







标题党,第一次写公开博客,各位大佬轻喷
文章目录
论文:Point Transformer V3: Simpler, Faster, Stronger
代码:https://github.com/Pointcept/PointTransformerV3
中文翻译:https://zhuanlan.zhihu.com/p/673760352
相关资料:
CVPR’24开源 | PTv3:将20多个点云任务推向最高点!极高速度!
PTv3的贡献
- 简化的设计原则:大规模 > 复杂设计
- 高效的序列化邻域映射方法
- 扩展感受野: 16 -> 1024
- 多数据集联合训练
- 在效率与性能达到平衡
- 速度显著提升:PTv3比PTv2在推理延迟上加快了 3.3 倍。
- 内存消耗大幅降低:PTv3比PTv2在内存消耗上降低了 10.2 倍。
- 目前大部分数据集的 SOTA
- PTv3在多项室内和室外的3D感知任务中取得了最先进的结果,这证明了其在多种场景下的有效性和优越性。
图 1.Point Transformer V3 (PTv3) 概述。与其前身PTv2[84]相比,本文的PTv3在以下方面表现出优越性:1.性能更强。PTv3 在各种室内和室外 3D 感知任务中均取得了最先进的结果。2.更宽的感受野。受益于简单性和效率,PTv3 将感受野从 16 点扩展到 1024 点。3、速度更快。PTv3 显着提高了处理速度,使其适合对延迟敏感的应用程序。4. 降低内存消耗。PTv3 减少了内存使用量,增强了更广泛情况下的可访问性。

先验知识
如果Transformer都不清楚,请从这里补起
Transformer
【强烈推荐!台大李宏毅自注意力机制和Transformer详解!】
位置编码(Position embedding)
设计原则
针对在准确性和效率之间存在的传统权衡,PTv3提出在模型性能方面,规模的影响远大于复杂设计细节。
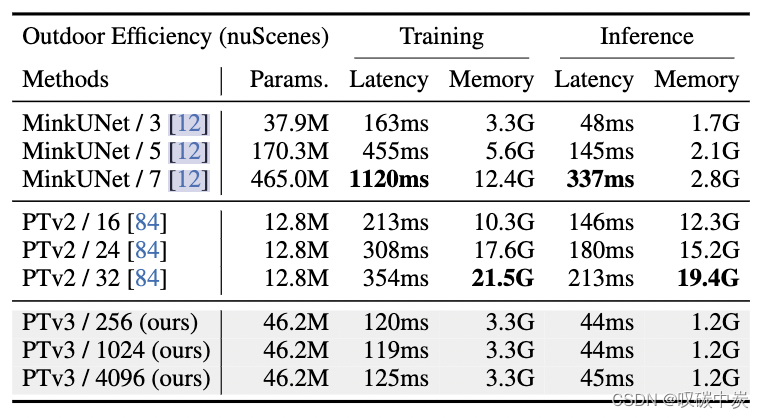
表 1. 模型效率。PTv3对不同规模的感受野的骨干网的训练和推理效率进行基准测试。批量大小固定为1,-/-后面的数字表示稀疏卷积的核大小和attention的patch大小1。
图 2. PTv2 各组件的延迟树形图。PTv3对 PTv2 的每个组件的转发时间比例进行基准测试和可视化。 KNN Query 和RPE 总共占用了 54% 的转发时间。
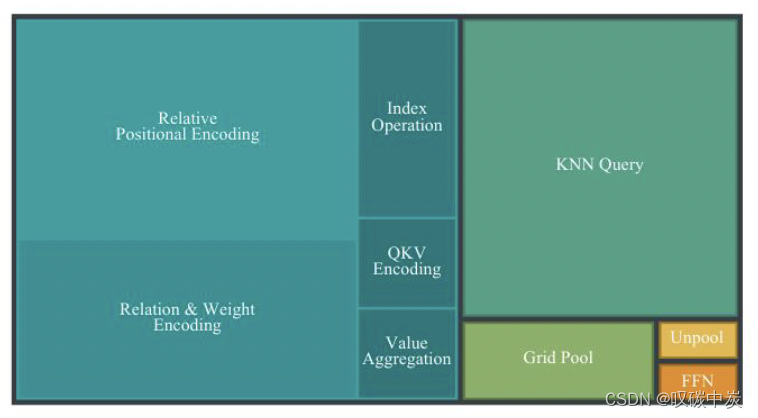
因此,PTv3优先考虑简单性和效率。
序列化映射方法(Point Cloud Serialization)
PTv3引入了点云序列化的概念,将无结构的点云数据转换为有序结构,代替了传统的KNN搜索。
