







LabVIEW中流水线
在当今多核处理器和多线程应用程序的世界中,程序员在开发应用程序时需要不断思考如何最好地利用尖端 CPU 的强大功能。尽管用传统的基于文本的语言构建并行代码可能难以编程和可视化,但 NI LabVIEW 等图形开发环境越来越多地允许工程师和科学家缩短开发时间并快速实现他们的想法。
由于 NI LabVIEW 本质上是并行的(基于数据流),因此多线程应用程序编程通常是一项非常简单的任务。框图上的独立任务自动并行执行,无需程序员进行额外的工作。但是那些不独立的代码片段又如何呢?在实现固有串行应用程序时,可以采取哪些措施来利用多核 CPU 的强大功能?
简介
一种被广泛接受的用于提高串行软件任务性能的技术是流水线。简而言之,流水线是将串行任务划分为可以以流水线方式执行的具体阶段的过程。
考虑以下示例:假设您正在自动化装配线上制造汽车。您的最终任务是建造一辆完整的汽车,但您可以将其分为三个具体阶段:建造框架、将零件放入其中(例如发动机)以及完成后对汽车进行喷漆。
假设搭建框架、安装零件和喷漆各需要一小时。因此,如果一次只制造一辆车,每辆车将需要三个小时才能完成(参见下图 )。

如何改进这个过程?如果我们设置一个用于框架构建的工作站,另一个用于零件安装的工作站,第三个用于喷漆的工作站,会怎么样?现在,当一辆车正在喷漆时,第二辆车可以安装零件,第三辆车可以进行框架施工。
提高性能
尽管使用我们的新工艺,每辆汽车仍需要三个小时才能完成,但我们现在可以每小时生产一辆汽车,而不是每三个小时生产一辆——汽车制造工艺的吞吐量提高了 3 倍。请注意,此示例已出于演示目的进行了简化;有关管道的更多详细信息,请参阅下面的“重要问题”部分。

LabVIEW中的基本流水线
汽车示例中所展示的相同流水线概念可以应用于任何执行串行任务的 LabVIEW 应用程序。本质上,您可以使用 LabVIEW 移位寄存器和反馈节点将任何给定的程序制成“装配线”。以下概念图显示了示例管道应用程序如何在多个 CPU 内核上运行:

重要问题
当使用流水线创建现实世界的多核应用程序时,程序员必须考虑几个重要的问题。具体来说,平衡流水线阶段和最小化内核之间的内存传输对于通过流水线实现性能提升至关重要。
平衡阶段
在上面的汽车制造和 LabVIEW 示例中,假设每个管道阶段执行的时间相同;我们可以说这些示例管道阶段是平衡的。然而,在实际应用中,这种情况很少发生。考虑下图;如果阶段 1 的执行时间是阶段 2 的三倍,那么管道化这两个阶段只会产生最小的性能提升。
非流水线(总时间 = 4 秒):

流水线(总时间 = 3s):

注意:性能提升 = 1.33X(不是流水线的理想情况)
为了纠正这种情况,程序员必须将任务从阶段 1 移至阶段 2,直到两个阶段的执行时间大致相等。对于大量的流水线阶段,这可能是一项艰巨的任务。
在 LabVIEW 中,对每个流水线阶段进行基准测试有助于确保流水线良好平衡。使用平面序列结构结合 Tick Count (ms) 函数可以最轻松地完成此操作,如图 所示。

内核之间的数据传输
最好尽可能避免在管道阶段之间传输大量数据。由于给定管道的各个阶段可以在单独的处理器内核上运行,因此各个阶段之间的任何数据传输实际上都可能导致物理处理器内核之间的内存传输。在两个处理器核心不共享高速缓存(或内存传输大小超过高速缓存大小)的情况下,最终应用程序用户可能会发现流水线效率下降。
FPGA中的流水线
流水线是一种可用于增强FPGA VI时钟速率和吞吐量的技术。在流水线设计中,用户可利用FPGA的并行处理特性提高顺序代码的有效性。如要实现流水线,必须将代码拆分为不同的级并连线每级的输入和输出端至循环中的反馈节点或移位寄存器。
下图说明了如何将由 A 和 B 代码段组成的流程进行流水线化以减少每次循环迭代的长度。使用移位寄存器可以轻松实现将数据从一个循环迭代传递到下一个循环迭代(从 A 到 B)。

可以利用流水线的一类应用程序是通过初步数据处理进行数据采集。在以下示例中,对数字输入线进行采样,测量数字信号中所有脉冲的宽度并将其写入 FIFO,以便在单独的循环中进行处理。在这两种实现中,移位寄存器用于存储数字线的状态和最后一个信号边沿的时间戳,以支持变化检测和连续信号边沿之间的时间计算。

