






目录
【摘要】
弱监督视频异常检测是将异常与视频中的正常场景和事件区分开来,在这个设置下,我们只知道视频中是否有异常事件,但不知道异常事件具体发生的时间。它通常被建模为MIL(多实例学习)问题,其中提供视频级标签来训练异常检测器以获得视频的帧级标签。然而,现有的大多数方法一般都忽略了异常视频(阳性包)中的时间信息,只使用阳性包中的一个样本(片段)进行训练。阳性包可能包含更多有用的信息,可能性高。因此,我们提出了一种具有时间特征和异常特征的弱监督视频异常检测方法,该方法同时考虑了时间信息和更多的异常样本。它的贡献可以总结为:(1)我们考虑了更多的时间信息,并在网络中引入了注意力机制,同时使用局部和全局片段的特征来增强这些特征的时间表示能力。(2)我们在包中使用更多的阳性(异常)样本及其特征来训练我们的模型,这样更多的互补和相关信息将使我们的模型更加健壮和有效。(3)我们不仅考虑了正常样本与异常样本之间的差异,也考虑了异常样本与异常样本之间的差异,这有助于我们所提出的方法更有效、更充分地挖掘阳性(异常)样本的信息。实验结果证明了我们提出的方法在UCF-Crime和ShanghaiTech数据集上的有效性。
1.引言
视频异常检测是对视频中的异常事件进行临时定位的任务。这是计算机视觉领域的一个重要问题,因为它在现实生活的许多领域都有很大的潜力。利用监控摄像头所捕获的视频信息,该任务可以检测到视频中的非常规或异常行为和事件(违反交通规则、打架、暴力、敏感信息等)。视频异常检测模型将涉及计算机视觉的多个方面,包括动作识别、场景分类、目标检测、视频语义分割、骨架检测、行为检测等任务。虽然研究多年,但在这项任务中仍有许多问题需要解决:(1)异常事件发生频率很低,数据采集和标注困难;(2)异常事件的稀缺性导致训练中的阳性样本远少于阴性样本;而阳性样本的缺乏也使得异常特征的学习更加困难;(3)在真实场景中,正常和异常事件都是多样而复杂的。真实世界视频中的正常事件有很多种,而异常事件也有很多种。此外,我们不能穷尽异常情况,所有异常事件和行为都应该归因于异常,测试中的异常情况可能是模型从未见过的。因此,很难区分正常和异常事件。
在以往的一些工作中,由于这些困难,视频异常检测被认为是一项无监督(或半监督)任务。以前的许多方法首先学习一个共同的模式,并假设任何违反共同模式的模式都应该是不正常的。实际上,无监督视频异常检测可以在不同的统计模型中定义。包括线性拟合如PCA,和非线性拟合如深层生成模型。现有模型大致分为三类:重构模型、预测模型和生成模型。常用的数据集有UMN[2]、UCSD Ped[3]、CUHK Avenue[4]、ShanghaiTech[5]等。