这通过使用空间填充曲线(如Z-order和Hilbert曲线)来实现,这些曲线能够在保持点之间空间邻近性的同时,将点映射到一个高维离散空间中。
空间曲线(Space-filling curves)
PTv3使用空间填充曲线,如Z-order和Hilbert曲线,来遍历三维空间中的点。这些曲线能够在保持点之间空间邻近性的同时,将点映射到一个高维离散空间中。数学上,空间填充曲线可以定义为一个双射函数φ: Z^n → Z^m,其中n是空间的维度(对于点云通常是3),m是映射到的高维空间的维度。
-
Z阶曲线:
字母Z头尾相连, 简单且易于计算。 -
希尔伯特曲线:
希尔伯特画的曲线,具有优越的局部性保持特性。 -
Trans-XXX:
标准空间填充曲线通过分别沿 x、y 和 z 轴顺序遍历来处理 3D 空间。通过改变遍历的顺序,例如将 y 轴优先于 x 轴,引入了标准空间填充曲线的重新排序变体,用前缀"trans"表示。
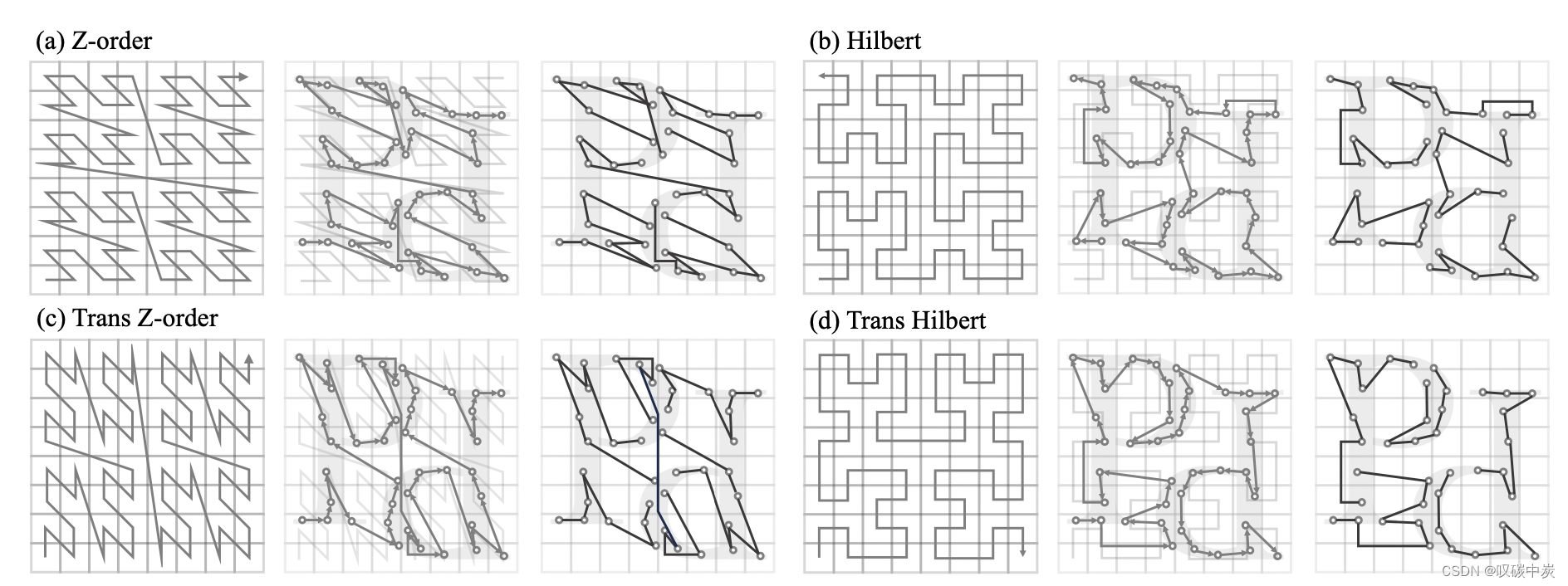
图 3.点云序列化。
PTv3通过三元组可视化展示了四种序列化模式。对于每个三元组,显示了用于序列化的空间填充曲线(左)、空间填充曲线内的点云序列化变量排序顺序(中)以及用于局部注意力的序列化点云的 grouped patches(右)。四种序列化模式的转换允许注意力机制捕获各种空间关系和上下文,从而提高模型准确性和泛化能力。
可参考的资料:
序列化编码(Serialized encoding)
序列化编码是这个过程的关键部分,它将点的位置转换为一个整数序列,反映其在给定空间填充曲线中的顺序。
具体来说,通过将点的位置投影到一个离散空间,并使用空间填充曲线的逆映射φ^(-1)来生成序列化代码。这个过程可以写成:
其中,p是点的位置,b是批次索引,g是网格大小,<<表示左移位操作,|表示位或操作。
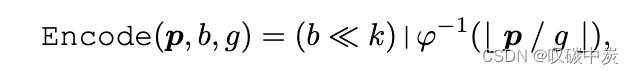
在PTv3的序列化编码过程中,位操作是用来将批次索引和序列化编码合并成一个单一的整数的过程。这个过程涉及到两个主要的位操作:左移和位或。
左移
左移操作(通常表示为符号<<)是一种位操作,它将一个数的所有位向左移动指定的位数。在二进制表示中,这意味着每个位都向左移动,右边空出的位用0填充。左移操作在数学上等同于乘以2的幂。
例如,如果我们有一个二进制数0b101(十进制的5),并且我们对它进行一次左移操作(<< 1),结果将是0b1010(十进制的10)。
位或
位或操作(通常表示为符号|)是一种位操作,它对两个数的每一位进行比较,如果任一位为1,则结果位也为1,否则为0。
例如,如果我们有两个二进制数0b101和0b100,进行位或操作的结果将是0b101 | 0b100 = 0b101。
序列化编码中的位操作
PTv3不会对点云进行物理重新排序,而是记录序列化过程生成的映射。
