






 本文教你如何使用Python爬取微博热搜榜并利用百度AI的语音合成技术将其转换为语音播报,只需三步即可实现:1.爬取微博热搜榜数据;2.文本转语音;3.成果展示。
本文教你如何使用Python爬取微博热搜榜并利用百度AI的语音合成技术将其转换为语音播报,只需三步即可实现:1.爬取微博热搜榜数据;2.文本转语音;3.成果展示。
微博是一个社交平台,有高效的信息流,几乎所有人能在这上面找到自己感兴趣的内容。经常使用微博的小伙伴,大家对微博热搜榜应该都不会很陌生。每天发生了什么新闻呢,谁谁谁又上热搜了。
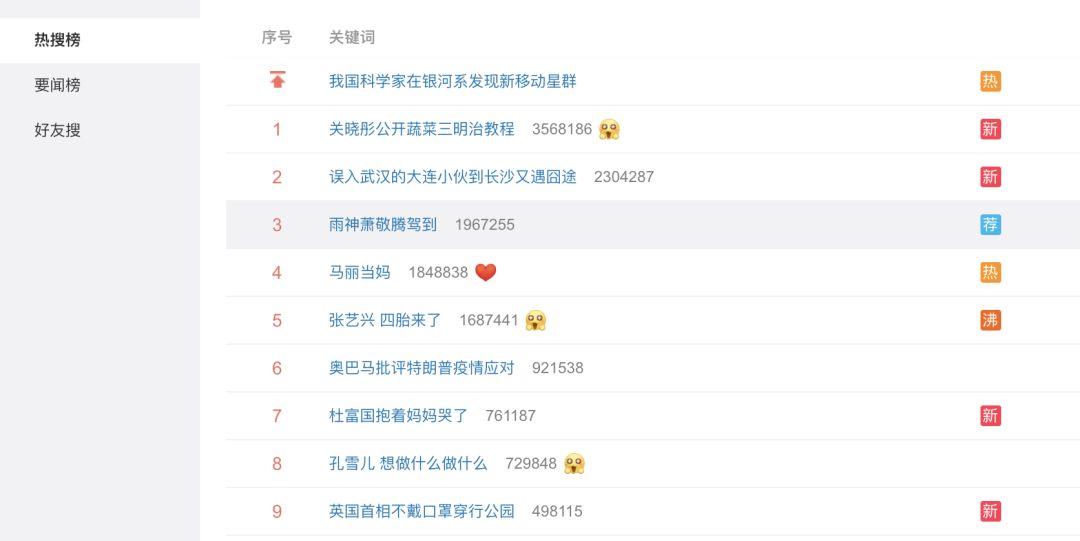
在这个信息社会,每天发生了很多新闻,想了解所有的新闻几乎不太现实。辛苦工作了一天,只想好好休息一下,可是又有一颗八卦的心,怎么办呢?为了解决这个问题,今天小编带你爬取微博热搜榜,看看今天发生了什么大事情,同时解放你疲劳的双眼,以“听的形式”来看看今天发生了什么。
本篇文章将分为三个部分,详情如下:
-
微博热搜榜爬取
-
文本转语音播报
-
成果展示
微博热搜榜爬取
爬取微博前,需要先对微博进行网页分析,在下面截图中,我们可以看到,请求方式为get请求,为了防止被反爬,爬取数据时添加cookie和header。下面代码将获取微博热搜榜的文本数据。
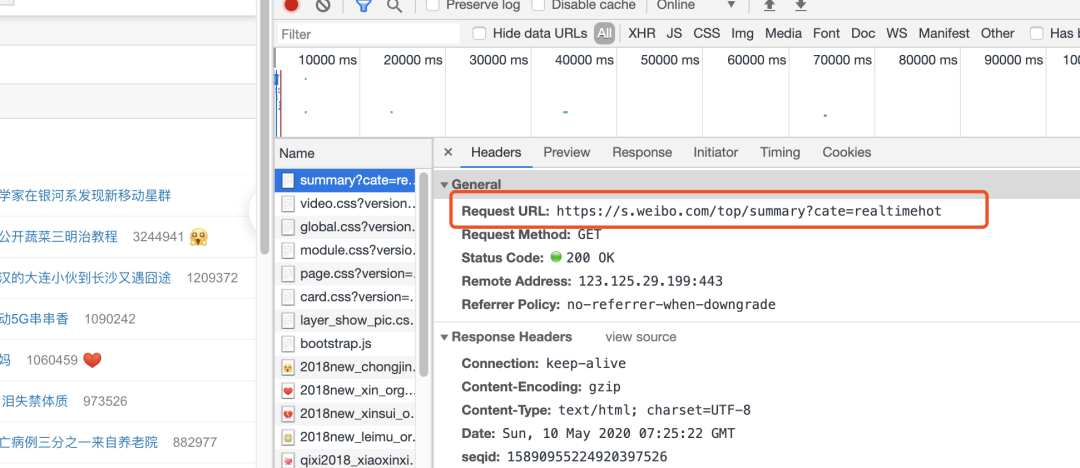
核心代码
response = requests.get(url,headers=headers,cookies=cookie)
response_text = response.text
soup = BeautifulSoup(response_text,'html.parser')
content = soup.findAll('td',class_="td-02")
info_list = []
for i,j in enumerate(content):
if i>=1:
element = j.find('a').text
series_data = '第{}名'.format(i)
el = int(re.findall(r'\b\d+\b',str(j.find('span')))[0])
info_list.append(['now',series_data,el,element])
df = pd.DataFrame(info_list,columns =['时间','序号','访问量','事件'])
文本转语音播报
我们利用百度AI的语音合成技术,来实现文本转语音功能,下面是具体的实现步骤:
1.要调用百度AI开放平台的语音合成能力,先要成为百度AI开放平台的开发者,并新建一个百度语音合成应用。然后就能看到创建完的应用的API KEY以及Secret KEY了
2.将文字转语音,保存语音格式为wav,不要忘记替换你的 API_KEY 以及 SECRET_KEY
核心代码
TTS_URL = 'http://tsn.baidu.com/text2audio'
""" TOKEN start """
TOKEN_URL = 'http://openapi.baidu.com/oauth/2.0/token'
"""
获取token
"""
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.code))
result_str = err.read()
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'audio_tts_post' in result['scope'].split(' '):
print ('please ensure has check the tts ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
""" TOKEN end """
if __name__ == '__main__':
token = fetch_token()
tex = quote_plus(TEXT) # 此处TEXT需要两次urlencode
params = {'tok': token, 'tex': tex, 'cuid': "quickstart",
'lan': 'zh', 'ctp': 1} # lan ctp 固定参数
data = urlencode(params)
req = Request(TTS_URL, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
headers = dict((name.lower(), value) for name, value in f.headers.items())
has_error = ('content-type' not in headers.keys() or headers['content-type'].find('audio/') < 0)
except URLError as err:
print('http response http code : ' + str(err.code))
result_str = err.read()
has_error = True
save_file = "error.txt" if has_error else u'微博热搜榜.wav'
with open(save_file, 'wb') as of:
of.write(result_str)
if has_error:
if (IS_PY3):
result_str = str(result_str, 'utf-8')
print("tts api error:" + result_str)
print("file saved as : " + save_file)
















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









