







1 神经网络核心组件
- 层,多个层组成网络(模型)
- 输入数据和相应的目标
- 损失函数,用于学习的反馈信号
- 优化器,决定学习过程如何进行
多个层链接在一起组成了网络,将输入数据映射为预测值,然后损失函数将这些预测值与目标进行比较,得到损失值,用于衡量网络预测值与预期结果的匹配程度。优化器使用这个损失值来更新网络权重。
1.1 层:深度学习的基础组件
1.定义
- 层是神经网络的基本数据结构,是一个数据处理模块,能够将一个或多个输入张量转换为一个或多个输出张量。
- 有些层是无状态的,但大多数的层是有状态的,即层的权重。
2.不同的张量格式与不同的数据处理类型需要用到不同的层。
- 简单的向量数据保存在形状为(samples, features) 的2D张量中,通常用全连接层/密集连接层/密集层,对应于Keras的Dense类;
- 序列数据保存在形状为(samples, timesteps, features)的3D张量中,通常用循环层来处理,比如Keras的LSTM层;
- 图像数据保存在4D张量中,通常用二维卷积层来处理,如Keras的Conv2D。
3.层兼容性
- 指的是每一层只接受特定形状的输入张量,并返回特定形状的输出张量。
1.2 模型:层构成的网络
1.定义
- 模型是层构成的有向无环图
2.常见的网络拓扑结构
- 双分支(two-branch)网络
- 多头(multihead)网络
- Inception模块
1.3 损失函数与优化器:配置学习过程的关键
1.定义
- 损失函数(目标函数),在训练过程将其最小化,用于衡量当前任务是否已经成功完成;
- 优化器,决定如何基于损失函数对网络进行更新,执行随机梯度下降的某个变体。
2.具有多个输出的神经网络可能具有多个损失函数,但是梯度下降过程必须基于单个标量损失值,因此,对于具有多个损失函数的网络,需要将所有损失函数取平均,变为一个标量值。
3.选择正确的目标函数
- 对于二分类问题,使用二元交叉熵;
- 对于多分类问题,使用分类交叉熵;
- 对于回归问题,使用均方误差损失函数;
- 对于序列学习问题,使用联结主义时序分类。
2 Keras简介
2.1 Keras、TensorFlow、Theano和CNTK
1.介绍
- Keras是一个模型级的库,不处理张量操作等低层次运算。它依赖于一个Keras的后端引擎来完成运算,这是一个专门的、高度优化的张量库。
- Keras没有选择单个张量库并将Keras实现与这个库绑定。因此,几个不同的后端引擎都可以嵌入到Keras中,包括TensorFlow后端、Theano后端和CNTK(微软认知工具包)。
2.通过TensorFlow或其他后端引擎,Keras可以在CPU和GPU上无缝运行。
- 在CPU上运行,TensorFlow封装了一个低层次的张量库,叫作Eigen
- 在GPU上运行,TensorFlow封装了一个高度优化的深度学习库,叫作NAVIDIA CUDA深度神经网络库(cuDNN)
2.2 使用Keras开发
1.典型的工作流程
- 定义训练数据:输入张量和目标张量;
- 定义层组成的网络(或模型),将输入映射到目标;
- 配置学习过程,选择损失函数、优化器和需要监控的指标;
- 调用模型的fit方法在训练数据上进行迭代。
2.定义模型的两种方法
- Sequential类,仅用于层的线性堆叠;
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32, activation='relu', input_shape=(784,)))
model.add(layers.Dense(10, activation='softmax'))
- 函数式API,用于层组成的有向无环图,可以构建任意形式的架构。
input_tensor = layers.Input(shape=(784,))
x = layers.Dense(32, activation='relu')(input_tensor)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
3.编译配置学习过程
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='mse', metrics=['accuracy'])
4.训练数据
model.fit(input_tensor, target_tensor, batch_size=128, epochs=10)
3 电影评论分类:二分类问题
3.1 IMDB数据集
1.数据集介绍
IMDB数据集包含来自互联网电影数据库(IMDB)的50000条严重两极分化的评论。数据集被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集都包含50%的正面评论和负面评论。
IMDB数据集内置于Keras库,已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
2.加载IMDB数据集
(1)加载数据集
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(
num_words=10000)
- num_words=10000的意思是仅保留训练数据中前10000个最常出现的单词。
- train_data和test_data都是评论组成的列表,每条评论又是单词索引组成的列表(表示一系列单词)。
- train_labels和test_labels都是0和1组成的列表,0代表负面,1代表正面。
train_data[0]