在PTv3的序列化编码中,每个点被分配一个64位的整数来记录序列化代码和批次索引。序列化代码是通过空间填充曲线的逆映射φ^(-1)得到的,而批次索引b是一个整数,用于区分不同的数据批次。
位操作的过程如下:
- 首先,通过左移操作将批次索引b向左移动k位。这样做是为了在整数的高位部分为序列化代码腾出空间。
- 接下来,计算序列化代码,这是通过空间填充曲线的逆映射得到的点的顺序编码。
- 最后,使用位或操作将左移后的批次索引和序列化代码合并。这样,序列化代码就被放置在整数的低位部分,而批次索引保持在高位部分。
def encode(point, batch_index, grid_size, bits_for_batch_index):
# 计算序列化代码
serialization_code = inverse_mapping(point, grid_size)
# 将批次索引左移k位
shifted_batch_index = batch_index << bits_for_batch_index
# 使用位或操作合并批次索引和序列化代码
encoded_point = shifted_batch_index | serialization_code
return encoded_point
在这个过程中,位操作确保了每个点的序列化编码是唯一的,并且可以很容易地从编码中恢复出原始的批次索引和序列化代码。
通过这种方式,PTv3能够有效地处理批量的点云数据,同时保持点云的结构化序列化形式,这对于后续的注意力机制和模型的效率至关重要。
序列化注意力(Serialized Attention)
从窗口注意力演变而来,PTv3定义了补丁注意力,这是一种将点分组为不重叠补丁并在每个单独补丁内执行注意力的机制。补丁注意力的有效性依赖于两个主要设计:补丁分组和补丁交互。
补丁分组(Patch grouping)
在序列化点云的基础上,根据补丁大小对点进行分组。这个大小可以根据具体任务和计算资源进行调整。这种分组策略有助于在 局部 区域内应用注意力机制,并且可以有效地扩展模型的感受野。每个补丁内的点在原始点云中是空间邻近的。
PTv3在图 3 中的三元组右侧部分说明了从四种序列化模式派生的补丁分组模式。虽然与KNN相比,这种方法可能会牺牲一些邻居搜索精度,但效率和可扩展性的提高远远超过邻域精度的微小损失。
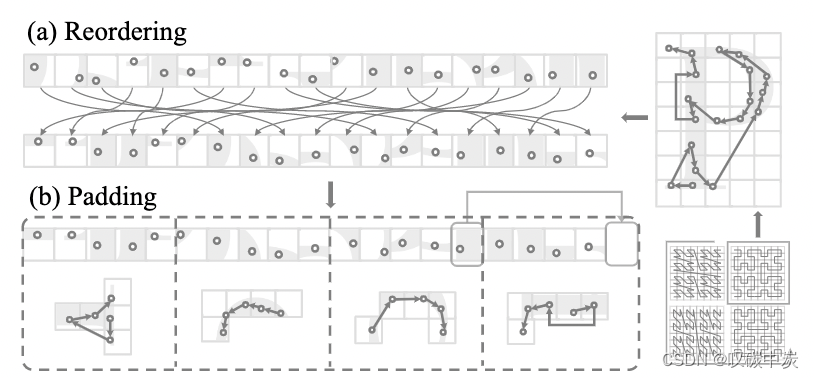
图 4. 补丁分组。 (a)根据从特定序列化模式派生的顺序对点云进行重新排序。 (b)通过借用相邻补丁的点来填充点云序列,以确保它可以被指定的补丁大小整除。
补丁交互(Patch interaction)
PTv3的补丁交互是其核心特性之一,它允许模型在不同补丁(patch)之间进行信息交换,从而增强了模型对点云 全局 结构的理解。
