









《OpenShift / RHEL / DevSecOps 汇总目录》
文本已在OpenShift 4.10环境中进行验证。
场景说明
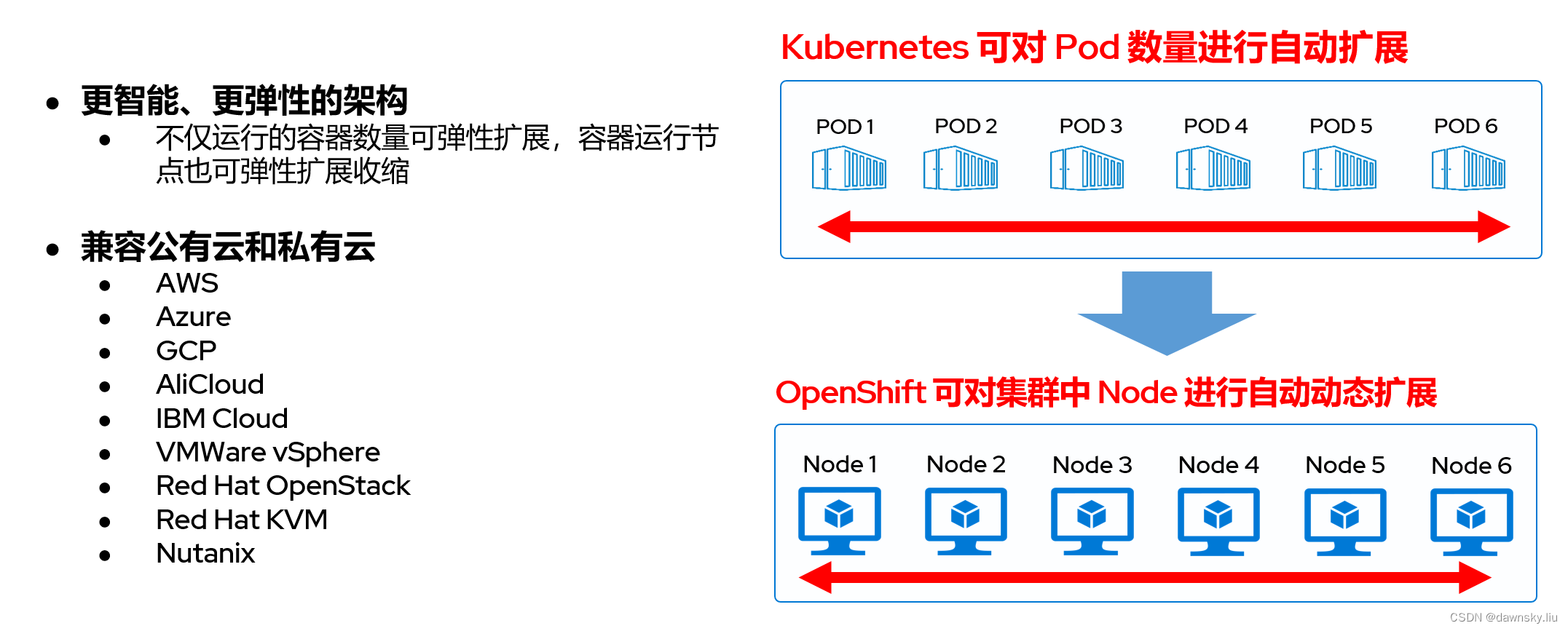
当 Pod 消耗的 CPU/内存较高时,我们可以使用 Kubernetes 提供的 Horizontal Pod Autoscaler 功能对 Deployment 中的 Pod 副本数进行自动化扩展。不过如果可供 Kubernetes 集群使用的 CPU/内存 已经没有富裕的时候,就无法通过增加 Pod 数量实现处理的弹性扩展。
类似 Horizontal Pod Autoscaler 实现的 Pod 自动化扩展/收缩,OpenShift 提供了 ClusterAutoScaler 和 MachineAutoScaler 功能来实现自动化 Worker 节点的扩展/收缩。