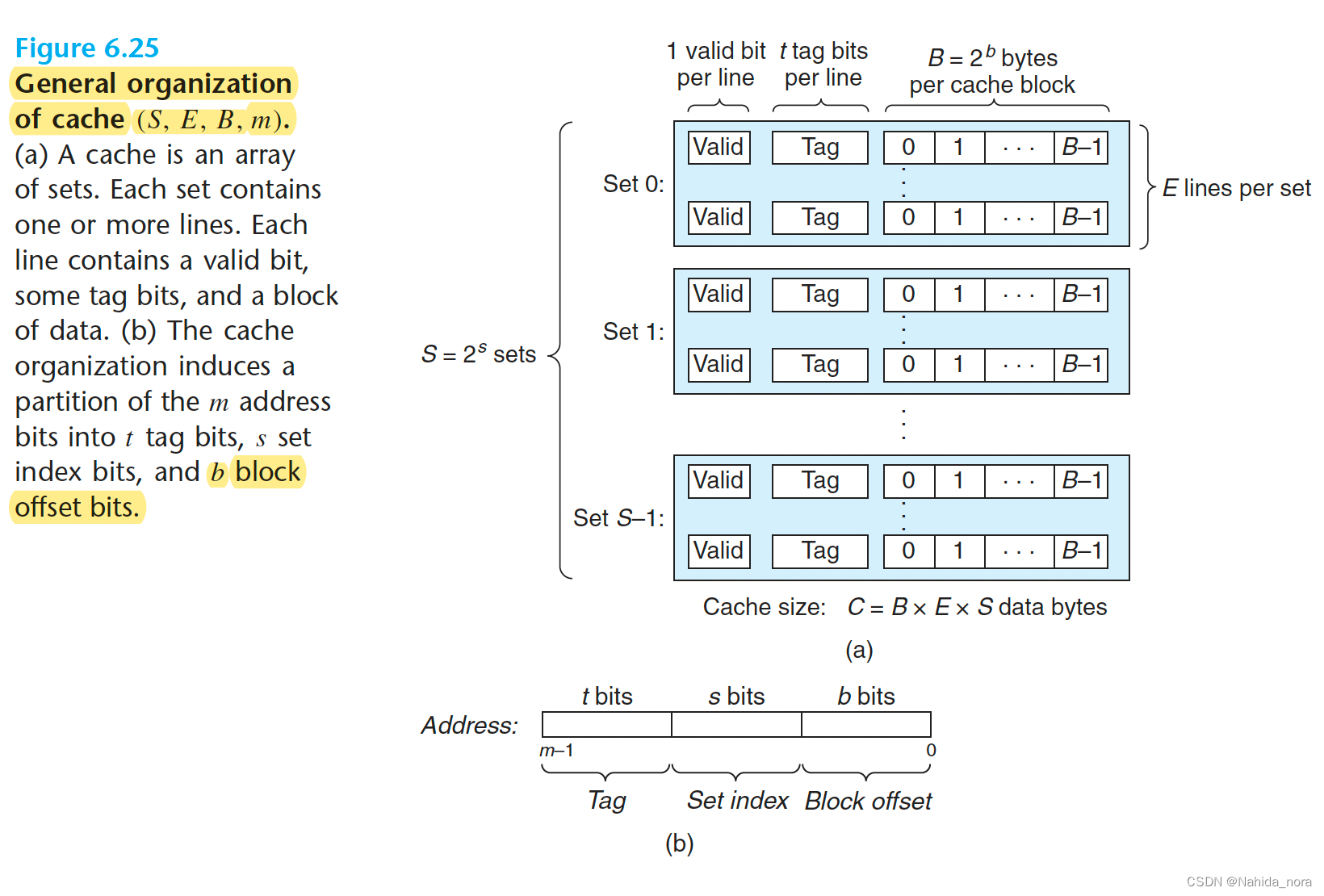
设计Cache Simulator
设计一个Cache Simulator可以分为以下几个步骤:
- 定义Cache的结构:首先需要定义一个结构体来表示Cache的属性,如Cache大小、块大小、关联度等。可以使用数组来表示Cache的行和块,每个块包含标记、有效位、数据等信息。

- 实现Cache的初始化函数:编写一个初始化函数,用于初始化Cache的各个属性和数据。可以根据Cache的大小和块大小计算出所需的行数和块数,并分配相应的内存空间。
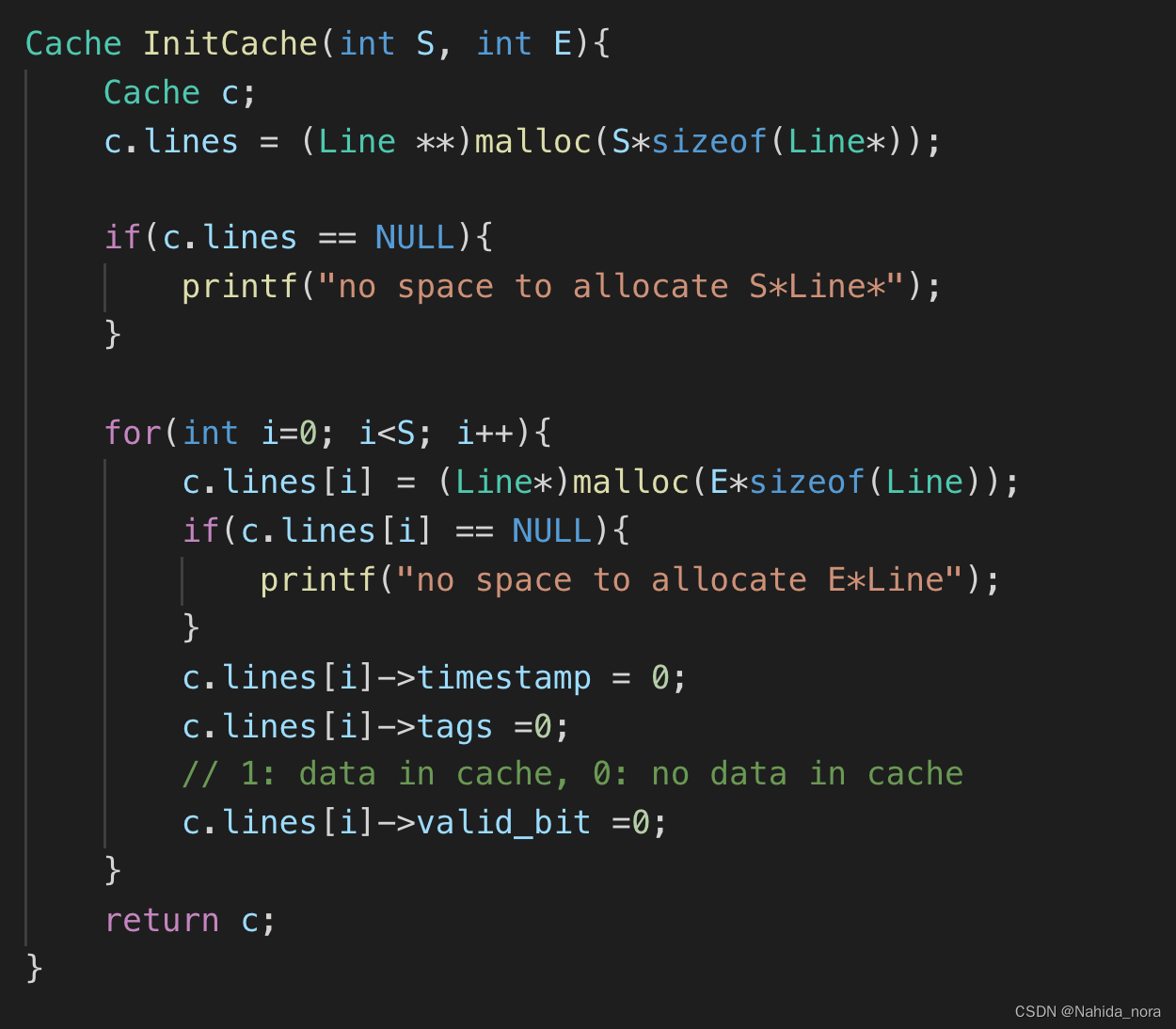
S: Set 数量, E: 每个set的cache line 数量。
-
对cache的操作是基于tracefile的内容(指令和地址两部分组成)

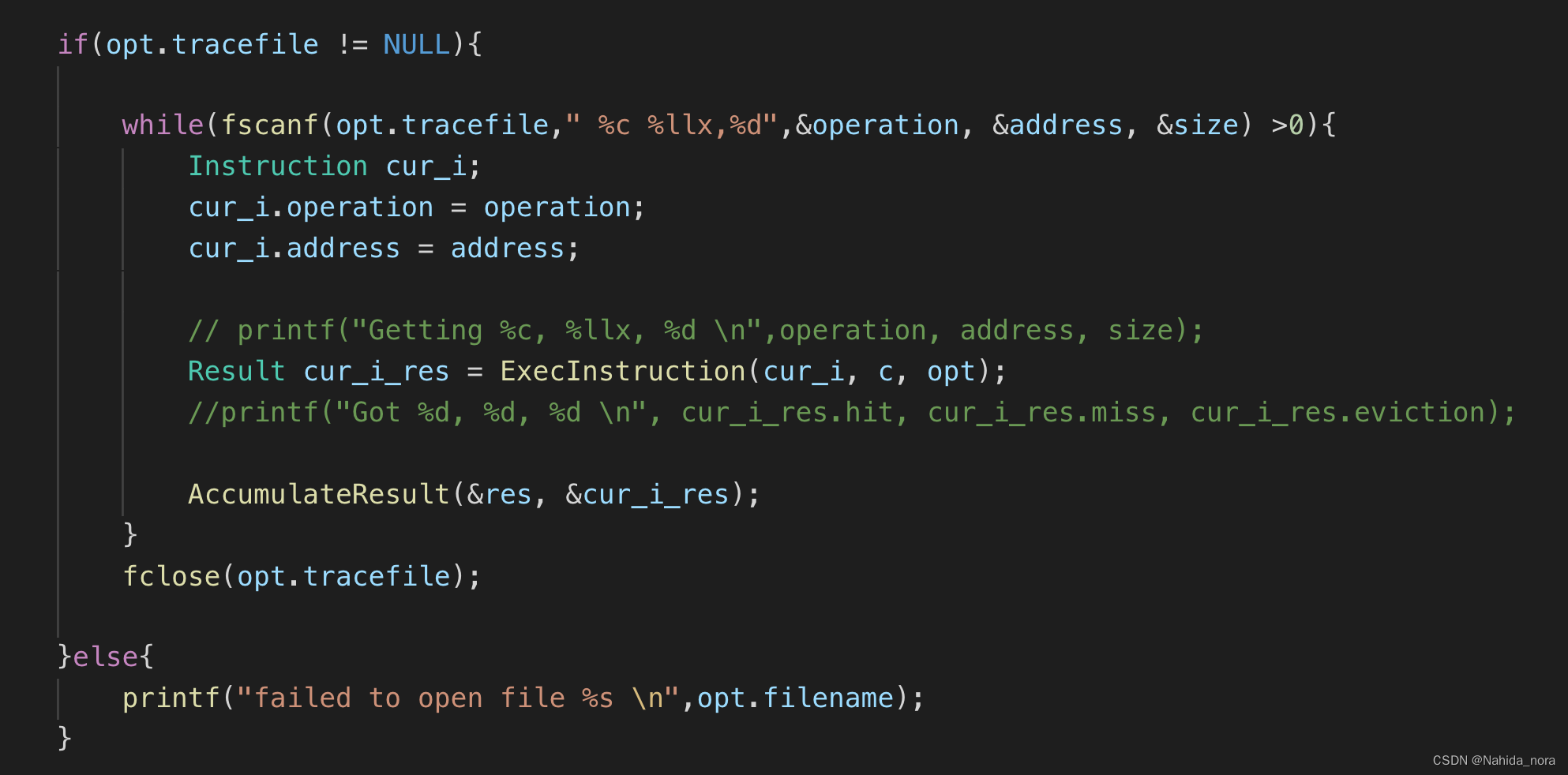
获取tracefile的内容,将指令传递给处理指令的函数 -
实现缺失处理函数:当Cache中没有找到对应的块时,需要进行一次缺失处理。缺失处理可以分为读缺失和写缺失两种情况,分别对应着从主存中读取数据到Cache和将数据写入主存。可以根据Cache的替换策略(如最近最少使用LRU)来选择替换哪个块。

先判断是否有空,如果在没有cache hit的情况下,直接返回空的cache line的index, 在没有空cache line和cache miss的情况下,选择time_stamp最小的cache line进行替换。使用的是LRU。
data load: 存在cache hit和cache miss的情况;
data store: 存在cache hit和cache miss的情况;
data modify: 存在cache hit和cache miss的情况, 在cache hit的情况下,会hit 2次,在cache miss的情况下,会hit 1次和miss 1次,data modify 实际上等于(data load + data store);
只有在没有empty line且cache miss的情况下,增加cache evication.
