






 本文提出了一种新的弱监督视频异常检测方法RTFM,通过鲁棒时间特征量值学习,解决多实例学习(MIL)中的问题。RTFM能够更有效地识别异常片段,提高对正常片段的鲁棒性,尤其适用于存在细微异常差异的场景。实验表明,RTFM在多个基准数据集上显著优于现有方法,具有更好的细微异常辨别能力和样本效率。
本文提出了一种新的弱监督视频异常检测方法RTFM,通过鲁棒时间特征量值学习,解决多实例学习(MIL)中的问题。RTFM能够更有效地识别异常片段,提高对正常片段的鲁棒性,尤其适用于存在细微异常差异的场景。实验表明,RTFM在多个基准数据集上显著优于现有方法,具有更好的细微异常辨别能力和样本效率。
论文解读
【摘要】具有弱监督视频级别标签的异常检测通常被表述为多实例学习(MIL)问题,其中我们旨在识别包含异常事件的片段,每个视频被表示为一个视频片段包(Bag)。尽管当前的方法显示出有效的检测性能,但它们对正样本(即异常视频中的稀有异常片段)的识别在很大程度上受到大量负样本的影响,尤其是当异常事件是与正常事件相比仅表现出微小差异时。在许多忽略重要视频时间依赖性的方法中,这个问题更加严重。为了解决这一问题,我们引入了一种新的理论上可行的方法,称为鲁棒时间特征幅值学习(RTFM),它训练特征幅值学习函数,以有效地识别正样本,大大提高了MIL方法对异常视频负样本的鲁棒性。RTFM还采用扩展卷积和自我注意机制来捕获长距离和短距离的时间相关性,以更鲁棒地学习特征量值。大量的实验表明,支持RTFM的MIL模型(i)在四个基准数据集(ShanghaiTech, UCF-Crime, XD-Violence and UCSD-Peds)上大大优于几种最先进的方法;(ii)实现了显著改进的细微异常辨别能力和样本效率。
1.引言
视频异常检测因其在自主监控系统中的应用潜力而受到广泛研究[15,57,67,79]。视频异常检测的目标是识别异常事件发生的时间窗口——在监控环境中,异常的例子有欺凌、商店盗窃、暴力等。尽管在此背景下已经探索了专门使用正常视频训练的单类分类器(OCC,也称为无监督异常检测)[15,17,28,31,47,48,77],但性能最佳的方法使用具有正常或异常视频级别标签注释的训练样本来探索弱监督设置[57,67,79]。与OCC方法相比,这种弱监督设置的目标是以相对较小的人为注释工作量为代价获得更好的异常分类精度。
弱监督异常检测的主要挑战之一是如何从标记为异常的整个视频中识别异常片段。主要是由于两个原因,即:1)异常视频的大部分片段由正常事件组成,这可能会淹没训练过程,并挑战少数异常片段的拟合;2)异常片段可能与正常片段没有足够的区别度,使得正常片段和异常片段之间的清晰区分具有挑战性。用多实例学习(MIL)方法训练的异常检测通过用相同数量的异常和正常片段平衡训练集来缓解上述问题,其中从正常视频中随机选择正常片段,并且异常片段是来自异常视频的异常得分最高的片段。尽管部分解决了上述问题,但是MIL引入了四个问题:1)异常视频中的最高异常分数可能不是来自异常片段;2) 从正常视频中随机选择的正常片段可能相对容易拟合,这对训练收敛提出了挑战;3) 如果视频有不止一个异常片段,我们就错过了一个更有效的训练过程;4)分类分数的使用提供了弱的训练信号,其不一定能够实现正常和异常片段之间的良好分离。
