







自用阅读笔记
题目:MemSum: Extractive Summarization of Long Documents Using Multi-Step Episodic Markov Decision Processes
TASK:长文本摘要(抽取式)
实验结果:


Intro:
做抽取式摘要一般就是先打分然后挑句子来组成摘要,从而导致的一个问题就是句子的分数不会根据对之前选择的句子所组成的当前部分摘要而更新,也就是说没有对历史信息的提取,这样会很容易出现冗余的情况(因为会重复选高分的句子)。
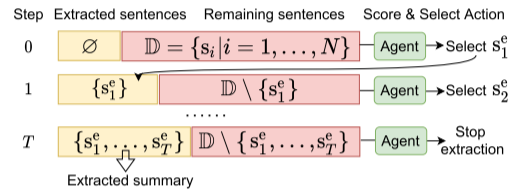
上图是文章提出来的解决办法的一个大概思路(把抽取式摘要建模成多步骤情景马尔可夫决策过程)(马尔可夫决策过程简称为MDP),一个句子在某个时间步骤时的状态分成三部分:句子自己的内容、句子在文章中的全局上下文、历史提取的信息。在每一次句子选择之前都会更新一下状态,然后根据状态打分。
文章的骨干网络是LSTM,目前用BERT不太好做长文本摘要。
Model:
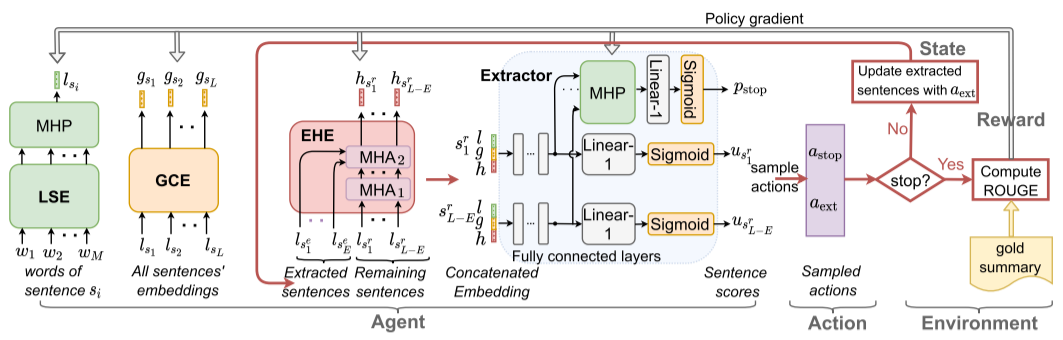
上图是一个模型架构和提取策略,图上其实写的差不多挺清楚了。
左一,输入的是一个句子的组成单词,LSE也就是local sentence encoder,用来做单词嵌入,然后再用多头池化层(MHP)(用的双向LSTM)来把单词嵌入映射到句子嵌入(lsi)上。
左二,输入的是每个句子的嵌入表示,GCE-global context encoder,全局上下文编码器(用的也是双向LSTM),得到的输出是每个句子的一个编码了全局上下文(比如句子在文档里的位置和临近句子的信息)的嵌入表示(gsi)。
左三,输入的还是所有的句子,但是分成了已经挑出来的和剩下的,输出的是剩下的每个句子的含有历史信息的嵌入表示(hsri),EHE-extraction history encoder。然后在一层里面,是有两个多头注意力子层的(MHA就是multi-head self-attention多头自注意力),一层用来处理剩下句子的嵌入表示,另一层用来处理已经挑出来的句子。
右三,Extractor,用来算句子得分的。输入是前三部分输出的连接(也就是三个状态加和),输入到ReLU的全连接层,然后接一个线性层和函数得到打分(u),同时会把全连接层得到的向量输出给MHP,来输出一个停止概率(pstop)。
最后要停就停,停了得到最终摘要来算准确度,不停就接着迭代,到停了为止。
Experiment:
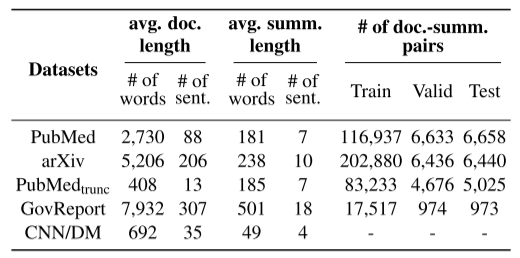
pubmedtrunc是pubmed的截断版本。
baseline还和生成式比了,搞不懂在发什么疯。实验设置细节不写了,在8块2080Ti上跑的,反正看它给的结果是高的嘞。















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