但是,问题仍然存在,数据集中的正常情况是否能覆盖真实情况中的正常情况?答案肯定是否定的。而且,随着计算机视觉、深度学习技术和硬件的发展,特征表示能力越来越强,模型越来越泛化,一些异常事件可能因为这些模型强大的泛化能力而被视为正常。此外,这些无监督方法使用的数据集[2-5]多为监控视频下人行道上行走的行人,异常多为异常运动(如快速运动)。然而,这些数据集与实际情况中预期要解决的风险有很大差异。因此,弱监督问题被提出为MIL(多实例学习)问题。弱监督是指在训练过程中,我们只知道视频中是否有异常事件,而不知道异常事件发生的具体时间。MIL常用于弱监督学习问题。它使用包级标签(一个包由几个样本组成)来训练模型,而不是样本级标签,这大大降低了手动标记数据的成本。与无监督方法相比,弱监督方法能够产生更可靠的结果,并且获得视频级别标签在实际情况中也具有一定的真实性。
目前的方法通常是将视频分割成几个等长的片段(段),从每个片段中提取特征,然后利用这些特征和视频级标签进行训练,得到片段级分数,判断是否为异常样本。但是视频是连续的,没有人知道视频的哪一部分会出现问题(异常),所以等长分割可能只是将异常事件分开,或者异常事件可能跨越多个片段,所以需要考虑相邻片段的时间信息。因此,我们利用每个视频片段的特征与相邻片段和远程片段的特征进行交互,并设计了一种加强这种关系的方法。此外,由于异常的多样性,我们也认为视频中的异常有几种类型(虽然我们只需要判断它们是否属于异常)。毫无疑问,正常特征与异常特征之间应该有较大的距离,但不同类型异常的异常特征之间也应该有不同的距离。因此,我们提出了一种新的n对损耗来改善这个问题。此外,MIL方法通常只取阳性袋中异常分值最高的样本和阴性袋中异常分值最高的样本进行训练。这也忽略了异常事件或行为可能跨越多个片段或在一个视频(包)中存在多个异常的可能性。因此,如果正包中某个片段特征的异常分值虽然不是最高的,但与最高的非常接近,或者特征比较相似,我们就有理由提高MIL,在训练中使用更多正包中的片段及其特征。实验表明,我们的TAI方法在ShanghaiTech和UCF-Crime数据集上取得了最先进的结果。综上所述,我们的贡献如下:
-针对现有方法利用时间信息不足的问题,引入了注意机制。我们同时使用局部和全局片段特征来增强特征的时间表示能力,这有助于我们的方法获得更有效的分类器,可以给我们更有说服力的分数。
-我们在视频中使用了更多的样本及其特征,因此我们使用了比以前的方法更积极和相关的信息来训练我们的模型。
-我们不仅考虑异常样本与正常样本之间的差异,也考虑异常样本与正常样本之间的差异,使我们能够更实质、更有效地使用异常样本与正常样本。
2.相关工作
2.1 无监督视频异常检测