因为题目没有说明关于memory的部分,所以就不考虑write-back, wirte-through, write-allocate 和 no-write-allocate的区别。

- 编写测试代码:编写一些测试代码来验证Cache Simulator的正确性。可以模拟一些读写操作,并打印出相应的Cache状态和结果,进行调试和验证。
case 1:
[root@edb3963640a6 cachelab-handout]# ./csim -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/dave.trace
hits:2 misses:3 evictions:0
[root@edb3963640a6 cachelab-handout]# ./csim-ref -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/dave.trace
hits:2 misses:3 evictions:0
case 2:
[root@edb3963640a6 cachelab-handout]# ./csim-ref -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/long.trace
hits:257595 misses:29369 evictions:29353
[root@edb3963640a6 cachelab-handout]# ./csim -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/long.trace
hits:257595 misses:29369 evictions:29353
case 3:
[root@edb3963640a6 cachelab-handout]# ./csim -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/trans.trace
hits:211 misses:27 evictions:18
[root@edb3963640a6 cachelab-handout]# ./csim-ref -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/trans.trace
hits:211 misses:27 evictions:18
case 4:
[root@edb3963640a6 cachelab-handout]# ./csim-ref -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/yi.trace
hits:4 misses:5 evictions:3
[root@edb3963640a6 cachelab-handout]# ./csim -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/yi.trace
hits:4 misses:5 evictions:3
case 5:
[root@edb3963640a6 cachelab-handout]# ./csim -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/yi2.trace
hits:16 misses:1 evictions:0
[root@edb3963640a6 cachelab-handout]# ./csim-ref -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/yi2.trace
hits:16 misses:1 evictions:0
[root@edb3963640a6 cachelab-handout]# valgrind --leak-check=full ./csim -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/long.trace
==1736== Memcheck, a memory error detector
==1736== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==1736== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
==1736== Command: ./csim -s 4 -E 1 -b 4 -t /home/csapp/Cache_Lab/cachelab-handout/traces/long.trace
==1736==
hits:257595 misses:29369 evictions:29353
==1736==
==1736== HEAP SUMMARY:
==1736== in use at exit: 0 bytes in 0 blocks
==1736== total heap usage: 19 allocs, 19 frees, 1,648 bytes allocated
==1736==
==1736== All heap blocks were freed -- no leaks are possible
==1736==
==1736== For lists of detected and suppressed errors, rerun with: -s
==1736== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
需要注意的是,Cache Simulator只是一个模拟器,用于模拟Cache的行为和性能,实际上并不会使用真实的硬件Cache。
link
https://valgrind.org/docs/manual/manual.html
https://en.cppreference.com/w/c/memory/malloc
struct & class
struct 和 class 对比
在C++中,class和struct都可以用来定义结构,它们之间的主要区别在于默认的访问权限和继承方式。
优势:
- 封装性:class和struct都可以用于封装数据和方法,将相关的数据和操作封装在一起,提高了代码的可读性和可维护性。
- 数据成员的默认访问权限:class的数据成员默认是私有的(private),而struct的数据成员默认是公有的(public)。这意味着,在class中,数据成员默认是私有的,只能在类的内部访问,需要通过公有的成员函数来访问和修改;而在struct中,数据成员默认是公有的,可以直接访问和修改。
- 继承方式:在class中,默认继承方式是私有继承(private inheritance),而在struct中,默认继承方式是公有继承(public inheritance)。这意味着,在class中,派生类继承基类的成员时,默认是私有继承,基类的公有成员在派生类中会变成私有成员;而在struct中,派生类继承基类的成员时,默认是公有继承,基类的公有成员在派生类中仍然是公有成员。