补丁交互的设计对于提高模型性能至关重要,尤其是在处理大规模点云数据时。以下是PTv3中几种主要的补丁交互策略的详细介绍:
1. Shift Dilation(扩张位移)
Shift Dilation策略通过在序列化点云中以固定步长移动补丁来实现扩张效果。这种方法类似于卷积神经网络中的膨胀卷积,可以增加模型的感受野,使其能够捕捉到更广泛的空间关系。在PTv3中,Shift Dilation通过在序列化点云的不同区域应用不同的位移步长来实现,从而允许模型在不同的尺度上捕捉局部和全局特征。
2. Shift Patch(位移补丁)
Shift Patch策略受到图像处理中窗口滑动注意力机制的启发。在这种策略中,补丁的位置在序列化点云中进行位移,以最大化不同补丁之间的交互。这种方法可以增强模型对点云中不同区域之间关系的捕捉能力,从而提高模型的全局感知能力。
这个机制见文章2.2节。滑动得到9个窗口,为了减少计算移动成4个窗口。
3. Shift Order(位移顺序)
Shift Order策略通过动态改变序列化点云中点的顺序来实现。在每个注意力层之间,点的序列化顺序会被重新排列,这种方法可以防止模型过度拟合到某一特定的序列化模式,并促进特征在不同层之间的有效流动。通过这种方式,模型能够学习到更加鲁棒的特征表示。
4. Shuffle Order(随机顺序)
Shuffle Order是在Shift Order的基础上进一步发展的策略。除了动态改变序列化点云中点的顺序外,Shuffle Order还引入了随机性,通过随机打乱序列化顺序来增加模型的泛化能力。这种随机性可以确保模型不会依赖于特定的序列化模式,从而在面对多样化的点云数据时具有更好的适应性。
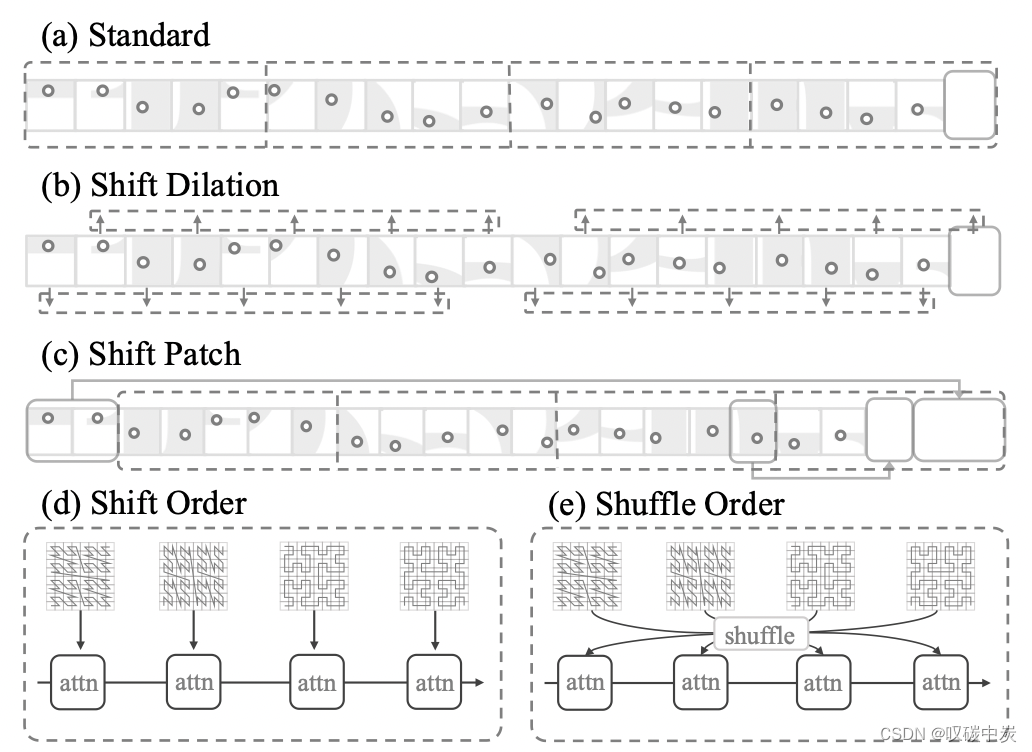
图 5. 补丁交互。 (a) 标准分组,具有规则的、非移位的排列; (b) 平移扩张,其中点按规则聚合,产生扩张效果; © 位移补丁,它采用类似于移位窗口方法的移位机制; (d) 位移顺序,其中不同的序列化模式被循环分配给连续的注意力层; (d) 随机顺序,序列化模式的序列在输入到注意层之前是随机的。
补丁交互的设计使得PTv3能够有效地处理大规模点云数据,同时保持高效的计算性能。
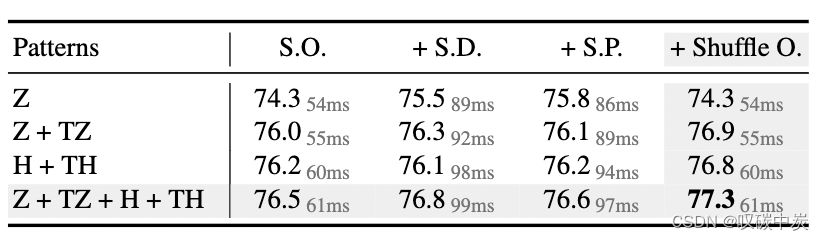
表 2. 序列化模式和补丁交互。第一列表示序列化模式:Z 表示Z 顺序,TZ 表示 Trans Z 顺序,H 表示 Hilbert,TH 表示Trans Hilbert。第一排,S.O. 代表 Shift Order,这是默认设置,也适用于其他交互策略。 S.D. 代表 Shift Dilation,S.P. 表示 Shift Patch。
有关网络设计的细节说明请看文章4.3
> 图6 整体架构
打*的地方是PTv3的主要提案,消融实验充分证明了这些模块对模型性能的提升效果。
