






这是一篇21年发表在ICCV上的一篇文章,感兴趣的可以前去下载阅读:Point Transformer
一、标题解读
Point:课上老师曾说:点云给人们提供了一种新的认识世界的方式。
相比于排列在规则像素网格上的二维图像,点云是嵌入在三维空间的集合。
Transformer:self-attention是transformer的核心,发源于NLP领域,已经在NLP、CV领域等大放异彩,其本质就是一个集合操作符(operator):元素提供位置信息这一属性,元素又被当作集合进行处理,而点云实质上就是具有位置属性的点集。且Attention机制满足点云的置换不变性,所以自注意力机制十分适合用在点云上。
- 何为置换不变性?
所谓置换不变性,就是输入点云的排列顺序。例如j1,…,jn与i1,…,in是两种不相同的顺序,这种顺序的不一致性不应该引起分类结果的不同,因此同一个fc分类函数,不同点序的同一个点云集合,其输出结果相同。
二、相关工作
基于学习的点云处理方法基本有:
一、基于投影的网络:
方法实质:将点云这种不规则的输入转化成规则的表示,将点云从3维投影到平面上转换成2维,再采用CNN中的卷积操作进行特征提取。
缺陷:
1、点云3D内部的一些几何信息容易被折叠。
2、点云稀疏性这一特点也没有被用到。
3、投影平面的选择很容易影响模型的性能。
二、基于体素的网络:
方法实质:同投影方法,也是将点云从不规则表示转化为规则表示。将点云量化到3D网格中。优点是能够很好的利用点云的稀疏性,但同样会丢失一些点云内部的几何信息。
三、基于点的网络:
方法实质:直接将点云集合作为网络的输入。
其中就有很多方法将点云连接到一个图中,并在这个图上进行消息的传递。
另一部分方法直接在3D点云中运用连续卷积。
四、基于Attention机制的网络
前人工作:在整个点云集中使用全局注意力,导致了大量的计算,且不适用于大规模的三维场景;使用标量点积注意力导致在不同的通道中共享相同的聚合权值;忽视了位置信息。
本文工作:使用局部注意力机制,使用向量注意力进行计算,对位置信息进行适当的编码。