当集群中当前 Worker 节点的资源再也无法处理 Pod 对资源的使用要求后,OpenShift 就可以通过 MachineAutoScaler 自动触发 MachineSet 来扩展集群的 Worker 节点。
需要注意的是,这种方式只能针对通过 IPI 安装的 OpenShift 集群。
配置节点自动扩展
- 执行以下命令创建 ClusterAutoscaler 和 MachineAutoscaler 对象。其中 cores/memory 的 min/max 指的是集群包括的 cores/memory 总量。
$ cat << EOF | oc apply -f -
apiVersion: "autoscaling.openshift.io/v1"
kind: "ClusterAutoscaler"
metadata:
name: "default"
spec:
resourceLimits:
cores:
max: 128
min: 8
maxNodesTotal: 24
memory:
max: 512
min: 8
scaleDown:
delayAfterAdd: 10m
delayAfterDelete: 5m
delayAfterFailure: 30s
enabled: true
unneededTime: 5m
EOF
- 查看当前 MachineSet,并获取 MachineSet 的名称。
$ oc get machineset -n openshift-machine-api
$ MACHINESET_NAME=$(oc get machineset -n openshift-machine-api --no-headers -o custom-columns=NAME:metadata.name | grep worker)
- 根据 MachineSet 名称创建 MachineAutoscaler。如果有多个 MachineSet 可以创建多个 MachineAutoscaler。
$ cat << EOF | oc apply -f -
