







文章目录
前言
在卷积神经网络(CNN)的大家族中,我们熟悉的卷积层和汇聚(池化)层通常会降低输入特征图的空间维度(高度和宽度)。然而,在许多应用场景中,例如图像的语义分割(需要对每个像素进行分类)或生成对抗网络(GAN)中的图像生成,我们反而需要增加特征图的空间维度,即进行上采样。
转置卷积(Transposed Convolution),有时也被不那么准确地称为反卷积(Deconvolution),正是实现这一目标的关键操作。它能够将经过下采样的低分辨率特征图恢复到较高的分辨率,或者在生成模型中从低维噪声逐步生成高分辨率图像。
本文将通过具体的 PyTorch 代码示例,带您一步步理解转置卷积的基本原理、填充(Padding)、步幅(Stride)以及在多通道情况下的应用。
完整代码:下载连接
基本操作
让我们从最基础的转置卷积开始。假设我们有一个 2x2 的输入张量,并使用一个 2x2 的卷积核,步幅为1,没有填充。转置卷积的操作过程可以直观地理解为:将输入张量的每个元素作为标量,与卷积核相乘,得到多个中间结果;然后,将这些中间结果按照输入元素在原张量中的位置进行“放置”和叠加,从而得到最终的输出张量。
其核心思想可以看作是常规卷积操作的一种“逆向”映射,但它并非严格意义上的数学逆运算。
下图形象地展示了这个过程:
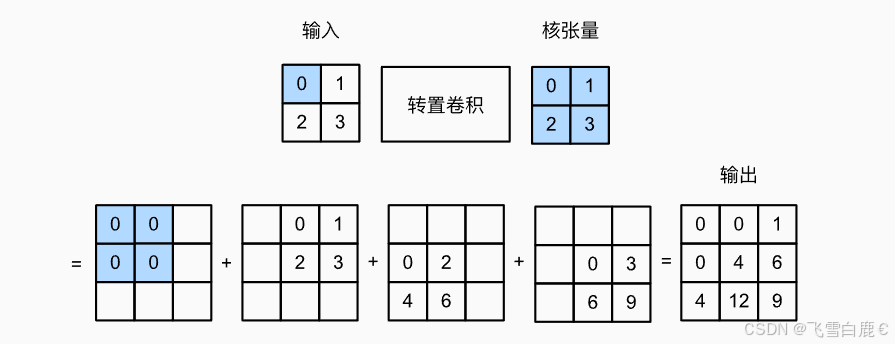
图中,输入是 2x2,卷积核是 2x2。
- 输入张量的左上角元素(0)与整个卷积核相乘,结果放置在输出张量的左上角。
- 输入张量的右上角元素(1)与整个卷积核相乘,结果向右移动一格放置。
- 输入张量的左下角元素(2)与整个卷积核相乘,结果向下移动一格放置。
- 输入张量的右下角元素(3)与整个卷积核相乘,结果向右和向下各移动一格放置。
- 所有这些放置的张量在重叠区域进行元素相加,得到最终的 3x3 输出。
输出张量的高度 (H_out) 和宽度 (W_out) 可以通过以下公式计算(当步幅为1,无填充时):
- H_out = H_in + H_kernel - 1
- W_out = W_in + W_kernel - 1
下面我们用代码来实现这个基本操作:
import torch
from torch import nn
def transposed_convolution(input_tensor, kernel):
"""
实现转置卷积(反卷积)操作
参数:
input_tensor: 输入张量,维度为 (input_height, input_width)
kernel: 卷积核,维度为 (kernel_height, kernel_width)
返回:
output_tensor: 转置卷积结果,维度为 (input_height + kernel_height - 1, input_width + kernel_width - 1)
"""
# 获取卷积核的高度和宽度,维度分别为 scalar
kernel_height, kernel_width = kernel.shape
# 初始化输出张量,维度为 (input_height + kernel_height - 1, input_width + kernel_width - 1)
output_tensor = torch.zeros((input_tensor.shape[0] + kernel_height - 1,
input_tensor.shape[1] + kernel_width - 1))
# 对输入张量中的每个元素进行处理
for i in range(input_tensor.shape[0]): # 遍历输入张量的行
for j in range(input_tensor.shape[1]): # 遍历输入张量的列
# 对于输入张量中的每个元素,将其与卷积核相乘,然后加到输出张量的对应区域
# input_tensor[i, j] 是标量,维度为 ()
# kernel 维度为 (kernel_height, kernel_width)
# 输出区域 output_tensor[i:i+kernel_height, j:j+kernel_width] 维度为 (kernel_height, kernel_width)
output_tensor[i:i + kernel_height, j:j + kernel_width] += input_tensor[i, j] * kernel
return output_tensor
# 示例使用
# 创建输入张量X,维度为 (2, 2)
X = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
# 创建卷积核K,维度为 (2, 2)
K = torch.tensor([ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