劣势:
- 默认访问权限和继承方式的不同可能导致代码的可读性和可理解性变差。由于class和struct在默认访问权限和继承方式上的差异,可能会使代码的含义和行为不太明确,需要仔细阅读和理解代码。
- 由于struct的数据成员默认是公有的,可能会导致数据的访问控制不够严格,增加了代码的风险。
总的来说,class和struct在功能上没有本质的区别,它们只是在默认访问权限和继承方式上有所不同。选择使用class还是struct取决于具体的需求和编程风格,以及代码的可读性和可维护性。
使用struct的常见情况
-
数据传输:当需要在不同的模块或函数之间传递一组相关的数据时,struct可以提供一个简单的数据容器。由于struct的数据成员默认是公有的,可以方便地访问和修改数据,而不需要编写额外的访问函数。
-
C兼容性:在与C代码进行交互或在C项目中使用时,struct通常是更常见的选择。C语言中没有class的概念,使用struct可以更好地保持代码的兼容性。
-
内存布局:有时需要控制数据在内存中的布局,如与硬件进行交互时。struct可以提供更直接的控制,如使用特定的对齐方式或顺序。
-
简单的数据结构:当数据结构相对简单且没有复杂的行为时,struct可以提供一种更直观和简洁的方式来定义和操作数据。在这种情况下,使用class可能会增加不必要的复杂性。
-
代码风格和习惯:有些开发者更喜欢使用struct,因为它们认为struct更接近于C的思维方式,更简洁和直观。
需要注意的是,选择使用struct还是class是一种编程风格和个人偏好的问题。在实际开发中,根据具体的需求和项目要求,可以灵活选择使用struct或class来定义结构。
使用struct实现内存布局
-
对齐方式:可以使用struct的对齐方式来控制数据在内存中的布局。在struct定义中,可以使用特定的对齐属性来指定数据成员的对齐方式。例如,可以使用
__attribute__((aligned(n)))来指定成员的对齐方式为n字节。这样可以确保数据成员按照指定的对齐方式进行布局。 -
成员顺序:可以通过调整struct中成员的顺序来控制数据在内存中的布局。默认情况下,成员按照定义的顺序在内存中连续排列。但是,可以通过调整成员的顺序来优化内存布局,以减少内存碎片和提高访问效率。
-
位字段:使用位字段可以将多个相关的数据压缩到一个字节或几个字节中,从而节省内存空间。在struct中定义位字段时,可以使用特定的语法来指定每个字段的位数和布局方式。
需要注意的是,内存布局的具体实现可能会受到编译器和平台的影响。不同的编译器和平台可能对内存布局有不同的实现方式和规则。因此,在使用struct进行内存布局时,需要了解并考虑目标平台和编译器的特性和限制。
uint64_t 和 unsigned long long
uint64_t和unsigned long long都是无符号64位整数类型,但它们有一些区别:
-
uint64_t是C语言标准库stdint.h中定义的固定宽度整数类型,它保证了它的宽度为64位。这意味着无论在什么平台上,uint64_t都将是一个64位的无符号整数类型。 -
unsigned long long是C语言中的内置类型,它的宽度至少为64位,但不保证是严格的64位。在大多数平台上,unsigned long long的宽度也是64位,但在一些特殊的平台上可能会有所不同。
因此,主要区别在于可移植性和宽度保证方面:
uint64_t提供了对64位无符号整数类型的严格宽度保证,因此在不同平台上具有相同的宽度。unsigned long long是C语言中的内置类型,它的宽度至少为64位,但在某些平台上可能会更大。这使得它在可移植性方面可能不如uint64_t。
使用unit64_t需要stdint.h, 编译时需要指定
左移运算
在C语言中,<<是位左移运算符。它用于将一个二进制数的所有位向左移动指定的位数。左移操作会将数值乘以2的指定位数次幂。
<<运算符的语法如下:
result = value << n;
fscanf 函数
fscanf函数可以使用不同的格式说明符来读取不同类型的数据。下面是一些常用的格式说明符及其用法:
%d:读取整数。%f:读取浮点数。%lf:读取双精度浮点数。%c:读取一个字符。%s:读取一个字符串,遇到空格或换行符会停止读取。%u:读取无符号整数。%o:读取八进制整数。%x:读取十六进制整数。%p:读取指针。%[]:读取一个字符集合,可以使用[]指定需要读取的字符范围。
下面是一个示例代码,展示了如何使用不同的格式说明符来读取文件中的数据:
#include <stdio.h>
int main() {
FILE* file = fopen("input.txt", "r");
int num;
float f;
char c;
char str[100];
if (file != NULL) {
while (fscanf(file, "%d %f %c %s", &num, &f, &c, str) == 4) {
printf("Read: %d, %f, %c, %s\n", num, f, c, str);
}
fclose(file);
} else {
printf("Failed to open file.\n");
}
return 0;
}
在上面的示例中,我们使用了不同的格式说明符来读取文件中的数据。%d用于读取整数,%f用于读取浮点数,%c用于读取字符,%s用于读取字符串。读取的结果存储在相应的变量中,并打印输出。
需要注意的是,fscanf函数会按照格式说明符的顺序逐个读取数据,如果格式说明符与文件中的数据不匹配,可能导致读取错误或者结果不正确。另外,要确保格式说明符的数量与要读取的数据数量一致,以避免读取超出文件内容的数据。
fscanf 函数获取%llx类型
%llx格式说明符不需要以0x开头。它用于读取一个长长型十六进制数(long long int)的值,而不需要指定前缀。
如果你的文件中的数据是以0x开头的十六进制数,那么%llx格式说明符会正确地读取该数值。例如,如果文件中有一行数据是0x123456789abcdef,那么fscanf(pFile, "%llx", &address)会将该值读取到address变量中。
如果你的文件中的数据没有0x前缀,而是纯粹的十六进制数,那么%llx格式说明符仍然可以正确地读取该数值。例如,如果文件中有一行数据是123456789abcdef,那么fscanf(pFile, "%llx", &address)同样会将该值读取到address变量中。
总之,%llx格式说明符可以正确地读取带或不带0x前缀的十六进制数。
结构体类型的二维数组和结构体类型的二维指针
在C语言中,结构体类型的二维数组和结构体类型的二维指针有一些区别。
-
内存分配方式:二维数组是在栈上分配连续的内存空间,而二维指针是在堆上分配内存空间,并且需要手动进行内存分配。
-
访问方式:对于二维数组,可以使用下标索引的方式直接访问元素,例如
array[i][j]。而对于二维指针,需要通过指针的指针进行访问,例如ptr[i][j]或*(*(ptr + i) + j)。 -