为了解决上述MIL问题,我们提出了一种新的方法,称为鲁棒时间特征量(RTFM)学习。在RTFM中,我们依赖于视频片段的时间特征量值,其中具有低量值的特征表示正常(即,负)片段,而高量值特征表示异常(即,正)片段。RTFM理论上是由top-k实例MIL[25]激励的,MIL使用来自异常和正常视频的具有k个具有最高分类分数的实例训练分类器,但在我们的公式中,我们假设异常片段的平均特征量大于正常片段的平均特征量,而不是假设异常片段和正常片段的分类分数之间的可分性[25]。RTFM解决了上述MIL问题:1)从异常视频中选择异常片段的概率增加;2) 从正常视频中选择的硬负正样本片段将更难拟合,从而提高训练收敛性;3)可以在每个异常视频中包括更多的异常片段;4)与使用分类分数的MIL方法相比,使用特征量值来识别正面实例是有利的,因为它能够产生更强的学习信号,特别是对于具有可能在整个训练过程中增加的量值的异常片段,并且特征量值学习可以与MIL异常分类联合优化,以在特征表示空间和异常分类输出空间两者处执行异常和正常片段之间的大差值(margin)。图1表明选择top-k特征(基于其大小magnitude)可以在异常和正常视频之间提供更好的分离。
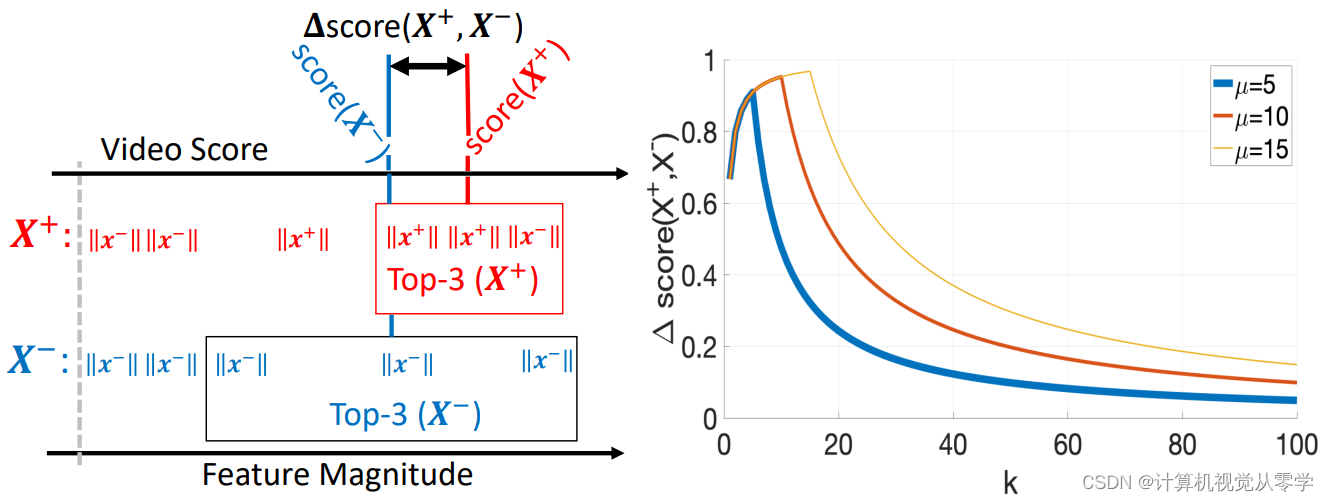
图1.RTFM训练特征量学习函数,以提高MIL方法对异常视频中正常片段的鲁棒性,并更有效地检测异常片段。Left:异常和正常片段的时间特征量值(和
) ,来自异常和正常视频(X+和X−)。 假设µ=3表示异常视频中异常片段的数量,我们可以最大化∆Scores(X+,X−),它通过选择前µ(µ≤k)位具有最大时间特征量值的片段,来测量异常视频和正常视频的得分之间的差异(分数是用前k个片段的量值平均值计算的)。Right:∆Scores(X+,X−) 随k (k∈ [1,µ])增加,然后在k>µ时减小,这表明我们提出的支持RTFM的MIL模型在k≈ µ让异常和正常视频之间提供更好的分离,即使有几个具有大特征量的正常片段。
2.相关工作
无监督异常检测
弱监督异常检测
弱监督视频异常检测方法主要基于MIL框架[57]。然而,大多数基于MIL的方法无法利用异常视频标签,因为它们可能会受到正样本包中标签噪声的影响,正样本包中的标签噪声是由正常片段错误地被选择为异常视频中的top异常事件引起的。为了解决这个问题,Zhong等人将这个问题重新表述为噪声标签下的二进制分类问题,并使用图卷积神经(GCN)网络来清除标签噪声。尽管这篇文章显示了比[57]更准确的结果,但GCN和MIL的训练在计算上代价高昂,并且可能导致无约束的潜在空间(即,正常和异常特征可以位于特征空间的任何位置),从而导致性能不稳定。