# [1,14,22,16,43,530,973 ...]
train_labels
# array([1, 0, 0, ..., 0, 1, 0], dtype=int64)
(2)由于限定为前10000个最常见的单词,所以单词索引不会超过10000:
max([max(sequence) for sequence in train_data])
# 9999
(3)将某条评论迅速解码为英文单词:
word_index = imdb.get_word_index()
# word_index是一个将单词映射为整数序列的字典
# {'fawn': 34701, 'tsukino': 52006, 'nunnery': 52007, 'sonja': 16816 ...}
reverse_word_index = dict([(value, key) for (key, value) in
word_index.items()])
# 键值颠倒,将整数索引映射为单词
# {34701: 'fawn', 52006: 'tsukino', 52007: 'nunnery', 16816: 'sonja' ...}
decoded_review = ' '.join(
[reverse_word_index.get(i - 3, '?') for i in train_data[0]])
# 将评论解码,索引减去了3,因为0、1、2是为“padding(填充)”、
# “start of sequence(序列开始)”、“unknown(未知词)”分别保留的索引
"""
? this film was just brilliant casting location scenery story direction everyone's
really suited the part they played and you could just imagine being there robert ?
is an amazing actor and now the same being director
"""
3.2 准备数据
1.由于不能将整数序列直接输入神经网络,所以需要将列表转换为向量,有两种方法:
- 方法一:
填充列表,使其具有相同长度,再将列表转换为形如(samples, word_indices)的整数张量,然后网络第一层使用能处理这种整数张量的层(Embedding层)。 - 方法二:
对列表进行one-hot编码,将其转换为0和1组成的向量,然后网络第一层可以用Dense层,处理浮点数向量数据。
2.使用方法二将整数序列编码为二进制矩阵:
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
# 创建一个形如(len(sequences), dimension)的零矩阵
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # 将results[i]的指定索引设为1
return results
X_train = vectorize_sequences(train_data) # 将训练数据向量化
X_test = vectorize_sequences(test_data) # 将测试数据向量化
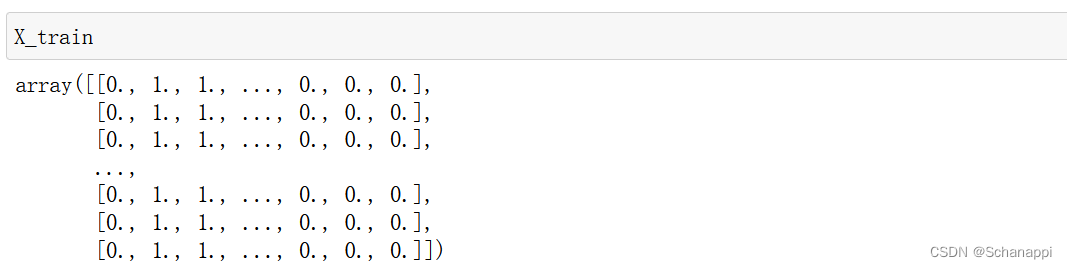
3.将标签向量化:
y_train = np.asarray(train_labels).astype('float')