灵活性:二维数组的大小在编译时必须是已知的,而二维指针可以在运行时动态分配内存,因此可以灵活地调整大小。
-
传递参数:二维数组作为函数参数时,会自动进行数组到指针的转换,传递的是指向数组首元素的指针。而二维指针需要显式地传递指针的指针。
下面是一个示例代码,展示了二维数组和二维指针的使用区别:
#include <stdio.h>
#include <stdlib.h>
struct Person {
char name[20];
int age;
};
void printArray(struct Person arr[][3], int rows, int cols) {
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
printf("Name: %s, Age: %d\n", arr[i][j].name, arr[i][j].age);
}
}
}
void printPointer(struct Person** ptr, int rows, int cols) {
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
printf("Name: %s, Age: %d\n", ptr[i][j].name, ptr[i][j].age);
}
}
}
int main() {
// 二维数组
struct Person peopleArray[2][3] = {
{ {"Alice", 20}, {"Bob", 25}, {"Charlie", 30} },
{ {"David", 35}, {"Emily", 40}, {"Frank", 45} }
};
printArray(peopleArray, 2, 3);
// 二维指针
struct Person** peoplePtr = malloc(2 * sizeof(struct Person*));
for (int i = 0; i < 2; i++) {
peoplePtr[i] = malloc(3 * sizeof(struct Person));
}
peoplePtr[0][0] = (struct Person){"Alice", 20};
peoplePtr[0][1] = (struct Person){"Bob", 25};
peoplePtr[0][2] = (struct Person){"Charlie", 30};
peoplePtr[1][0] = (struct Person){"David", 35};
peoplePtr[1][1] = (struct Person){"Emily", 40};
peoplePtr[1][2] = (struct Person){"Frank", 45};
printPointer(peoplePtr, 2, 3);
return 0;
}
在上面的示例中,我们定义了一个结构体类型Person,然后分别使用二维数组和二维指针来存储Person类型的数据。
在printArray函数中,我们传递了二维数组peopleArray作为参数,并使用下标索引的方式访问数组中的元素。
在printPointer函数中,我们传递了二维指针peoplePtr作为参数,并使用指针的指针进行访问。
需要注意的是,在使用二维指针时,我们需要手动进行内存分配,以及释放内存的操作。在示例代码中,我们使用malloc函数进行内存分配,并在程序结束时使用free函数释放内存。
总结起来,二维数组在内存分配和访问方式上相对简单,但不够灵活;而二维指针可以动态分配内存,并且具有更高的灵活性,但需要手动进行内存管理。根据实际需求和使用场景,选择适合的方式。
data load 和 instruction load 使用的是同一个缓存吗?
数据加载(data load)和指令加载(instruction load)使用的通常不是同一个缓存。
在计算机体系结构中,通常会使用两级缓存结构:一级缓存(L1 Cache)和二级缓存(L2 Cache)。一级缓存主要用于存储指令和数据,而二级缓存则用于扩展缓存容量和提供更高级别的缓存。
一级缓存通常分为指令缓存(Instruction Cache)和数据缓存(Data Cache)。指令缓存用于存储经常被处理器请求的指令,而数据缓存用于存储经常被处理器请求的数据。这两个缓存是独立的,各自专门用于存储不同类型的信息。
指令加载操作主要涉及指令缓存。当处理器执行指令时,它会首先检查指令缓存,看看所需的指令是否已经在缓存中。如果指令缓存命中,处理器可以直接从缓存中获取指令,无需访问主存。
数据加载操作则主要涉及数据缓存。当处理器执行数据加载操作时,它会首先检查数据缓存,看看所需的数据是否已经在缓存中。如果数据缓存命中,处理器可以直接从缓存中获取数据,无需访问主存。
尽管指令缓存和数据缓存是独立的,但它们通常共享同一级缓存,即一级缓存。这是因为指令和数据在执行过程中通常具有一定的局部性,即相邻的指令和数据很可能会被频繁地访问。通过共享一级缓存,处理器可以更好地利用缓存的容量和性能,提高指令和数据的访问效率。
至于二级缓存,它通常是共享的,即被指令和数据同时使用。二级缓存的容量较大,可以存储更多的指令和数据,以进一步提高缓存的命中率和性能。
综上所述,数据加载和指令加载通常使用不同的缓存,即数据缓存和指令缓存。它们可以共享一级缓存和二级缓存,以提高整体的缓存性能。
data modify 操作
在写回(write-back)和写直通(write-through)两种缓存写策略中,只有写回策略会导致数据修改(data modify)操作影响缓存的有效标志位(valid bit)。写直通策略不会影响有效标志位的状态。
在写回策略中,当数据被修改时,修改的数据会首先写入缓存而不是立即写入主存。此时,缓存中的有效标志位(valid bit)保持有效,表示缓存中的数据是最新的。然而,当缓存行被替换出缓存时,被替换的数据会被写回主存。在写回操作完成之前,缓存中的有效标志位会被设置为无效,表示缓存中的数据已经过期。
相比之下,写直通策略要求每次写操作都直接写入主存,不经过缓存。因此,写直通策略不会导致数据修改操作影响缓存的有效标志位。
需要注意的是,写回策略和写直通策略的选择会影响缓存的一致性和性能。写回策略可以减少对主存的写操作次数,提高性能,但可能会导致缓存和主存中的数据不一致。而写直通策略可以保持数据一致性,但会增加对主存的写操作次数,可能降低性能。因此,在具体的系统中,需要根据应用需求和系统设计来选择适合的缓存写策略。
fscanf 函数格式和空格
fscanf函数是C语言中用于从文件中读取格式化数据的函数。它的返回值是成功读取和赋值的参数的个数,或者在发生错误或到达文件末尾时返回EOF。
具体来说,fscanf函数的返回值有以下几种情况:
- 如果成功读取并赋值了所有的参数,返回值等于参数的个数。
- 如果在读取过程中发生了错误,如文件格式不符合预期,返回值为EOF(-1)。这通常表示读取操作失败。
- 如果在读取过程中到达了文件末尾,返回值为EOF(-1)。这表示已经读取完了文件中的所有数据。