增强条件位置编码:xCPE
PTv3提出了一种新的xCPE,它通过在注意力层之前直接插入一个稀疏卷积层来实现,该层具有跳跃连接(skip connection)。xCPE和序列化编码的结合使用,使得PTv3能够有效地捕捉点云数据的全局和局部特征,同时保持了模型的可扩展性和计算效率。
相对位置编码(RPE):
在一些早期的点云处理模型中,如Swin3D,Point Transformer,通常使用相对位置编码(Relative Positional Encoding, RPE)。RPE通过计算点之间的欧几里得距离来生成位置编码,这种方法能够有效地捕捉局部空间结构,但计算成本较高,尤其是在大规模点云中。
条件位置编码(CPE):
一些后续的模型,如OctFormer,引入了条件位置编码(Conditional Positional Encoding, CPE),它通过八叉树(Octree)结构来生成位置编码,这种方法在效率上有所提升,但PTv3认为单个CPE仍不足以实现峰值性能。
表 3. 位置编码。PTv3将提议的 CPE+ 与 APE、RPE、cRPE 和 CPE 进行比较。 OctFormer[77]中讨论了 RPE 和 CPE,而 Swin3D[95]则部署了 cRPE。
[77]Peng-Shuai Wang. Octformer: Octree-based transformers for 3D point clouds. SIGGRAPH, 2023. 2, 3, 5, 6, 7, 8, 10, 11
[95]Yu-Qi Yang, Yu-Xiao Guo, Jian-Yu Xiong, Yang Liu, Hao Pan, Peng-Shuai Wang, Xin Tong, and Baining Guo. Swin3d: A pretrained transformer backbone for 3d indoor scene understanding. arXiv:2304.06906, 2023. 2, 3, 6, 7, 8, 11

实验结果表明,与标准 CPE 相比,xCPE 充分释放了性能,但延迟略有增加几毫秒,性能提升证明了这一微小权衡的合理性。
多数据联合训练策略
通过跨多个3D数据集的协同学习进一步提升了模型的泛化能力和性能。PTv3通过这种策略,结合其内在的扩展感知范围的能力,实现了在超过20个下游任务中的最先进结果,无论是在室内还是室外场景中。
总结
本文仅仅对PTv3的网络设计部分进行了简单的介绍。
具体实验结果请看相关资料。
Ps:FlashAttention也对PTv3性能有至关重要的作用

















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