y_test = np.asarray(test_labels).astype('float')
3.3 构建网络
1.对于输入数据是向量,标签是标量(1和0),带有relu激活的全连接层(Dense)的简单堆叠网络在这种问题上表现得很好。
如:
Dense(16, activation='relu')
其中,16是该层隐藏单元的个数,一个隐藏单元是该层表示空间的一个维度,每个带有relu激活的Dense层都实现了下列张量运算:
output = relu(dot(W, input) + b)
16个隐藏单元对应的权重矩阵W的形状为(input_dimension, 16),与W做点积相当于将输入数据投影到16维表示空间中(然后再加上偏置向量b并应用relu运算)。
隐藏单元越多(即更高维的表示空间),网络能学到更复杂的表示,但网络的计算代价也变得更大。
2.对于Dense层的堆叠,需要确定两个关键架构:
- 网络层数;
- 每层的隐藏单元个数。
3.该问题选择的架构
- 两个中间层,每层有16个隐藏单元;
- 第三层输出一个标量,预测当前评论的情感。
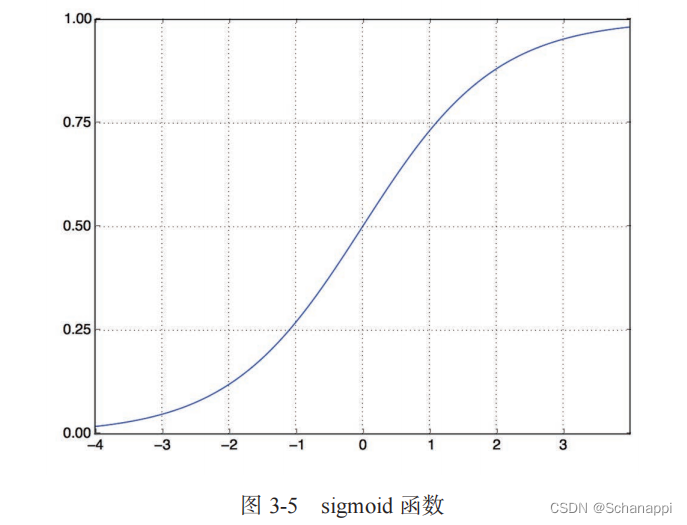
中间层使用relu作为激活函数,最后一层使用sigmoid激活输出一个0~1范围内的概率值。
-
relu(rectified linear unit, 整流线性单元),将所有负值归0

-
sigmoid函数将任意值压缩到[0, 1]区间内,其输出值可以看作概率值。
4.模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
5.编译模型
最后,需要选择损失函数和优化器。
对于二分类问题,最好使用binary_crossentropy(二元交叉熵) 损失。
(1)使用Keras内置
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
上述代码将优化器、损失函数和指标作为字符串传入,这是因为它们都是Keras内置的一部分。
(2)配置自定义优化器的参数
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
向optimizer参数传入一个优化器类实例。
(3)使用自定义的损失和指标
from keras import losses
from keras import metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
向loss和metric参数传入函数对象来实现。
3.4 方法验证
1.划分验证集
为了在训练过程中监控模型在前所未见的数据上的精度,需要将原始数据留出10000个样本作为验证集。
x_val = X_train[:10000]
partial_x_train = X_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
2.训练模型
使用512个样本组成的小批量,将模型训练20个轮次(即对x_train和y_train两个张量中的所有样本进行20次迭代)。监控10000个样本上的损失和精度。
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
调用model.fit返回了一个History对象,这个对象有一个history成员,它是一个字典,包含训练过程的所有数据。字典包含4个条目,对应训练过程和验证过程中监控的指标。
history_dict = history.history