需要注意的是,fscanf函数的返回值并不一定代表读取的数据的个数。它只表示成功读取并赋值的参数的个数。有时候,fscanf函数可能会读取到一部分数据,但由于格式不匹配或其他原因导致无法成功赋值给参数,这些未成功赋值的数据不会计入返回值中。
在使用 fscanf 函数时," %c %llx, %d" 和 "%c %llx, %d" 之间的主要区别在于前者字符串中有一个额外的空格字符。
-
" %c %llx, %d":
- 这个字符串中有一个空格字符。在
fscanf函数中,空格字符会导致函数在读取输入时跳过空白字符(包括空格、制表符和换行符)。 - 因此,这个格式字符串将在读取
%c、%llx和%d之前跳过任何空白字符。
- 这个字符串中有一个空格字符。在
-
“%c %llx, %d”:
- 这个字符串中没有额外的空格字符。它定义了一个紧凑的格式,
fscanf在读取输入时不会跳过输入值之间的空格。 - 如果输入中存在空格或其他分隔符,
fscanf将在必要时停止读取。
- 这个字符串中没有额外的空格字符。它定义了一个紧凑的格式,
fscanf 函数
#include <stdio.h>
int main() {
FILE *file;
char operation;
long long address;
int size;
// 打开文件
file = fopen("/home/csapp/Cache_Lab/cachelab-handout/traces/dave.trace", "r");
if (file == NULL) {
printf("无法打开文件\n");
return 1;
}
// 从文件中读取数据
fscanf(file, " %c %llx,%d", &operation, &address, &size);
// 输出读取到的数据
printf("操作:%c\n", operation);
printf("地址:%llx\n", address);
printf("地址 >> 2 :%llx\n", address >> 2);
printf("大小:%d\n", size);
// 关闭文件
fclose(file);
return 0;
}
输出:


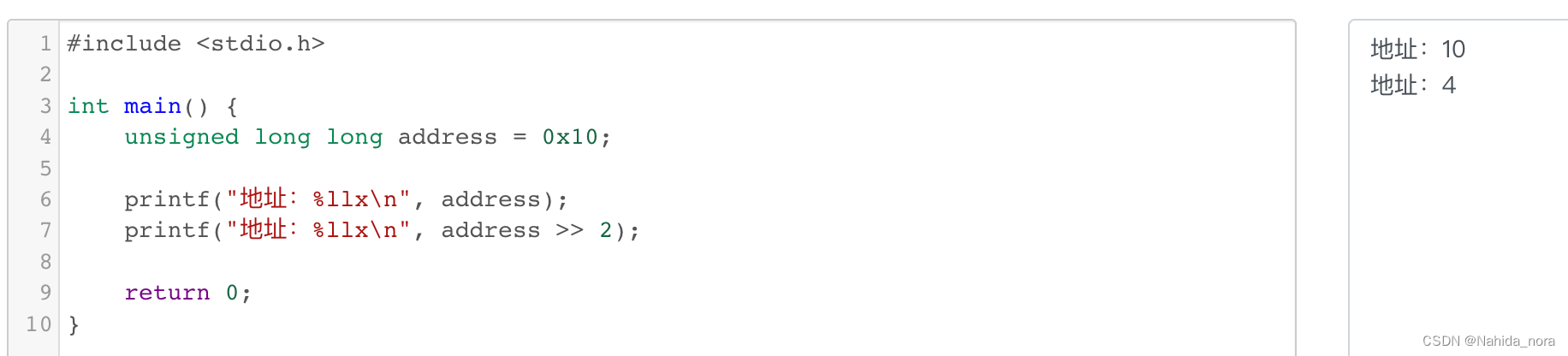
十进制和十六进制运算
address = 10 (十进制)

address = 10 (16进制)
~(~0 << 4) 和 ~(1 << 4)
表达式 ~(~0 << 4) 和 ~(1 << 4) 都涉及到位运算的按位取反和左移操作。
0 的二进制是 0…00, 1的二进制是0…01;
首先,让我们分别介绍这两个表达式的位运算优先级和计算过程:
-
~(~0 << 4):~0:首先执行~0操作,将0的所有位取反,得到一个二进制数的所有位都为1的数。例如,如果使用的是32位整数,那么~0的结果将是0xFFFFFFFF。<< 4:接下来,执行<< 4操作,将上一步的结果向左移动4位。这将导致结果中的4个最低位变为0,其余位保持不变。例如,如果~0的结果是0xFFFFFFFF,那么0xFFFFFFFF << 4的结果将是0xFFFFFFF0。~(0xFFFFFFF0):最后,对上一步的结果执行一次~操作,将结果的所有位再次取反。这将导致结果中的4个最低位变为1,其余位变为0。例如,如果0xFFFFFFF0取反,结果将是0xF。
-
~(1 << 4):1 << 4:首先执行1 << 4操作,将1向左移动4位。这将导致结果中的4个最低位变为0,其余位保持不变。例如,1 << 4的结果将是0x10。~(0x10):对上一步的结果执行一次~操作,将结果的所有位取反。这将导致结果中的4个最低位变为1,其余位变为0。例如,如果0x10取反,结果将是0xFFFFFFEF。
因此,~(~0 << 4) 的结果是 0xF,而 ~(1 << 4) 的结果是 0xFFFFFFEF。
scanf 函数
以下是示例,演示了这两个格式字符串在 scanf 中的用法,两个例子的输入都是有空格的:


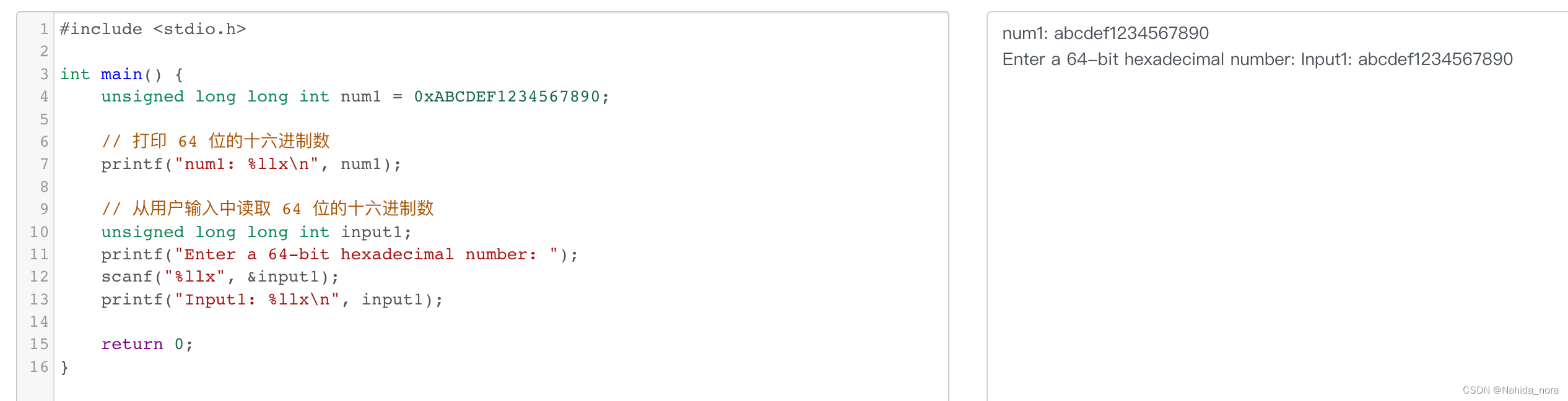
unsigned long long 类型
输入是0xABCDEF1234567890和输入是ABCDEF1234567890, printf打印的结果是一样的。
通过内存地址获取set index
要从内存地址中获取 Set Index 的信息,需要考虑缓存的结构和映射方式。通常,在相联映射缓存结构中,Set Index 是内存地址的一部分,用于确定数据块存储在哪个集合中。
步骤如下:
-
确定缓存结构参数: 了解缓存的参数,例如每个集合中的行数、集合的数量以及每个数据块的大小。
-
计算 Set Index 的位数: 通过集合数目确定 Set Index 需要多少位来表示。例如,如果有 16 个集合,那么需要 4 位来表示 Set Index。
-
从内存地址中提取 Set Index: 将内存地址转换为二进制表示,并从这个二进制表示中提取 Set Index 的位。
举例来说,假设有一个相联映射缓存,有 16 个集合(4 位来表示 Set Index),每个集合有 8 个行,并且数据块大小为 32 字节。现在要从一个地址中获取 Set Index:
- 将内存地址转换为二进制表示。
- 根据缓存结构参数,从二进制地址中取出 Set Index 的位。
- 将这些位转换为十进制数,即可得到 Set Index。
举例说明,如果内存地址是 0x12345678,假设缓存结构参数如上所述,那么可以按照以下步骤来获取 Set Index:
0x12345678转换为二进制:0001 0010 0011 0100 0101 0110 0111 1000- 根据缓存结构参数,取出 Set Index 的位:在这个例子中,Set Index 是地址中的 4 位,即
0100。 - 将
0100转换为十进制数,结果是 4。
这个值(4)就代表了给定地址中的 Set Index。这个计算方式会根据具体的缓存结构和参数而变化,但基本思路是根据位数和位置来提取特定的部分作为 Set Index。
设计参考
以下是一些可以参考的关于Cache Simulator设计的资源:
-
计算机体系结构课程教材:许多计算机体系结构课程的教材都包含有关Cache Simulator设计的章节或附录。这些教材通常提供了关于Cache的基本原理、Cache映射方式、替换策略等内容,并给出了一些示例代码来帮助理解和实现Cache Simulator。
-
开源Cache Simulator项目:在GitHub等开源代码托管平台上,有一些开源的Cache Simulator项目可供参考。这些项目通常提供了完整的Cache Simulator实现,包括Cache的结构定义、初始化函数、读写函数、缺失处理函数等。可以参考这些项目的代码来了解Cache Simulator的设计和实现方式。
-
学术论文和研究报告:一些学术论文和研究报告中提供了关于Cache Simulator设计的详细描述和分析。这些论文通常介绍了Cache Simulator的设计目标、实现方法、性能评估等内容,可以从中获取一些设计思路和经验。
-