相比之下,与原始MIL公式相比,我们的方法具有很小的计算开销。此外,我们的方法通过基于l2范数的时间特征排序损失,将表示学习和异常分数学习统一起来,实现了正常和异常特征表示之间的更好分离,与以前的MIL方法相比,改进了对弱标记的探索。
3. The Proposed Method: RTFM
我们提出的鲁棒时间特征量值(RTFM)方法旨在使用弱标记视频进行训练来区分异常片段和正常片段。给出一组弱标记的训练视频,其中
是来自T个视频片段的维度为D的预计算特征(例如I3D[7]或C3D[61]),并且
表示视频级别注释(如果Fi是正常视频,则yi=0,否则yi=1)。RTFM使用的模型由
表示,并且返回T维特征
,表示将T个视频片段分类为异常或正常,参数θ,φ定义如下。该模型的训练包括端到端多尺度时间特征学习、特征量学习和RTFM支持的MIL分类器训练的联合优化。
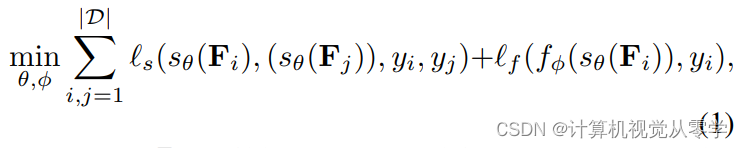
其中是时间特征提取器(
),
是片段分类器,
表示使来自正常和异常视频的前k个片段特征之间的可区分性最大化的损失函数,
是一个训练片段分类器
的损失函数,也使用来自正常和异常视频的top-k片段特征。接下来,我们讨论了我们提出的RTFM的理论动机,然后详细描述了该方法。
3.1RTMF的理论动机
[25]中的Top-k MIL将MIL扩展到阳性包含有最少数量的阳性样本,而阴性包也含有阳性样本的环境,但程度较低,并且它假设分类器可以分离阳性和阴性样本。我们的问题是不同的,因为阴性包不包含阳性样本,并且我们没有进行分类可分性假设。根据上面介绍的命名法,从视频中提取的时间特征由(1)中的表示,其中片段特征由X的行xt表示。异常片段由
表示和正常片段由
表示。一个异常视频
包含从
中提取的µ个片段和从
中提取的(T-µ)个片段,正常视频
从
中提取了所有T个片段。
为了学习一个可以将视频和片段分类为正常或异常的函数,我们定义了一个使用片段量值(magnitude)对片段进行分类的函数(即,我们使用 l2 范数来计算特征量值magnitude),其中,我们没有假设正常和异常片段之间的分类可分离性(如[25]中所假设的),而是做出了一个更温和的假设:,这意味着,通过从sθ(F)学习片段特征,使得正常的片段比异常的片段具有更小的特征量值,我们可以满足这一假设。为了实现这种学习,我们依赖于基于视频中前k个片段的平均特征量的优化[25],定义如下
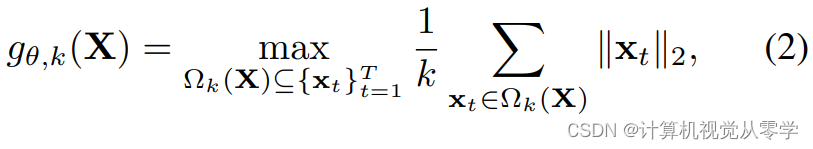
其中,由θ参数化,以表示其对
的依赖性,从而生成xt(片段特征),
包含来自
的k个片段的子集,并且
。异常视频和正常视频之间的可分性表示为
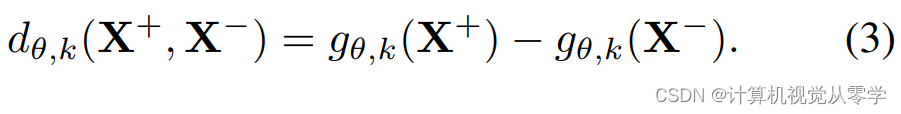
对于下面的定理,我们定义了来自
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