history_dict.keys()
# dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])
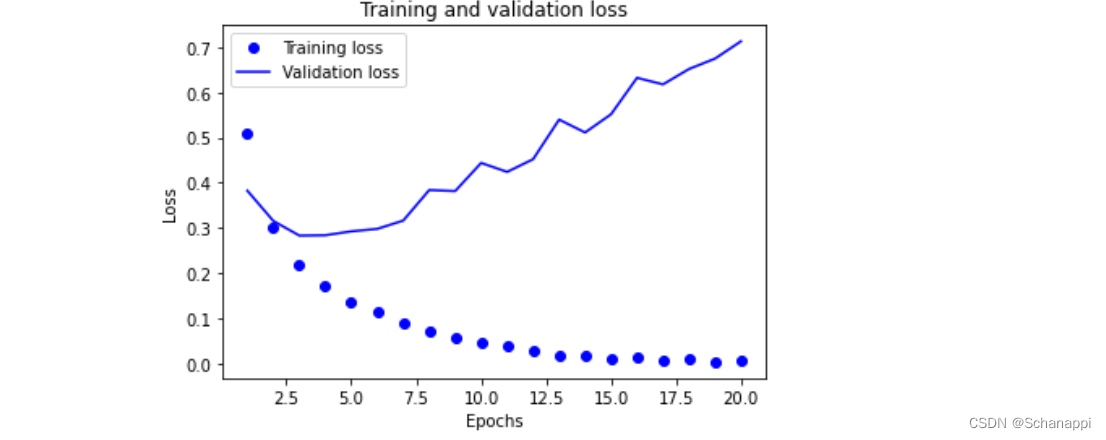
3.绘制训练损失和验证损失
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
# 'bo'蓝色圆点 'b'蓝色实线
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
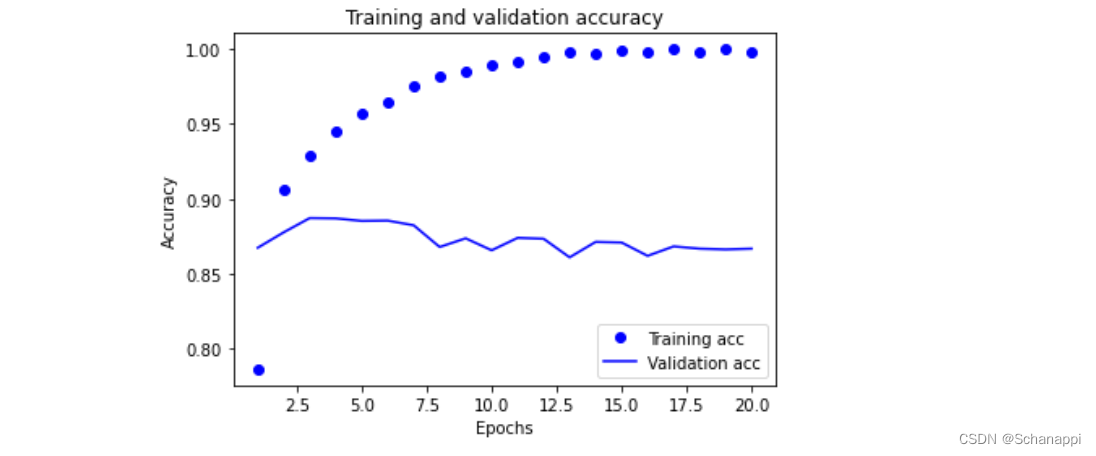
4.绘制训练精度和验证精度
plt.clf() # 清空图像
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
5.观察指标
-
从上面两个图可以发现,训练损失每轮都在降低,训练精度每轮都在提升,这事梯度下降优化的预期结果。
-
然而,验证损失和验证精度似乎在第四轮就达到了最佳值,这是一种过拟合现象:对训练数据过度优化,最终学到的表示仅针对于训练数据,无法泛化到训练集之外的数据。
6.从头开始训练一个新的网络
由于原网络存在过拟合,重新训练一个网络,共4个轮次,然后在测试集上评估模型。
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(X_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(X_test, y_test)
# [0.2920506000518799, 0.8834800124168396]
该方法能够得到88%的精度。
3.5 生成预测结果
model.predict(X_test)
"""
array([[0.1543975 ],
[0.9990451 ],
[0.8593271 ],
...,
[0.0671927 ],
[0.06409118],
[0.4176315 ]], dtype=float32)
"""
可以看出,网络对某些样本的结果非常确定(大于0.99或小于0.01),对于其他结果不那么确信。
3.6 小结
- 通常需要对原始数据进行预处理,以便将其转换为张量输入到神经网络中;
- 带有relu激活的Dense层堆叠可以解决很多问题;
- 对于二分类问题,网络的最后一层应该只有一个单元并使用sigmoid激活的Dense层,网络输出应该是0~1范围内的标量,表示概率值;
- 对于二分类问题的sigmoid标量输出,应该使用binary_crossentropy损失函数;
- 无论问题是什么,rmsprop优化器是很好的选择;
- 随着神经网络在训练数据上的表现越来越好,模型最终都会过拟合。
4 新闻分类:多分类问题
4.1 路透社数据集
1.数据集介绍
该数据集包含许多短新闻及其对应的主题,由路透社在1986年发布。包括46个不同的主题,每个主题至少有10个样本。
2.数据集加载
(1)参数num_words=10000将数据限定为前10000个最常出现的单词。
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(
num_words=10000)
(2)数据集包含8982个训练样本和2246个测试样本。
len(train_data)
# 8982
len(test_data)
# 2246
(3)每个样本都是一个整数列表(表示单词索引)。
train_data[10]