三、Self-Attention + Point Cloud
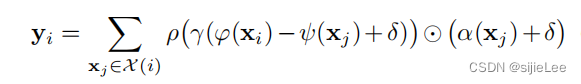
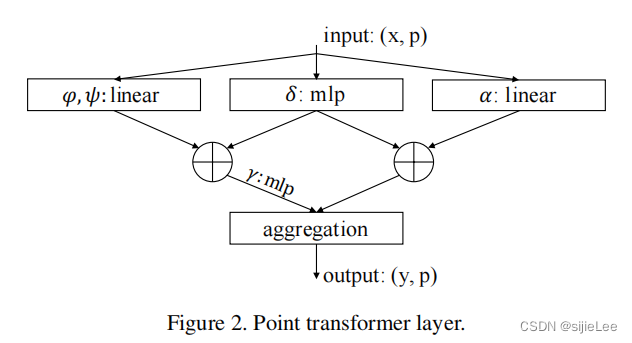 不同于二维图像的input,只需要输入代表feature的vector,点云的输入则包含(x,p)x代表该点的feature,p代表该点在空间中的位置。
不同于二维图像的input,只需要输入代表feature的vector,点云的输入则包含(x,p)x代表该点的feature,p代表该点在空间中的位置。
我们要做self-attention,那必然要计算出query和key,对于点云上任意点xi,首先使用KNN去找离它最近的k个点,这k个点组成的集合就是Xi,然后计算xi和其邻居的attention score,最后取和就是xi的output。注意:文章中采用的是向量attention,采用向量减处理query(i)和key(j)。且在value中也加上了位置信息,这都和普通的self-attention有所区别。
对self-attention还不是很了解推荐看看教学。
对点云中的每一个点都做这么一个操作,这就是point transformer。
四、网络结构
 这里作者研究的是 semantic segmentation (top) and classification (bottom)
这里作者研究的是 semantic segmentation (top) and classification (bottom)
首先看上面top部分,类似u-net,对输入(N, 32)进行降采样,将点云数量减少4倍,但是feature这一vector的维度增加了2倍。借鉴了CNN的设计思路。先逐渐降维,再逐渐升维,最后通过一个MLP把32维的feature输出来。
bottom稍有不同的倒数第二层做了一个pooling,其他都类似。
Point Transformer Block
