







Sequence to Sequence Learning with Neural Networks
主要内容
基于LSTM的seq2seq2机器翻译模型
内容要点
之前的DNN,要求输入输出的维度都是固定的,这显然不适用于seq2seq(上学期我们写情绪分类模型也遇到了)
提出LSTM的机器翻译模型,结构很简单,如下图:

优点:
- 可以应付单词次序敏感的句子
- 可以很好的区分主被动语态(如下图,主动语态和被动语态聚到了不同的簇中)

新发现:如果把输入端的语句输入的顺序直接倒过来,效果会提升不少(猜测是:在反转之前,可能输入端的单词与输出端距离差很远,也就是长依赖关系多,效果就不好;反转过来之后,短依赖关系增加了,效果也就好了
训练要点:
- 单词集大小固定(16k source word 8k target word),在单词集外的同意标为UNK
- 不是简单的一层LSTM,而是深度有4层
- 提到:尽管LSTM可以一定程度缓解梯度消失问题,但还是会有梯度下降问题,这里对梯度给了硬约束【参考论文 :R. Pascanu, T. Mikolov, and Y. Bengio. On the difficulty of training recurrent neural networks. arXiv preprint arXiv:1211.5063, 2012.】

- 训练技巧:每个batch的序列长度要差不多,这样可以提速(2倍)
- 此外,还利用分布式的方法提升了训练速度
效果与标准的SMT系统差不多,值得注意的是,利用该模型,对SMT系统作rerank,效果会更好(比两者都好)
Neural Machine Translation By Jointly Learning To Align And Translate
主要内容
RNN-Search算法,是第一个把attention用在机器翻译中的model
内容要点
层层递进,上面的文章,讲DNN的输入输出维度固定,不适应变长的sequence,故用word2vec的方法,把不定长的序列映射到定长的向量;这篇文章认为,【把不定长的序列映射到定长的向量】这个过程可能是一个瓶颈,尤其是面对比训练集最长的句子还要长的,效果就不行了。
这篇文章align和翻译同时进行,不需要映射到定长向量,先来看模型:
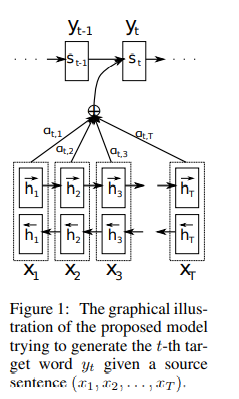
示意图如上,非常好理解,训练过程:把输入文本映射成向量后,带入这个双向RNN中,其中:
正向反向算一遍之后,把正反两个方向的h向量拼接起来,作为X每个特征位的向量表示,记为h
对每个向量h,加权求和得到上下文向量c
其中,权重生成的过程(注意力在这里运用):
函数a是一个对齐模型?,就是从含义上,是si-1和hj的相似程度,这样,经过softmax之后,α的含义就是概率上【注意softmax除分母这个操作让它有了概率的含义】yi由xj翻译过来的可能性。
这里,通过decoder注意力的分配,encoder无需编码整句了
Hierarchical Phrase-Based Translation
主要内容
除了短语之间对应的翻译外,利用同步上下文无关文法,加了根据语法生成规则,进而调整语序的模型【规则如何生成和剪枝还有待了解】
内容要点
翻译细粒度的变化,从word-base 到 phrase-base,后者优点:
- 可以帮助模型学习次序信息
- 多元词的信息表达
- 辅助上下文敏感的插入、删除
Hierarchical Phrase-Based model 的过程:
- segment 分词,分成一个个phrase
- reorder 调整每一块的顺序
- tranlate
让人印象最深的,这篇文章干的事!
无Hierarchical信息:可以发现短语对应翻译过去了,语序没调整
有Hierarchical信息:
语序调整好了


那么根据什么调整语序呢,根据规则!
规则示例:
事实上,规则有许多:
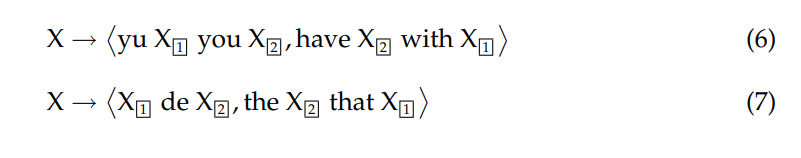

问题来了,这些规则要一条条设计么?不是,是根据训练语料提取得到的(怎么提取就是这篇文章的重点了)
未完待续。。。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