# [1, 245, 273, 207, 156,..]
(4)样本对应的标签是一个0~45范围内的整数,即话题索引编号。
train_labels[10]
# 3
4.2 准备数据
同样地,和上一个例子相同,需要将数据向量化。这里还是使用了one-hot编码(分类编码)。
- 使用自定义函数实现
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
# 训练数据和测试数据向量化
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
- 使用Keras内置方法实现
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
4.3 构建网络
主题分类问题的输出类别为46个,比电影评论分类问题的输出维度大得多。
上一个例子使用了16维的中间层,对于这个例子来说太小了,因此将使用包含64个单元的中间层。
1.模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
最后一层使用了softmax激活,网络将输出在46个不同输出类别上的概率分布——对于每一个输入样本,网络都会输出一个46维向量,其中output[i]是样本属于第 i 个类别的概率,46个概率总和为1。
2.编译模型
对于多分类问题,最好的损失函数是categorical_crossentropy(分类交叉熵),用于衡量两个概率分布直接的距离。
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
4.4 方法验证
1.划分验证集
留出1000个样本作为验证集。
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
2.训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
3.绘制训练损失和验证损失
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
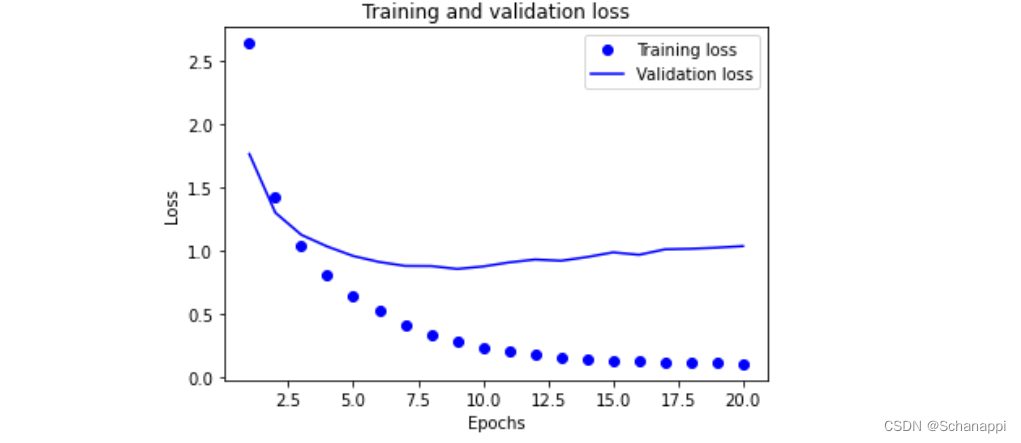
4.绘制训练精度和验证精度
plt.clf()
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
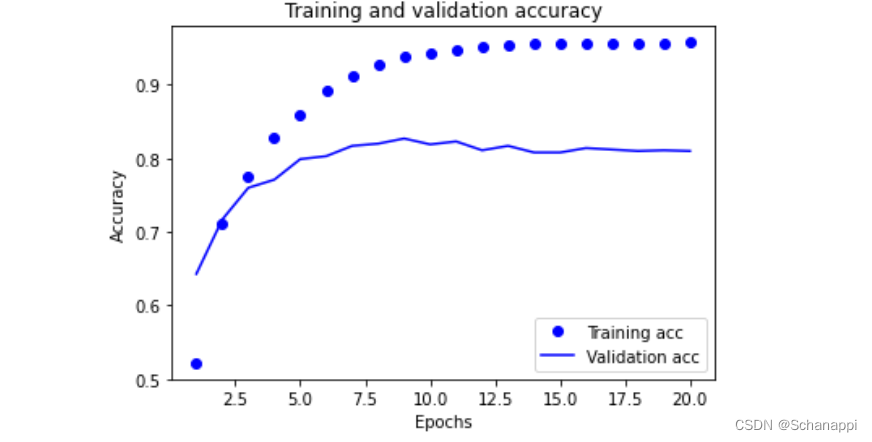
5.重新训练一个新模型
由于网络在训练9轮后开始过拟合,从头训练一个新网络,包含9个轮次,然后在测试集上评估模型。