在线教程和博客文章:一些计算机科学相关的在线教程和博客文章也提供了关于Cache Simulator设计的指导。这些教程和文章通常以易懂的方式介绍了Cache的基本概念和设计原则,并给出了一些示例代码和练习。
除了以上资源,还可以参考一些计算机体系结构相关的教学视频、课程演示和实验指导,以及相关的学术会议和研讨会的论文和演讲资料。通过综合参考多个资源,可以获得更全面和深入的关于Cache Simulator设计的知识和经验。
开源cache simulator
在GitHub上有一些开源的Cache Simulator项目,它们提供了不同层次和风格的实现。请注意,GitHub上的项目可能会不断更新和变化,因此建议查看项目的最新状态。以下是一些建议的Cache Simulator项目:
-
CACTI: Cache, Memory, and Interconnect Modeling
-
项目链接:CACTI
-
语言:C++
-
简介:CACTI是一个广泛用于缓存、内存和互连建模的工具。虽然它不是一个独立的Cache Simulator项目,但可以用于评估不同缓存配置的性能。
-
gem5: A Full-System Computer Architecture Simulator
-
项目链接:gem5
-
语言:C++
-
简介:gem5是一个全系统计算机体系结构模拟器,支持多种体系结构和架构。它可以用于模拟高级的计算机系统,包括缓存系统的行为。
-
Cachegrind (Valgrind tool)
-
项目链接:Valgrind
-
语言:C
-
简介:Cachegrind是Valgrind工具套件的一部分,用于模拟缓存和分析程序的缓存行为。虽然不是一个独立的Cache Simulator项目,但是它是一个强大的工具,特别适用于调试和性能分析。
-
CacheSim
-
项目链接: [CacheSim]https://github.com/jiangxincode/CacheSim
在查看这些项目时,请务必仔细阅读其文档和许可证,以确保它们符合你的需求和使用情境。
参考设计
https://coffeebeforearch.github.io/2020/12/16/cache-simulator.html
https://www.escholar.manchester.ac.uk/api/datastream?publicationPid=uk-ac-man-scw:218836&datastreamId=SUPPLEMENTARY-1.PDF
https://www.design-reuse.com/articles/26171/dynamically-configurable-cache-simulator.html
代码实现
#include "cachelab.h"
#include <stdint.h>
#include <stdio.h>
#include <unistd.h>
#include <limits.h>
#include <stdlib.h>
extern char *optarg;
unsigned long long globalTimestamp = 0;
typedef struct{
//uint64_t == unsigned long long
unsigned long long timestamp;
unsigned long long tags;
int valid_bit;
}Line;
typedef struct{
Line** lines;
}Cache;
typedef struct{
// 2^s (set bits) = S
int set_bits;
//cacheLine: E
int cacheLine;
//2^b (block bits) = B
int block_bits;
//valgrind trace file name
char* filename;
//valgrind trace file
FILE* tracefile;
}Options;
typedef struct{
//cache hit
int hit;
//cache miss
int miss;
//cache eviction
int eviction;
}Result;
typedef struct{
char operation;
unsigned long long address;
}Instruction;
Cache InitCache(int S, int E);
void FreeCache(Cache* c, int S, int E);
Result GetInstruction(Cache c, Options opt);
Result ExecInstruction(Instruction i, Cache c, Options opt);
void AccumulateResult(Result* a, Result* b);
unsigned long long GetTimestamp();
void UpdateTimestamp();
//accumulate result
void AccumulateResult(Result* a, Result* b){
a->hit += b->hit;
a->miss += b->miss;
a->eviction += b->eviction;
return;
}
//update TimeStamp
void UpdateTimestamp(){
globalTimestamp = globalTimestamp + 1;
return;
}
//get TimeStamp
unsigned long long GetTimestamp(){
return globalTimestamp;
}
// execute one instruction
Result ExecInstruction(Instruction i, Cache c, Options opt){
int isHit = 0;
int isEvic = 0;
unsigned long long min_timestamp = LONG_MAX;
unsigned long long target_line_index = 0;
Result res = {0,0,0};
if(i.operation == 'I')return res;
// printf("Executing %c \n", i.operation);
if(i.operation == 'L' || i.operation == 'M' || i.operation == 'S'){
unsigned long long set_index = (i.address >> opt.block_bits) & ~(~0 << opt.set_bits);
//printf("set index: %llu \n", set_index);
unsigned long long tag = i.address >> (opt.block_bits + opt.set_bits);