在顶部实现中(无流水线),循环继续计算脉冲宽度(减法),并在检测到边沿时将值写入 FIFO。
在底层实现(使用流水线)中,当检测到信号边沿时,会将布尔标志写入附加移位寄存器,以便在下一个循环迭代中计算脉冲宽度并将其写入 FIFO。同时,从数字输入中获取下一个样本并与前一个样本进行比较。这使得底部循环能够检测边缘并并行处理它们并以更高的循环速率运行,从而使其能够检测更短的脉冲并在脉冲宽度测量中具有更好的定时分辨率。
下文介绍了FPGA VI在单周期定时循环内的标准执行和流水线执行。
单周期定时循环中的标准执行
在下列程序框图中,子VI A、B和C在单周期定时循环内顺序执行。因此,单周期定时循环的时钟速率必须设置为满足上述三个个运行子VI的运行时间的和值。
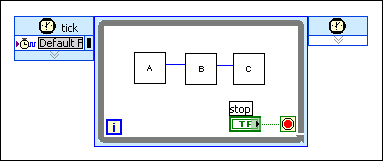
单周期定时循环中的流水线执行,使用反馈节点
在下列程序框图中,由于子VI的输入和输出连线至反馈节点,LabVIEW流水线处理子VI。在该FPGA VI中,子VI在单周期内并行执行,且最大时钟速率仅受具有最长组合路径的子VI的限制。

单周期定时循环中的流水线执行,使用移位寄存器
移位寄存器也可用于实现流水线代码,如下列程序框图所示。
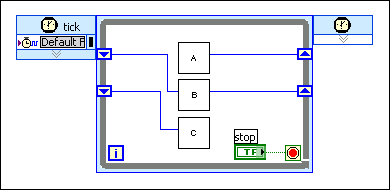
实现流水线代码
实现流水线代码时考虑下列操作:
- 最后一级的输出滞后输入的值等于流水线的级数。
- 流水线填满前,时钟周期的输出无效。
- 流水线的级数称为流水线深度。
- 流水线延迟(以时钟周期为单位)对应其深度。流水线深度为N时,第N个时钟周期前的输出无效,且每个有效时钟周期的输出比输入端延迟N-1个时钟周期。
请参考以下范例。
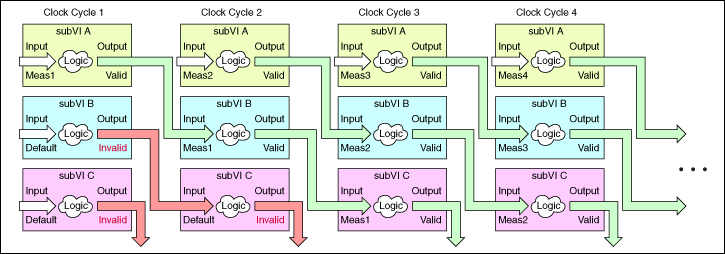
在该范例中,三个独立的执行步骤分别执行子VI A、B和C,即流水线深度为3。由于该代码需要三个执行步骤,输出要到时钟周期3才有效。每个有效时钟周期C的输出总是对应时钟周期C – (N – 1)的输入。
| 时钟周期 | 说明 |
| 时钟周期 1 | 在时钟周期1中,子VI A处理第一个测量值(Meas1),而子VI B和子VI C都处理移位寄存器的默认值(Default),产生无效输出。 |
| 时钟周期 2 | 在时钟周期2中,子VI A处理第二个测量值(Meas2),子VI B处理时钟周期1中子VI A的输出,子VI C处理来自子VI B的无效输入,从而产生无效输出。 |
| 时钟周期 3 | 在时钟周期3期间,由于所有输入都有效,并且子VI C的输出首次有效,流水线最终填满。子VI A处理第三次测量(Meas3),子VI B处理时钟周期2中子VI A的输出,而子VI C处理时钟周期2中子VI B的输出,从而产生与第一次测量(Meas1)相对应的输出。流水线填满后,全部后续时钟周期均生成有效的输出,常量延迟为两个时钟周期。 |
提示考虑使用条件结构避免无效输出导致的未预期的操作,并确保控制算法在N个时钟周期后启用执行器。
使用流水线增加吞吐量
使用流水线可增加吞吐量,因为流水线可在单周期定时循环内以更快的时钟域内运行。
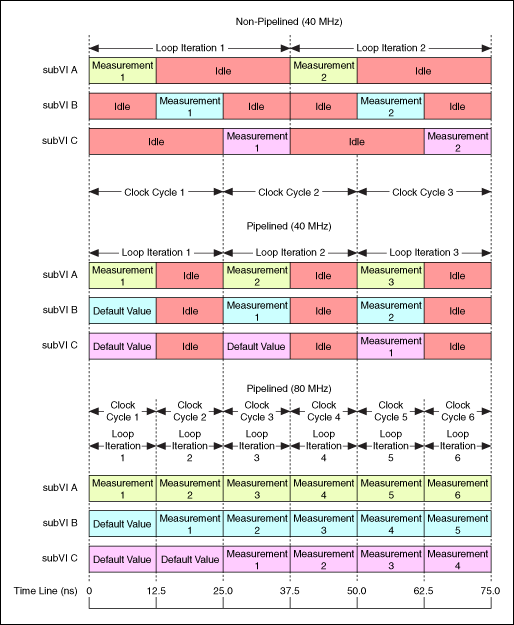
非流水线 (40 MHz)
示意图顶部为非流水线循环的执行时间。该代码包含三个子VI,每个需要12.5 ns的传播延迟。子VI A至子VI C的全部延迟为37.5 ns,相对于40 MHz编译频率,延迟时间过长。
流水线 (40 MHz)
示意图的中部给出了流水线处理代码将传播延时减少至12.5 ns,从而循环可在40 MHz进行编译。
流水线 (80 MHz)
示意图底部为使用高达80 MHz时钟速率编译的循环,因为流水线循环的传播延迟仅为12.5 ns。
















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