现有的方法大致可以分为三类,重构方法、预测方法和生成方法。Giorno等人提出了大型视频异常检测的无监督框架,采用滑动窗口和分类器对视频异常进行检测。Ionescu[13]等人继承了前人的思想,本文采用揭掩法对异常进行测量。Wang等[14]通过使用自动编码器来预测接下来会发生什么,然后将预测的特征与实际特征进行比较,解决了这个问题。差异越大,异常的可能性越大。很多作品也选择提出一个框架作为生成器来生成或预测未来的框架,并与真实的框架进行比较。Liu等[15]提出增加对强度、梯度和运动的约束来生成新的帧。Ye等[16]提出了一种基于GAN的框架,使用编码模块预测接下来会发生什么,使用错误细化模块区分实际帧是否异常。用于无监督视频异常检测的数据集包括UMN[2]、UCSD Ped[3]、CUHK Avenue[4]、ShanghaiTech[5]等。
2.2 弱监督视频异常检测
Sultani等[1]提出UCF-crime数据集,将弱监督多实例学习方法引入到视频异常检测中。他们使用C3D框架提取时空特征并生成异常评分,以便使用评分区分正常和异常帧。He等[6]提出了一个基于图的MIL框架与锚字典学习。他们使用弱监督设置UCSD Ped[3]数据集。Zhong等人[7]提供了一种新的观点,即弱监督学习任务是有噪声标签下的有监督学习任务,因此他们提出了一种图卷积网络来校正有噪声标签。
随着深度学习技术的发展和注意机制的引入,越来越多的高性能模型被提出。Wan等[10]提出了一种异常检测框架,称为异常回归网。他们设计了动态MIL损失和中心损失来提高MIL,使异常包和正常包的得分差值增大,正常袋和异常袋的得分差值减小。Wu等[8]提出了一种新的数据集XD-Violence,该数据集不仅使用视觉信息,还使用音频信息来帮助模型区分正常和异常实例。Feng等[11]提出了一种基于MIL的伪标签生成器和一种自引导注意任务特定编码器来检测异常。Tian等人[9]提出了鲁棒时间特征幅度学习来区分异常和正常实例,通过包含更多的阳性包和阴性包信息,也提高了MIL。在弱监督视频异常检测中,数据集包括ShanghaiTech [5], UCF-Crime [1], XD-Violence[8]和UCSD-Peds[3]。
2.3多实例学习
MIL常用于解决弱监督学习问题。在多实例学习中,数据被标记。但标签的目标不是样本层面,而是包层面。一个或几个样品放在一起称为一个包,每个包都有自己的标签。当一个包的标签是阴性时,包里的所有样品标签都是负的。当一个袋子被标记为阳性时,包中至少有一个样品被标记为阳性。在多实例学习中,我们的目标是学习一个分类器,这样我们就可以区分新输入的确切样本(不是袋子)是正样本还是负样本。在视频任务中,MIL将一个视频作为一个包,视频中的片段作为实例或样本[1,19,20]。
2.4深度度量学习中基于对的损失
我们选择在深度度量学习中使用基于对的损失来帮助模型注意到异常样本之间的差异。度量学习是一种可以学习嵌入空间的空间映射方法。在这个空间中,将所有数据转化为一个特征,相似样本之间的特征距离小于不同样本之间的距离,从而实现数据的区分。在深度学习中,许多度量学习方法使用成对样本进行损失计算。这种方法被称为基于对的深度度量学习。下面是一些基于对的损失:对比损失[18]以一对嵌入向量作为输入,如果它们属于同一类,则使它们相似,否则使它们不相似。三组损失[21]将每个锚点与一个正数据点和一个负数据点关联起来。N-pair loss[22]和Lifted Structure loss[23]反映数据的硬度。