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
# [0.9915733337402344, 0.7858415246009827]
4.5 生成预测结果
predictions = model.predict(x_test)
# predictions中的每个元素都是长度为46的向量
predictions[0].shape # (46,)
# 向量的所有元素总和为1
np.sum(predictions[0]) # 0.9999999
# 最大的元素就是预测类别,即概率最大的类别
np.argmax(predictions[0]) # 3
4.6 处理标签和损失的另一种方法
1.另一种编码标签的方法,就是将其转换为整数向量:
y_train = np.array(train_labels)
y_test = np.array(test_labels)
2.对于这种编码方法,需要改变损失函数的选择。
- 对于分类编码的标签,损失函数选择categorical_crossentropy;
- 对于整数标签,损失函数选择sparse_categorical_crossentropy。
第二个损失函数在数学上和前者完全相同,二者只是接口不同。
4.7 小结
- 对N个类别的数据点进行分类,网络的最后一层应该选择大小为N的Dense层;
- 对于单标签、多分类问题,网络的最后一层应该选择使用softmax激活;
- 对于多分类问题,损失函数应该使用分类交叉熵;
- 处理多分类问题的标签有两种方法:
- 分类编码(one-hot编码),然后使用categorical_crossentropy损失函数;
- 将标签编码为整数,使用sparse_categorical_crossentropy损失函数。
- 如果需要将数据划分到许多类别中,避免使用太小的中间层,以免在网络中造成信息瓶颈。
5 预测房价:回归问题
回归问题预测的是一个连续值而不是离散的标签。
5.1 波士顿房价数据集
1.数据集介绍
本节将要预测20世纪70年代中期波士顿郊区房屋价格的中位数,已知当时郊区的一些数据点,比如犯罪率、当地房产税率等。它包含的数据点相对较少,只有506个,分为404个训练样本和102个测试样本。
输入数据的特征都有不同的取值范围。例如,有些特性是比例,取值范围在0~1之间,有些取值为1 ~12。
2.数据集加载
from keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) =
boston_housing.load_data()