apiVersion: "autoscaling.openshift.io/v1beta1"
kind: "MachineAutoscaler"
metadata:
name: "my-machine-autoscaler"
namespace: "openshift-machine-api"
spec:
minReplicas: 1
maxReplicas: 12
scaleTargetRef:
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
name: ${MACHINESET_NAME}
EOF
验证自动扩展节点
启动观察
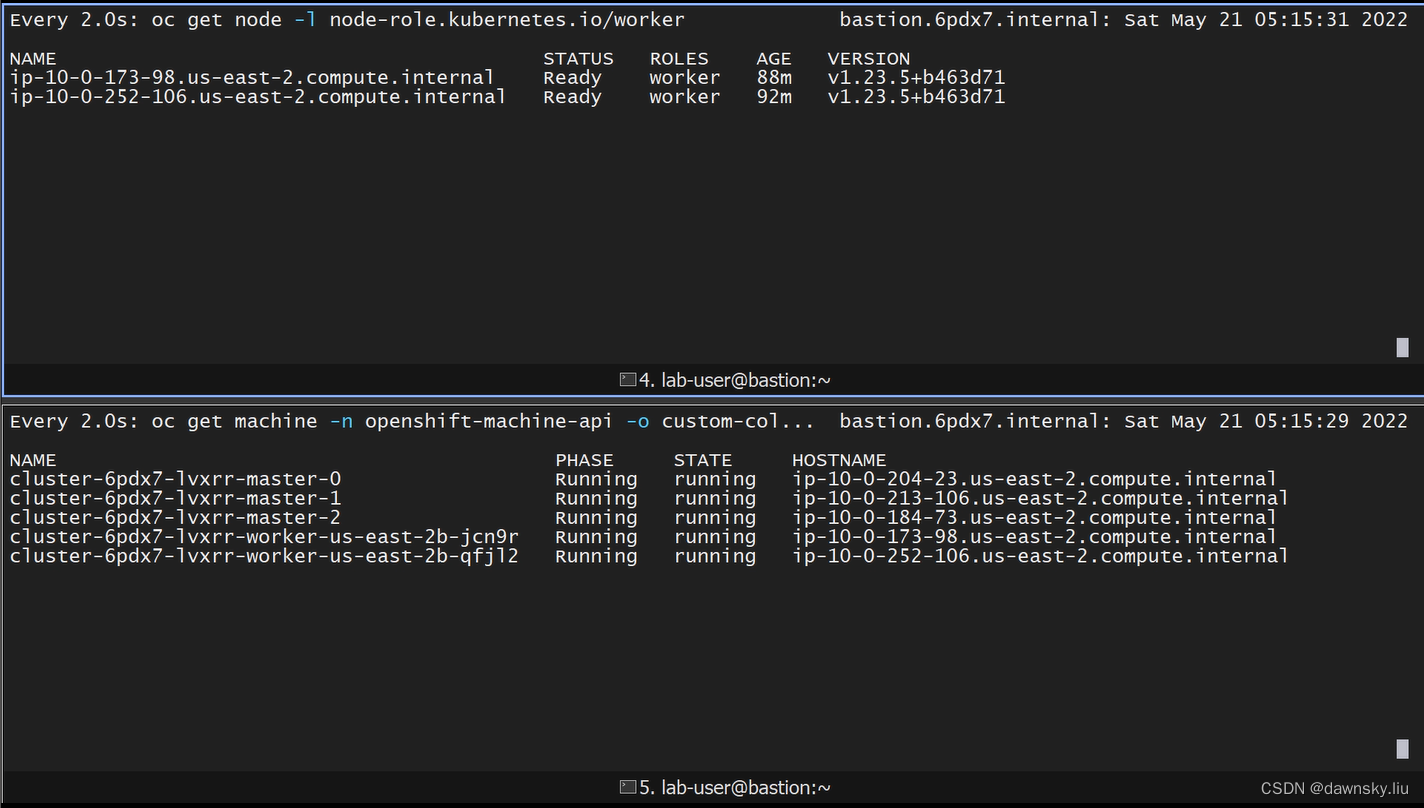
分别在 2 个终端运行以下命令,持续观察集群的 Worker 节点和 Machine 的数量和状态。
$ watch oc get node -l node-role.kubernetes.io/worker