3.方法
异常检测的目的是在帧级或片段级检测视频中的异常。在弱监督视频异常检测中,我们有一个视频序列X和它的视频级标签Y,其中Y = 1表示是一个正包,这意味着在这个视频中有异常的事件存在,而Y = 0表示视频中没有异常的事件或情况。然后,为了在时间上定位视频中异常的位置,我们将整个视频分割成几个长度相等的片段,记为X = (X1;X2;…;XT),而snippet是精确的示例。这是一个MIL问题。
然后,我们使用预训练的网络来提取每个片段的特征。遵循之前的WSVAD方法[9,11],我们使用I3D [25]提取来自视频的特征。I3D是一种视频动作识别模型,它是一种基于3D卷积的双流模型,使用了通过Imagenet预训练的两个卷积(2D)模型,一个用于RGB数据处理,另一个用于光流数据处理。以前的一些工作[1,11]也会使用C3D [36] 来实现任务不可知特性,然而,性能往往较低。C3D使用少层的CNN在小数据集上训练,而不是使用I3D等Imagenet上成功的预训练模型,这导致C3D提取的特征表征能力不如I3D。
之后,将T个片段(样本)转换为T个特征,一个视频(包)就是一个T元组特征,即(x1;x2;…;xT)。
然而这些特征与任务无关,我们的工作是使这些特征适合WSVAD任务,并为每个片段获得异常分数。
为了检测视频中的片段级异常,我们提出了一种称为TAI (Temporal reinforcement network and Multi-Positive Features MIL)的方法,该方法由3部分组成:
-我们考虑更多的时间信息。我们提出了一种时间强化网络,利用局部和全局片段的特征来增强特征的时间表示能力。
-我们改进了MIL方法,使得更多的片段及其特征在正包中参与训练。
-我们不仅考虑异常样本与正常样本之间的差异,也考虑异常样本之间的差异。在此基础上,我们提出了一种新的n对损耗。
我们的方法框架如图1所示。
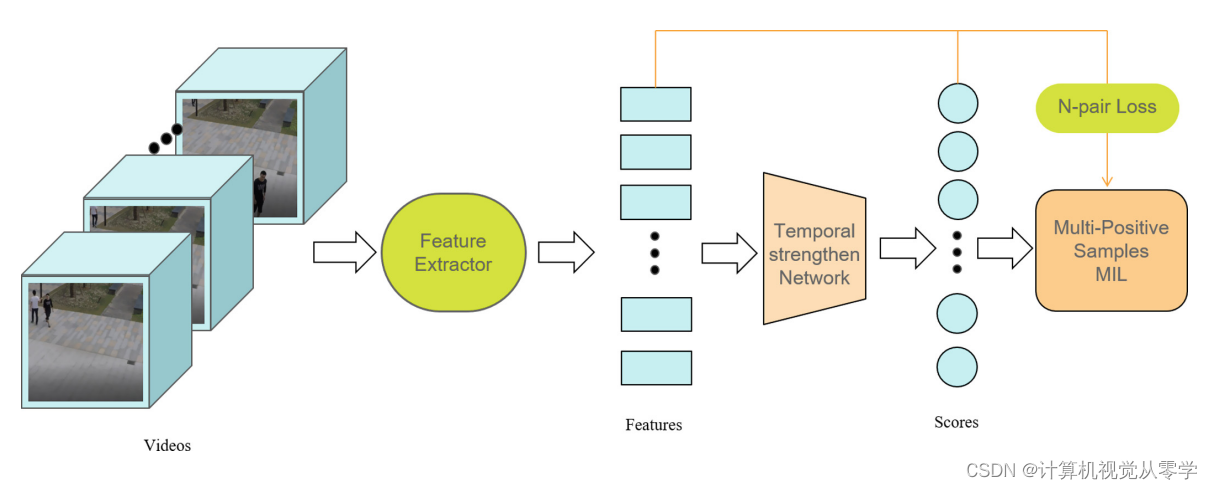
图1.我们方法的框架。首先,我们将视频分成T个片段,然后使用预先训练好的模型对每个片段进行特征提取。在此之后,我们使用时间强化网络来获取每个特征的异常值。最后,我们使用多个正样本MIL和一个新的n对损失来得到最终的分类器。
3.1时序强化网络
提取特征(x1;x2;…;xT)时,我们使用S()函数来获得每个特征的异常分数(s1;s2;…;sT)。毫无疑问,正常视频的得分预期会比异常视频小,而异常视频的得分预期会更高。为了使用每个片段的时间信息,我们应该考虑的第一件事是锚片段的相邻片段。这些相邻的片段及其特征将有助于区分锚片段是否为异常样本。