3.数据集形状
train_data.shape
# (404, 13)
test_data.shape
# (102, 13)
该数据集有404个训练样本和102个测试样本,每个样本都有13个特征。
4.数据集目标
train_targets
# array([15.2, 42.3, 50. , 21.1, 17.7, 18.5, 11.3, 15.6, 15.6,...]
目标是房屋价格的中位数,单位是千美元。
5.2 准备数据
1.数据标准化
对于取值范围差异很大的数据,需要对每个特征做标准化——对于输入数据的每个特征,减去平均值,再除以标准差,得到平均值为0、标准差为1的特征。
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data = std
用于测试数据标准化的均值和标准差是在训练数据上计算得到的,在工作流程中,不能使用在测试数据上得到的任何结果。
5.3 构建网络
- 由于样本数量很少,将使用一个非常小的网络,包含两个隐藏层,每层有64个单元。一般来说,训练数据越少,过拟合越严重,而较小的网络可以降低过拟合。
- 网络的最后一层只有一个单元,没有激活,是一个线性层,这是标量回归(预测单一连续值的回归)的典型设置。添加激活函数会限制输出范围。
- 使用mse损失函数,即均方误差(MSE),预测值与目标值之差的平方。
- 在训练过程中还监控一个新指标:平均绝对误差(MAE),它是预测值与目标值之差的绝对值。
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu',
input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop',
loss='mse',
metrics=['mae'])
return model
5.4 方法验证:K折验证
由于数据点比较少,如果像之前的划分方法,验证集也比较少。因此,验证分数会有很大的波动,这取决于所选择的验证集和训练集。
在这种情况下,可以使用K折交叉验证。这种方法将可用数据划分为K个分区(K=4/5),实例化K个相同的模型,将每个模型在K-1个分区上训练,并在剩下的一个分区进行评估。模型的验证分数等于K个验证分数的平均值。
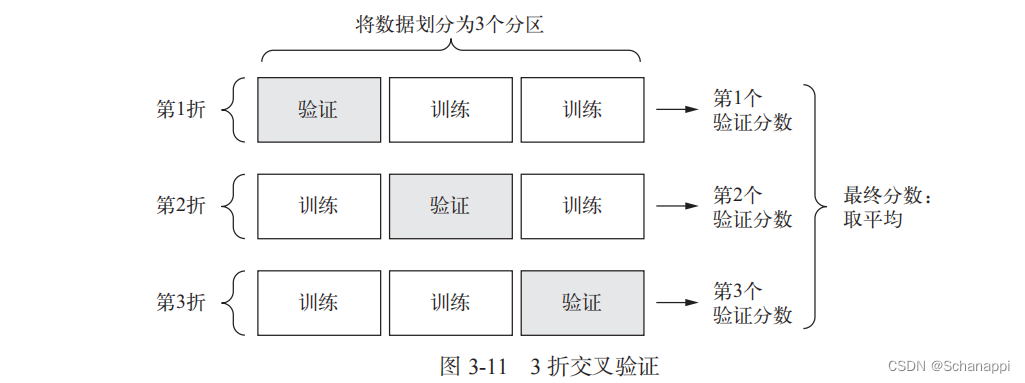
1.当epochs=100时,K折验证
import numpy as np
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
print('processing fold #', i)
# 准备验证数据:第k个分区的数据
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_target = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
# 准备训练数据:其他所有分区的数据
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
# 构建Keras模型(已编译)
model = build_model()
# 训练模型(静默模式,verbose=0)
model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs, batch_size=1, verbose=0)
# 在验证数据集上评估模型
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
运行结果如下,可以看出,每次运行模型得到的验证分数有很大差异,因此平均分数是比单一分数更可靠的指标。
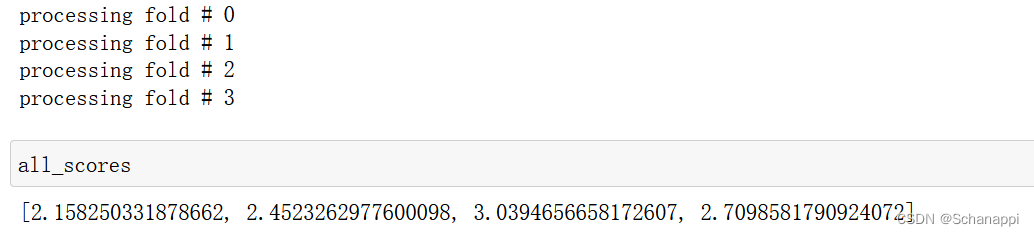
2. epochs=500,保存每折的验证结果
import numpy as np
k = 4