$ watch oc get machine -n openshift-machine-api -o custom-columns=NAME:metadata.name,PHASE:status.phase,STATE:status.providerStatus.instanceState,HOSTNAME:status.nodeRef.name
部署测试应用
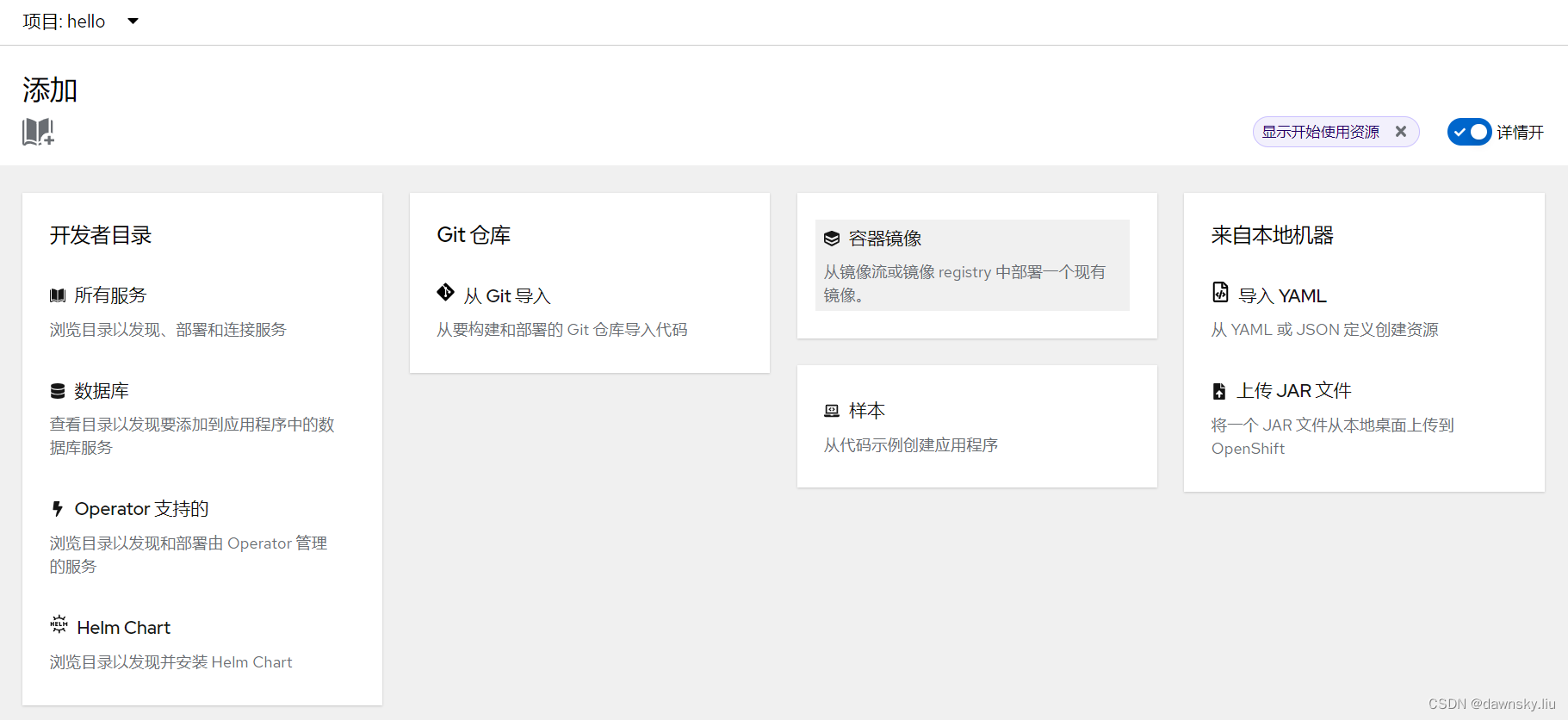
- 创建 hello 项目,然后通过 “开发者”视图进入 “添加”菜单。点击 “容器镜像”,然后部署名为 “openshift/hello-openshift” 的镜像。
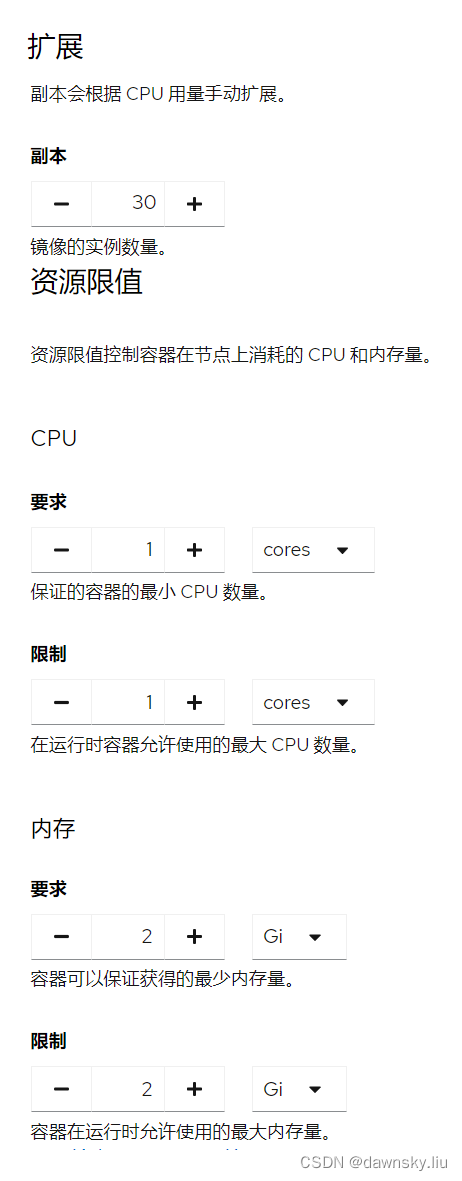
- 根据每个 Worker 节点有的 CPU或内存量配置运行 Pod 的副本数量和每个 Pod 使用的 CPU/内存。注意:Pod 申请使用的资源总量要超过全部 Worker 节点的可用量。