所以我们应该使用m-nearest snippet和它的特征来加强整个特征,这样我们就能得到一个更有说服力的分数。因此,在形式上,我们设计了一个时态强化函数F()来提取高级局部时间信息。输入是特征向量(x1;x2;…;xT)从连续的片段中提取。回归过程表述为:
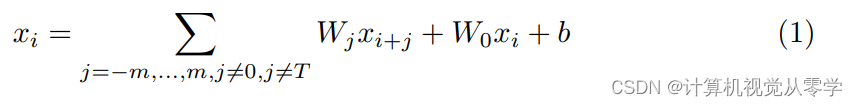
因此,我们可以选择m来决定函数中有多少相邻的片段及其特征将被考虑。m控制了每个局部片段xi中建模的时间强化。我们可以使用卷积层来获得局部的时间特征。
然而,除了相邻特征之外,长距离的时间信息在这项任务中也很有用。因为一个异常事件可能会持续发生很长时间,或者一个异常事件发生了一段时间,过了一段时间,又发生了一次。因此,我们也要注意远距离的时间信息。
但是由于卷积核的接受域是局部的,所以将整个图像不同部分的区域进行关联需要很多层,这将造成大量的计算量。因此,为了处理长距离的时间信息,我们在时间信息强化网络中加入了注意层。
目前已有一些关于视觉领域注意机制的研究,如NLNet[27]和SENet[26]。然而,NLNet对每个位置学习位置无关的注意图,造成了大量的计算浪费,而SENet使用全局上下文重新校准不同通道的权重来调整通道依赖关系,但是使用权重重新校准的特征融合不能充分利用全局上下文。因此,我们选择使用GCNet[28]将全球时间信息组合到我们的模型中。全局上下文块(GCNet)既能像NL块一样建立有效的长距离依赖关系,又能像SE块一样节省计算量。GC块可以表述为: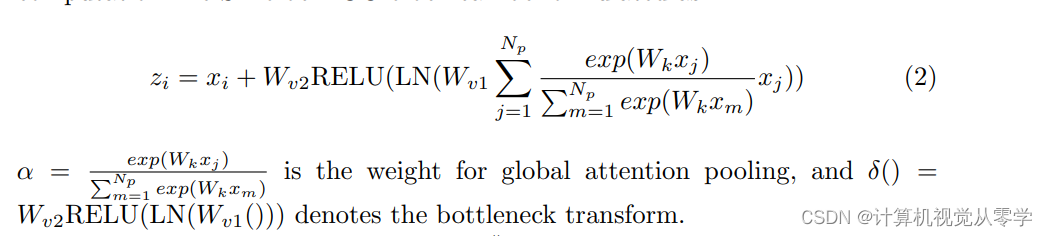
在我们的方法中,我们使用函数C()表示来自GCNet的上下文块以获得长距离的时间信息,使用函数F()表示卷积层以获得相邻的时间信息。
之后,我们将2个特征(一个是局部时间特征,另一个是全局时间特征)连接起来,使用3个完全连接的层,由Sigmoid函数激活,得到异常分数,用θ()表示。该部分的整个过程可以表述为:

我们的时间信息强化网络结构如图2所示。
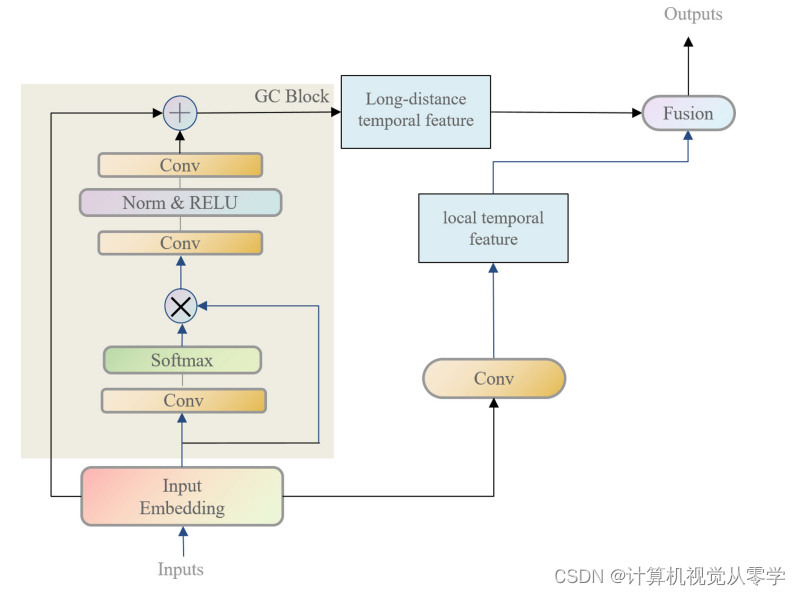
图2.时间信息强化网络(TISN)的结构。我们利用从I3D中提取的任务不可知特征作为输入,通过局部时间信息和全局时间信息来增强时间信息。GC块用于获取长距离(全局)时间信息,卷积层用于获取局部时间信息。
3.2 多阳性样本MIL
MIL方法通常只取正包中异常值最高的片段特征和负包中异常值最高的特征进行训练。这是一个很大的弱点,因为它可能会忽略一个正包中很多有用的信息,因为异常事件或行为可能跨越多个片段(片段),或者在一个视频(包)中有多个异常(正样本)。因此,我们提出了一种改进的多阳性样本MIL,即在一个阳性袋中使用更多的阳性样本。