num_val_samples = len(train_data) // k
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
# 准备验证数据:第k个分区的数据
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
# 准备训练数据:其他所有分区的数据
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
# 构建Keras模型(已编译)
model = build_model()
# 训练模型(静默模式,verbose=0)
history = model.fit(partial_train_data, partial_train_targets,
validation_data=(val_data, val_targets),
epochs=num_epochs, batch_size=1, verbose=0)
mae_history = history.history['validation_mean_absolute_error']
all_mae_histories.append(mae_history)
3.计算所有轮次中的K折验证分数平均值
average_mae_history = [np.mean(
[x[i] for x in all_mae_histories]) for i in range(num_epochs)]
4.绘制验证分数
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history)+ 1),
average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
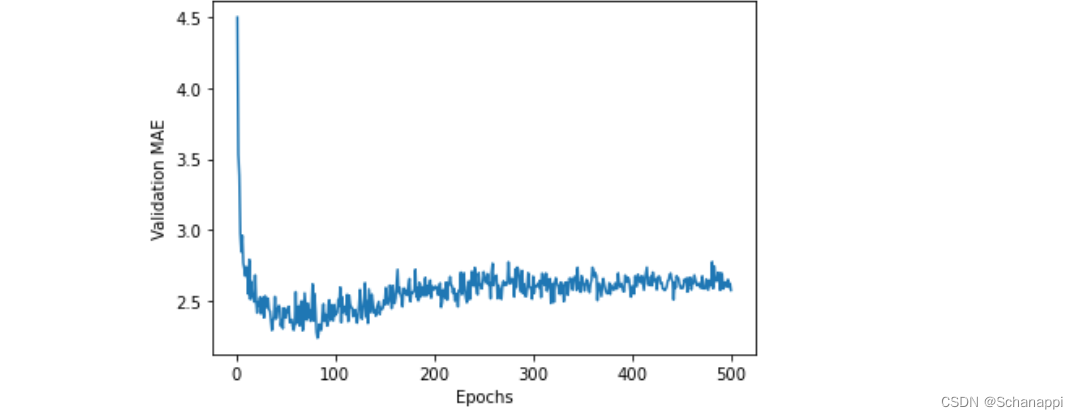
因为纵轴的范围比较大,且数据方差相对较大,所以重新进行绘制:
- 删除前10个数据点,因为它们的取值范围与曲线上其他点不同;
- 将每个数据点替换为前面数据点的指数移动平均值,得到光滑曲线。
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor +
point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
smoothed_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smoothed_mae_history) + 1),
smoothed_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
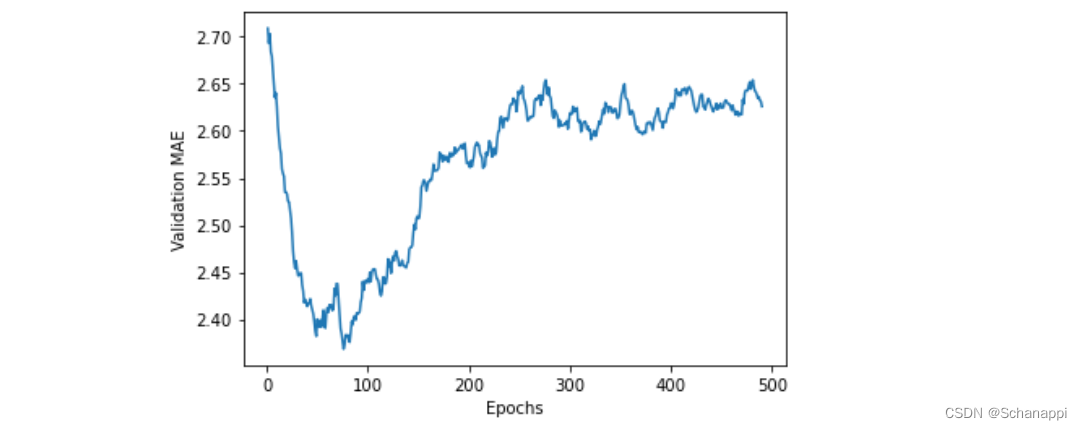
从图中可以看出,验证MAE在80轮后不再显著降低,之后开始过拟合。
5.训练模型
完成模型调参后(轮数和隐藏层大小),可以使用最佳参数在所有训练集上训练最终模型。
model = build_model()
model.fit(train_data, train_targets, epochs=80,
batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
5.5 小结
- 回归问题常用的损失函数是均方误差(MSE);
- 回归问题常用的评估指标是平均绝对误差(MAE);
- 如果输入数据的特征具有不同的取值范围,应该先进行预处理,对每个特征单独缩放;
- 如果可用的数据很少,使用K折验证可以可靠地评估模型;
- 如果可用的训练数据很少,最好使用隐藏层较小(通常只有1-2个)的小型网络,避免严重的过拟合。















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