//printf("tag: %llu \n", tag);
for(int i=0; i< opt.cacheLine; i++){
Line l = c.lines[set_index][i];
if(l.valid_bit == 0 ){
// empty cache line
min_timestamp = 0;
target_line_index = i;
isEvic = 0;
continue;
}
if(l.tags == tag){
//cache hit
//printf("cache hit, target_line_index: %d \n", target_line_index);
target_line_index = i;
isHit = 1;
break;
}else{
if(min_timestamp > l.timestamp){
//cache miss, using LRU
min_timestamp = l.timestamp;
target_line_index = i;
isEvic = 1;
continue;
}
}
}
//update cache
c.lines[set_index][target_line_index].timestamp = GetTimestamp();
c.lines[set_index][target_line_index].valid_bit =1;
c.lines[set_index][target_line_index].tags = tag;
if(isHit == 1){
//cache hit
res.hit =1;
}else{
//can not find the tag or empty lines
res.miss =1;
}
if(isEvic == 1){
//can not find the tag
res.eviction = 1;
}
// data modify : data load + data store
if(i.operation == 'M') res.hit +=1;
UpdateTimestamp();
}else{
printf("exec wrong instruction \n");
}
return res;
}
Result GetInstruction(Cache c, Options opt){
opt.tracefile = fopen(opt.filename, "r");
/*
I 0400d7d4,8
M 0421c7f0,4
L 04f6b868,8
S 7ff0005c8,8
[space]operation address,size
*/
char operation;
unsigned long long address;
int size;
Result res = {0,0,0};
if(opt.tracefile != NULL){
while(fscanf(opt.tracefile," %c %llx,%d",&operation, &address, &size) >0){
Instruction cur_i;
cur_i.operation = operation;
cur_i.address = address;
// printf("Getting %c, %llx, %d \n",operation, address, size);
Result cur_i_res = ExecInstruction(cur_i, c, opt);
//printf("Got %d, %d, %d \n", cur_i_res.hit, cur_i_res.miss, cur_i_res.eviction);
AccumulateResult(&res, &cur_i_res);
}
fclose(opt.tracefile);
}else{
printf("failed to open file %s \n",opt.filename);
}
return res;
}
void FreeCache(Cache* c, int S, int E){
for(int i=0; i< S; i++){
free(c->lines[i]);
}
free(c->lines);
return;
}
Cache InitCache(int S, int E){
Cache c;
c.lines = (Line **)malloc(S*sizeof(Line*));
if(c.lines == NULL){
printf("no space to allocate S*Line*");
}
for(int i=0; i<S; i++){
c.lines[i] = (Line*)malloc(E*sizeof(Line));
if(c.lines[i] == NULL){
printf("no space to allocate E*Line");
}
c.lines[i]->timestamp = 0;
c.lines[i]->tags =0;
// 1: data in cache, 0: no data in cache
c.lines[i]->valid_bit =0;
}
return c;
}
int main(int argc, char* argv[])
{
int ch;
Options opt;
Cache cache;
while((ch=getopt(argc, argv, "s:E:b:t:")) != -1){
switch (ch)
{
case 's':
opt.set_bits = atol(optarg);
break;
case 'E':
opt.cacheLine = atol(optarg);
break;
case 'b':
opt.block_bits = atol(optarg);
break;
case 't':
// ./csim -t /home/csapp/Cache_Lab/cachelab-handout/traces/yi.trace
opt.filename = optarg;
break;
default:
printf("unknown option \n");
break;
}
}
int cacheS = 1 << opt.set_bits;
cache = InitCache(cacheS, opt.cacheLine);
Result res;
res = GetInstruction(cache, opt);
FreeCache(&cache, cacheS, opt.cacheLine);
printSummary(res.hit, res.miss, res.eviction);
return 0;
}
links
https://www.cs.cmu.edu/afs/cs/academic/class/15213-f15/www/lectures/12-cache-memories.pdf














 2185
2185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