给定一个含有T个片段的视频V,通过映射函数S()预测异常值。我们使用top-k分数及其特征来优化网络。如果k = 1,我们的多正样本MIL等于MIL。给定一批(v1, v2,…,V n),第一部分我们将得到 n × T 个特征和分数,然后在多阳性样本MIL中,我们有n × k个阳性样本及其特征和分数。利用这一点和下一部分的n对损失,我们可以得到分类器。
3.3 异常样本的n对损失
以往的方法通常以一对正常特征和一对异常特征作为输入,如果它们属于同一类,则将它们拉在一起,否则将它们分开。但在模型更新参数时,只考虑一个阳性样本(异常样本),而忽略其他阳性样本。
因此,它只能使模型所选择的异常样本与正常样本保持较大的距离,而不能保证正常样本与其他未选择的异常样本保持较大的距离。更重要的是,我们知道,异常是各种各样的,毫无疑问,所有的阳性样本(异常样本)都不只是属于现实世界中的一种异常事件,这些异常样本及其所代表的特征也会有所不同,这意味着,这些异常样本之间的平均距离也有点大,即使其中一些来自同一类。
因此,我们提出了一种新的n对损耗来改善上述问题。N-pair损失函数使用数据之间的结构信息来学习更独特的表示。在更新每个参数的过程中,它还考虑了正常样本与其他许多不同的异常样本之间的关系,因此能够使异常样本与其他异常样本保持相对较大的距离。每个N对损失的训练样本由N + 1个元组组成,即,其中x−为负(正常)样本相对于其他样本的特征,其他为正样本的特征,D为两个特征的距离函数,N为特征标准化函数:
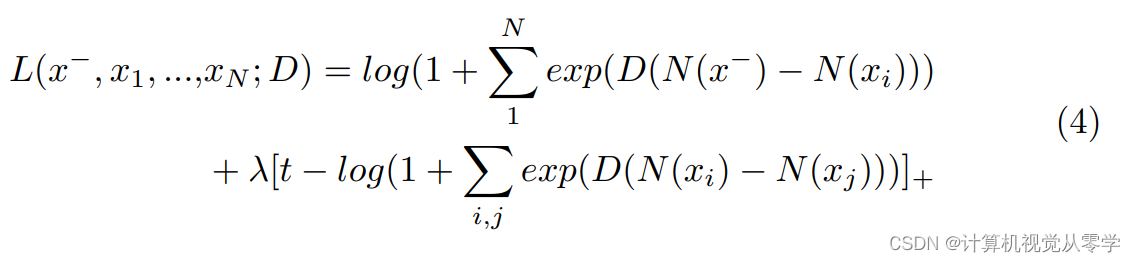
第一部分介绍了更多的阴性样本与选定的阳性样本的差异。第二部分对异常样本和异常样本的平均距离进行了拉离。t是一个阈值。m越大,表示我们希望异常样本之间的距离越大,λ表示我们会对不同异常之间的距离给予多大的关注。
4实验
4.1数据集和指标
我们在ShanghaiTech数据集[5]和UCF-Crime数据集[1]上进行了实验。ShanghaiTech是一个中等规模的数据集,包含437个校园监控视频。它有13个场景,光线条件和摄像机角度都很复杂。
它包含130个异常事件和超过270,000个训练帧。此外,数据集中还标注了异常事件的像素级GT。但是,该数据集的所有训练视频都是正常的。根据弱监督设置,我们跟随Zhong等人[7]的工作,将数据集分成238个训练视频和199个测试视频。UCF-Crime是一个真实世界监控视频的大规模数据集,包括13种异常事件和1900个长且未修剪的视频,其中1610个视频是带有视频级标签的训练视频,其余是带有帧级标签的测试视频。
至于度量标准,在之前的工作(Zhong等[7],Wan等[10])之后,我们还使用了帧级ROC(接收者工作特征)的曲线下面积(AUC)作为我们对上海科技和UCF-Crime的度量标准。
4.2实现细节