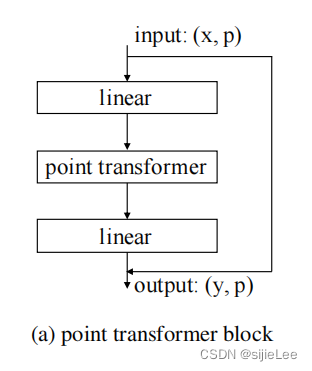
中间层 point transformer就是上文所讲的attention计算。
transition down
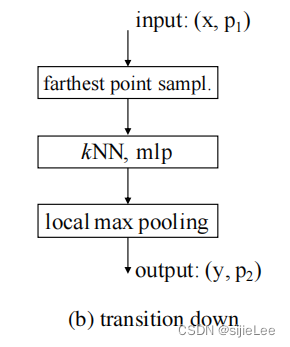
这部分就是将有N个点的point cloud降采样成N/4个点的point cloud的过程,简称编码层。
farthest point sample:

kNN, mlp:
将得到的set输入到mlp中,得到p1个vector,但是由于我们最后输出p2个点,所以需要做一个pooling。
transition up
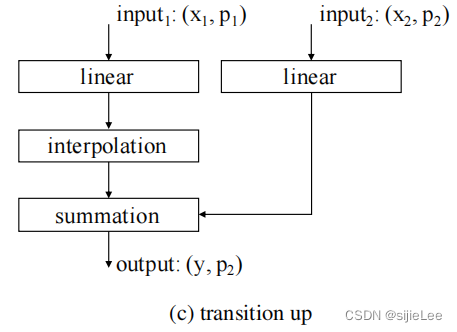
transition down后的点进行升采样,简称解码层。
由于p1是p2的子集,因此p2的容量是远大于p1的,现在的任务是把p1,p2两个点云合并成一个容量为p2的点云,更新feature为y。由于p1远远小于p2,所以我们得想办法把两个点云的容量统一到p2,这就用到了interpolation插值层,对于p1来说 只需要将以前没有的点都加进来就行,但是,这些点的feature怎么办?使用Trilinear interpolation即可解决。
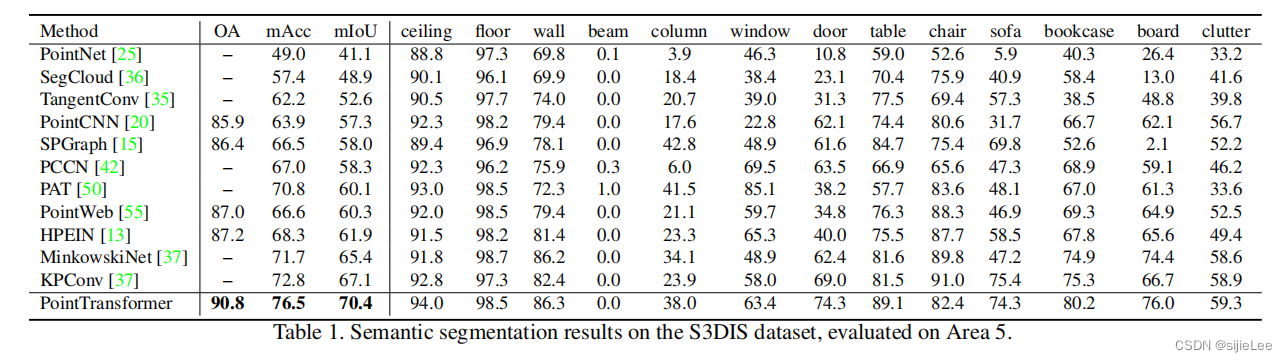
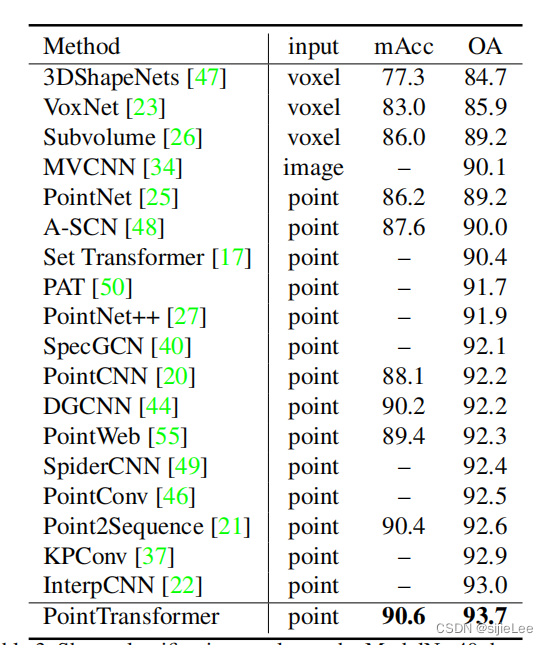
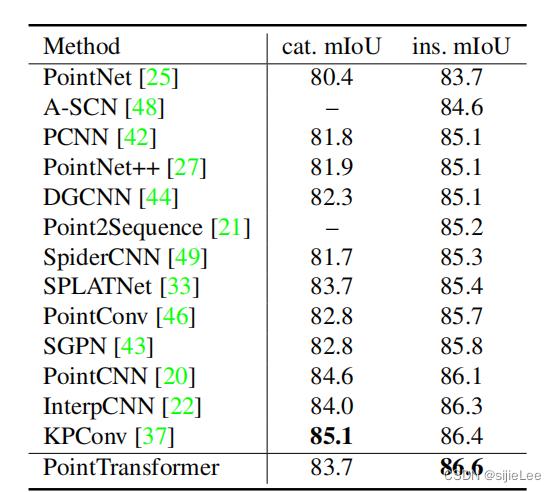
五、实验结果
如图所示,不多赘述
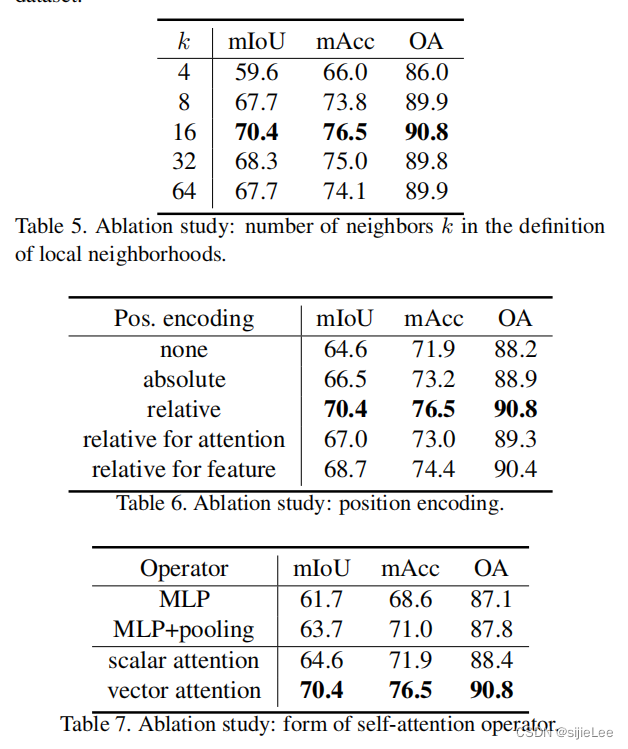
六、Ablation Study
作者测试了:
Num of neighbors
Position encoding
Attention type















 7805
7805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









