







《Attention is all you need(1)》
(读了一部分,没全读)
基本内容
讲transformer架构,提出self-attention,结果很棒,细节很多
内容要点
(主要结合部分csdn博客,知乎文章来配合理解)

架构如上图,分为encoder层和decoder层,下面从输入开始分析每个部分:
encoder层
1. 对于输入,word-embedding,可以用word2vec,glove算法等,把每个词(汉字的话字会好一点)映射到相同长度的向量。
2. 随后,位置编码(因为相对于RNN,attention本身不考虑位置信息),两者编码加一起,得到word的向量表示。
位置编码可以通过训练得到,也可以通过公式计算得到,transformer选择了后者,公式如下
pos:单词位置;d:总维数;2i,2i+1:代表奇偶;PE:就是位置编码
好处:
(1)适应测试集的长句,如训练集最长的句子长20,测试集有个长为21的,公式可以直接算;
(2)可以用三角函数公式比较容易算相对位置
3.muti-head self-attention计算表示如下
首先是self-attention,借助李宏毅的图:
公式如下:
公式根据示意图手推即可,非常好理解
然后是多头注意力机制,多头其实很好理解,他作用和CNN里面的多通道差不多,这里还是上示意图:
可以看到这里其实就是把原来的q,k,v,分成了多个副本,最后得到好几个b,然后
把不同的b拼接在一起,再乘个矩阵即可,(这一步相对于个全连接层)





4.过完多头注意力机制之后,有一个Add&Norm层,也就是对输入作残差连接,再作LayerNorm(注意和BatchNorm的区别)
Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
5.feedforward层:是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数
公式如下
再作一个残差连接和 Layer norm
以上构造了一个完整的encoder,且维度不变,这就可以搭多层encoder(transformer用了6层,没有其他输出,就是输入,输出
)
decoder层
1.第一个Masked muti-head attention
Mask 操作在 Self-Attention 的 Softmax 之前使用
因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息
之后,对
作mask(按位相乘),再做softmax
然后再乘V
(然后再Add&Norm,下面就不说了)


2.第二个Masked muti-head attention
这个和前一个不一样的点在于KQV的来源,利用Encoder的输出生成K,V(所谓生成就是搞一个权重矩阵去乘),利用第一个Masked muti-head attention输出Z生成Q,
再做Masked muti-head attention
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
3.最后的全连接层,接softmax预测输出单词
最终的输出Z有以下特点:
预测示意图如下:


Decoder层也有六层叠加起来(之所以叠加还是因为输入和输出形状一致)
总结
Transformer优点:
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息,需要在输入中添加位置 Embedding
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- (论文中提到)Constant length between any two positions(Path length的概念,感觉可以理解为,如句子中两个的单词的距离,不同的神经网络有以下表格(可以看到CNN是log(n),很有意思)

- 由CNN固定的感受野 -> 长度等于文本长度,variable-sized的感受野,也是self-attention相对于普通attention的优点(需要看看普通attention)
- 关于CNN和self-attention各种说法,可以看 https://blog.csdn.net/woshicver/article/details/115291414
《The Mathematics of Statistical Machine Translation》Peter F. Brown
(只看了model1,已经很有收获了,还是很有内容的统计机器翻译论文,也是上世纪的论文了)
基本内容
围绕这个公式展开
法语f翻译成英语e,也就是建模,根据贝叶斯公式直接得到后面的,再令分子最大,老套路了
是语言模型(可以想n-gram语言模型)
是翻译模型,这篇文章重点探讨后者怎么建模
内容要点
1.重要问题:为什么不直接用样本估计,而要大费周章用一下贝叶斯,论文原文如下:
个人理解还不到位,暂时贴原文

2.cept的概念,英法翻译过程中,一个常见的想法就是找对应(试想我们英翻中,初学者也是蹩脚地一个词一个词对应去翻),另外设置cept,也是为了对齐(Alignment)看下面例子:
构建cept时,以法语为基准
例1:
(Le programme a ete mis en application I And the(l) program(2) has(3) been(4) implemented(5,6,7)).[一个括号一个cept]
(Le reste appartenait aux autochtones I The(l) balance(2) was(3) the(3) territory(3) of(4) the(4) aboriginal(5) people(5))
(Les pauvres sont d~munis I The(l) poor(2) don't(3,4) have(3,4) any(3,4) money(3,4)).



上面这些不重要,现在设法语长度m,英语长度l,从法语到英语的翻译有多少种对应方式:
计算,随便举个例子
法语:f1f2
英语:e1e2e3
可能的对应:{(f1,e1),(f2,e1),(f1,e2),(f2,e2),(f1,e3),(f2,e3)}
集合的所有子集个数为
Model1
非常简单的假设,也很经典,等待后续补充
RACNN
今天山大同学问我Recurrent attention CNN的一个问题,看了看这个模型(2017刊于CVPR),觉得有意思!,现思路如下:

背景:深度学习的图像细粒度检测:因为生物界许多动物种类的差异非常微小,可能就是毛发,斑点上有不同,需要用很精细的模型去做分类
这篇文章这样做
- 对一幅图,首先预训练CNN抽特征,抽取的特征同时干两件事:(1)对自己作self-attention,用注意力去指导图像应该在哪个位置放到 (2)接全连接输出分类概率
- Recurrent要竖着看,这个竖着的过程有一个损失函数:
- 这个损失函数意义是:通过注意力不断指导图片放大过程中,所抽取的特征经过后面fc全连接层的分类输出概率应该有所提高才对,如果降低了,就产生了损失
- 总的损失函数如下:
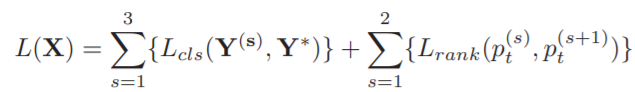
横纵都有输出,而且很好的利用注意力机制放大图像,找到图片的关键区域,辨别细粒度特征
参考
- https://zhuanlan.zhihu.com/p/338817680
- https://blog.csdn.net/qq_37774399/article/details/116190606
- https://www.cnblogs.com/wanghongze95/p/13842433.html
- https://blog.csdn.net/woshicver/article/details/115291414















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