在[1]之后,每个视频被分成32个视频片段,即T = 32。我们的时间增强网络得到的分数范围从0到1,分数越接近0,模型越倾向于认为输入片段是正常样本,否则是异常样本。对于我们的主干,我们遵循以往的WSVAD方法[9,11],选择使用预训练的I3D[25]的mixed-5c层提取2048D片段特征。因此,对于每个视频, 我们有一个32 × 2048的特征矩阵。在我们的时间增强网络中,我们首先使用3个Conv1D层来提取片段的局部信息,然后使用上下文块来提取片段的远程时间信息。最后,我们使用3个全连接层,分别有256、32和1个节点。前两个全连接层后面是ReLU函数,最后一个层后面是Sigmoid函数。在公式1中,令m = 3。此外,在每一层全连接后实现70%的dropout。在我们的多阳性样本MIL中,我们使用了top-3个分数及其特征,并将它们分批使用来计算n对损失。
我们在Nvidia GTX-1080Ti上训练模型共10000次迭代。对于ShanghaiTech和UCF-Crime,我们将学习率设置为0.001。我们使用PyTorch来实现这些方法。
4.3 ShanghaiTech的结果
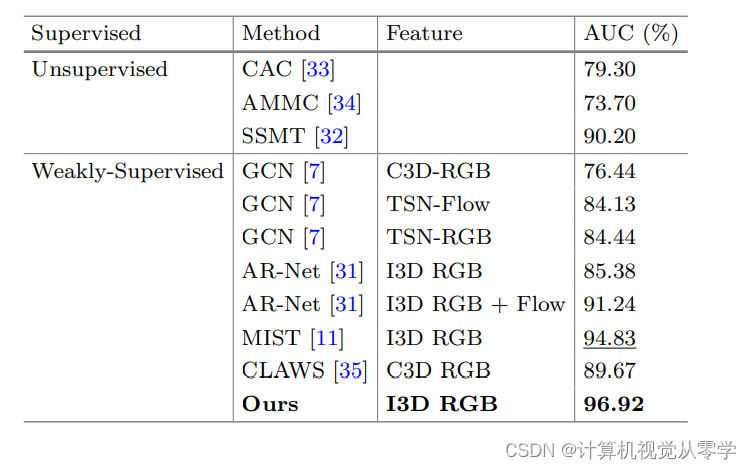
ShanghaiTech的AUC结果如表1所示。与之前最先进的无监督学习方法和弱监督方法相比,我们的方法TAI取得了良好的性能。我们的模型在这个数据集上达到了96.92%的AUC。我们的方法比SOTA无监督方法SSMT[32]高出6.7%的AUC,代价是增加了几百个视频级别标签。与采用I3D-RGB特征的现有SOTA弱监督方法MIST相比,TAI的AUC提高了2.09%。结果表明,从特征中学习的分数更具代表性和差异性。我们的模型能够很好地捕捉时间信息,而且更有效,因为我们使用了更多的正样本,并考虑了异常之间的差异。
表1:AUC与其他无监督和弱监督方法在ShanghaiTech的性能比较。
4.4 UCF-Crime的结果
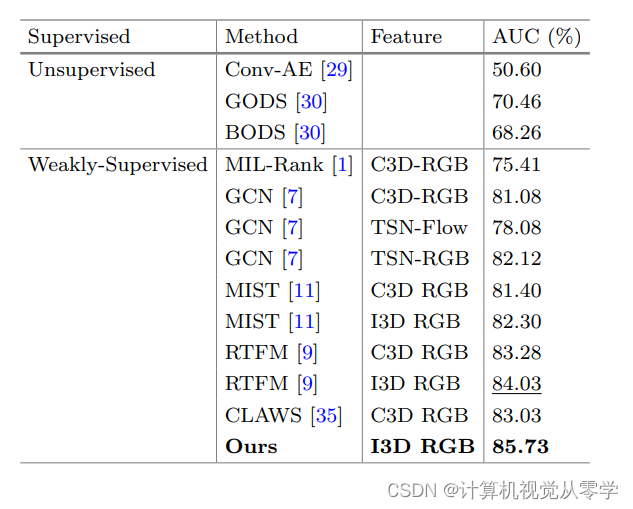
UCF-Crime的AUC结果见表2。与之前最先进的无监督学习方法和弱监督方法相比,我们的方法TAI获得了最好的性能。我们的模型在这个数据集上达到了85.73%的AUC。我们的方法TAI优于以前的无监督和弱监督学习方法。在相同的I3D-RGB特性下,TAI与MIST[11]相比,AUC提高了3.43%,与RTFM[9]相比,AUC提高了1.7%。这说明我们的模型从I3D-RGB特征中学习的分数更具代表性和差异化。更多的正样本和异常之间的差异使我们的模型表现更好。
表2:AUC与其他无监督和弱监督方法对UCF-Crime的性能比较。
4.5 消融研究
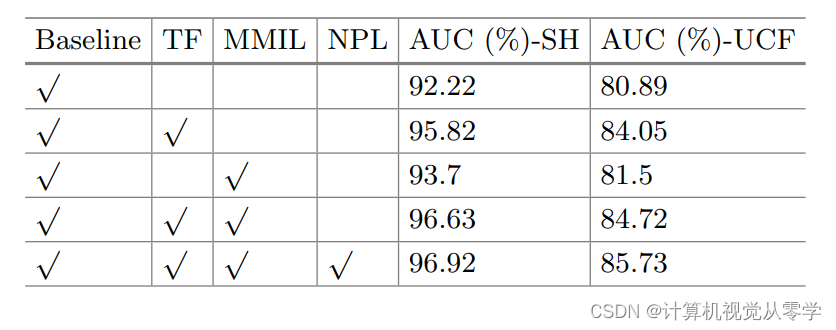
我们利用I3D特征对ShanghaiTech和UCF-Crime进行消融研究,如表3所示。时间信息增强函数S()为TF,多阳性样本MIL为MMIL, NPL表示我们提出的新的n对损失。ShanghaiTech的AUC仅为92.22%,UCF-Crime的AUC为80.89%。加入TF后,ShanghaiTech的AUC性能提高到95.82%,UCF-Crime的AUC性能提高到84.05%,说明TF模块是有用的,有效的,有助于获得更有代表性的分数。仅加入MMIL部分,在ShanghaiTech和UCF- Crime上AUC分别大幅提高到93.7%和81.5%,说明我们对原有MIL方法的改进也是有用的,它可以帮助分类器更加差异化。此外,结合TF和MMIL,ShanghaiTech的AUC增加到96.63%,UCF- Crime的AUC增加到84.72%。然后,将NPL部分加入全模型TAI在两个数据集上的最佳性能分别为96.92%和85.73%。结果如表3所示。结果表明,与其他2部分相比,TF部分贡献最大。但MMIL和NPL对于更有效地利用和捕获异常信息仍然是有用的。这些都提高了视频异常检测的性能。
表3:ShanghaiTech与UCF-Crime的消融研究。
4.6 定性分析
图3 给出了ShanghaiTech和UCF-Crime数据集的一些定性结果。我们可视化异常评分曲线(蓝色)和GT标签曲线(红色)。一般情况下,我们可以看到我们的TAI可以成功地生成帧级标签,它可以检测到很长时间的异常事件(图2(b)(c)),也可以检测到视频中的多个异常事件(图2(a))。
此外,我们还可以从图2的视频(d)中看到,我们的方法在复杂的监控视频中是有效的。
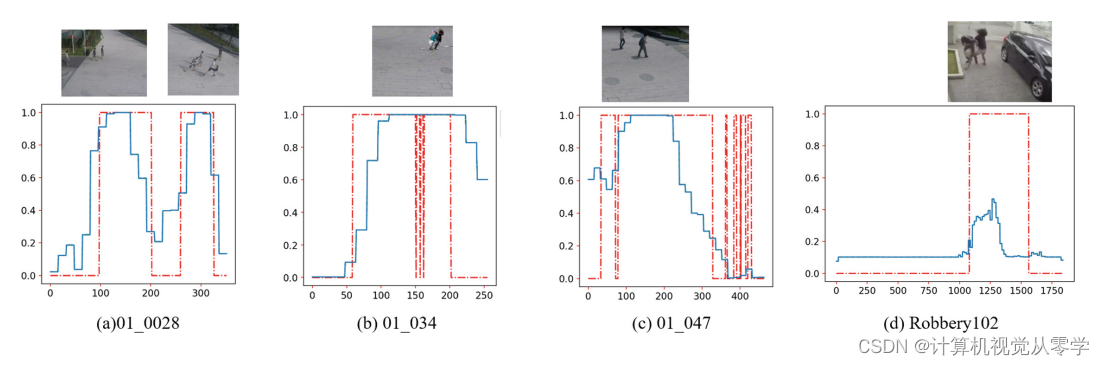
图3:异常得分曲线(蓝色)和GT得分曲线(红色)的可视化。x轴表示帧数,y轴表示异常评分。视频(a)、(b)和(c)来自ShanghaiTech数据集,视频(d)来自UCF-Crime数据集。(彩色图在线)
5. 结论
我们介绍了一种新的方法,使top-k MIL方法用于弱监督视频异常检测。我们在MIL中加入了更多的时间信息,通过相邻片段的特征来增强特征的表示能力。此外,我们在训练中更多地使用了正包中的片段及其特征。最后,我们考虑了异常之间的差异,并提出了n对损失来拉离每个异常样本之间的平均距离。我们的模型从特征中学习,考虑了更多的时间信息,使其更具代表性和差异化,我们的模型在训练过程中使用了更多的正样本,考虑了异常特征之间的差异,也使我们的模型更有效。最后,实验结果证明了我们提出的方法在UCF-Crime和ShanghaiTech数据集上的有效性。















 1258
1258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