- 最后创建应用即可。
观察节点扩展过程
- 在 Machine 观察窗口中查看到已经有新的 Machine 出现,先是 Provisioning 状态,然后是 Provisioned 状态。
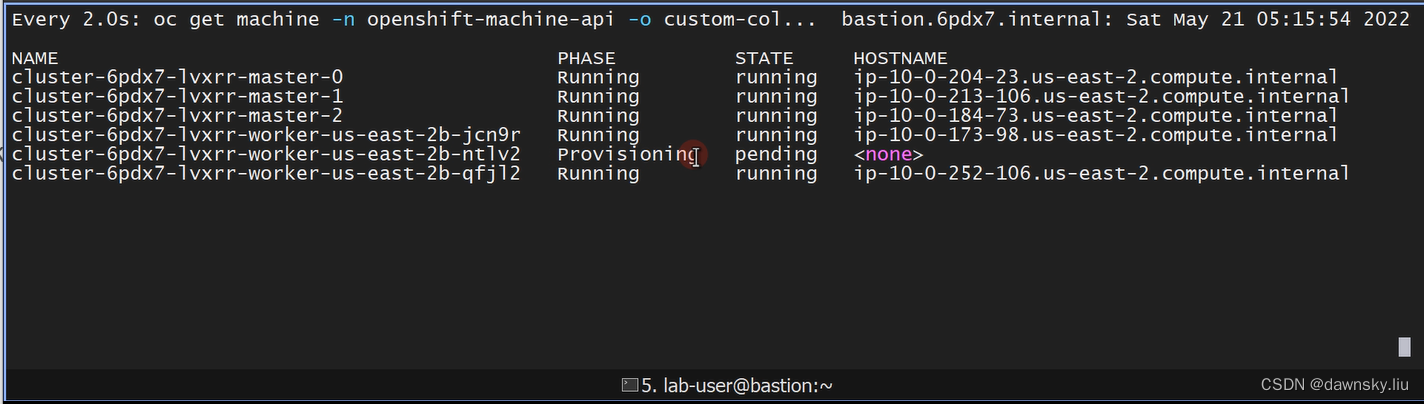
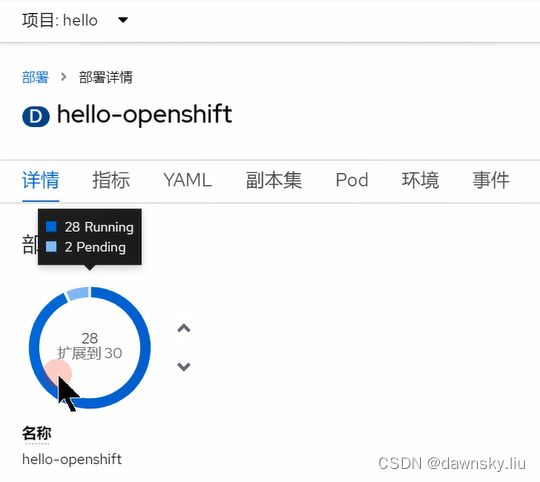
- 在 hello-openshift 的部署界面中可以看到有 pod 一直处于 Pending 状态。
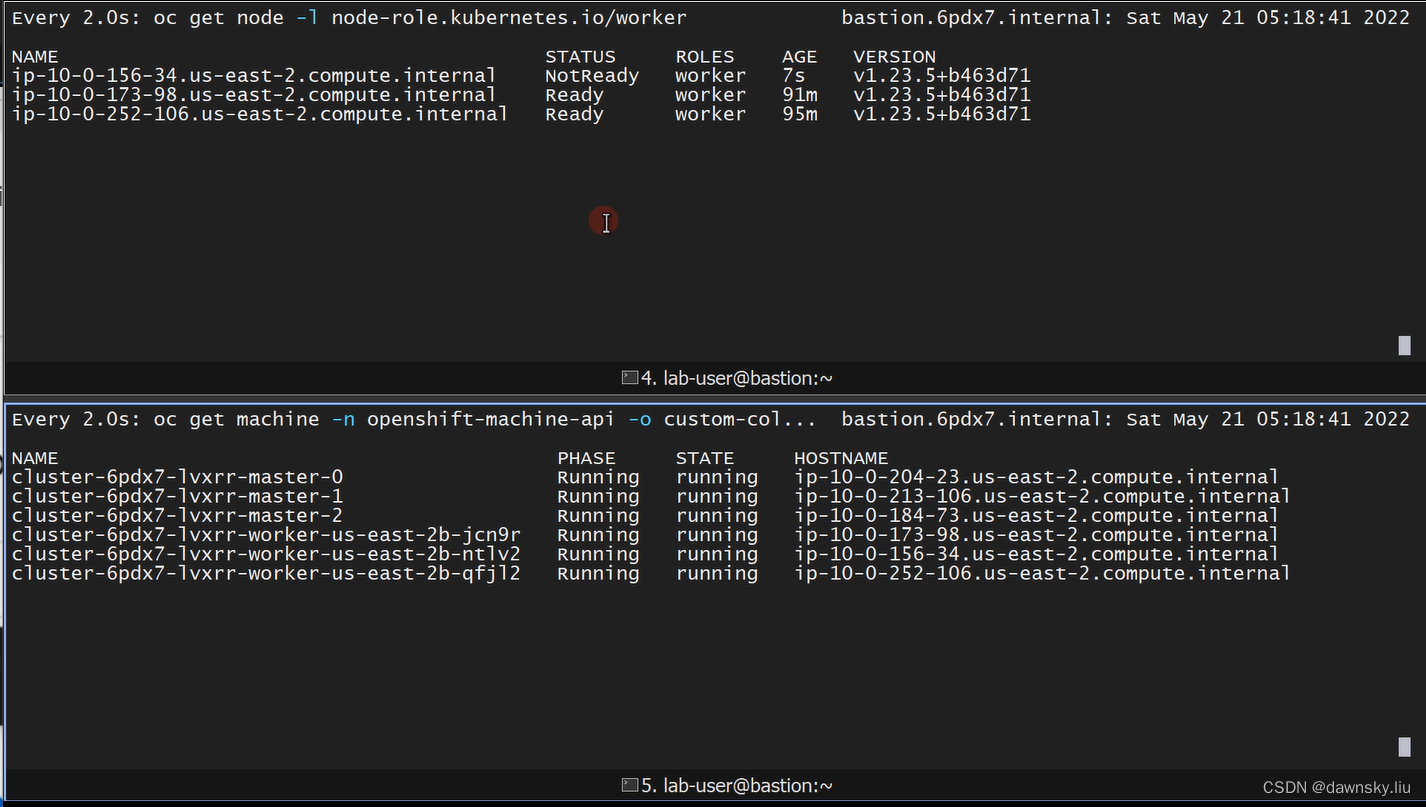
- 当新建的 Machine 进入 Running 状态后,会在 Node 观察窗口中出现新的 Worker 节点,其状态会从 NOTReady 转到 Ready。
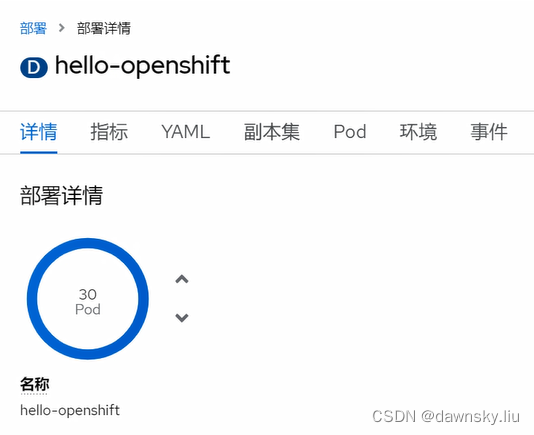
- 再次查看 hello-openshift 的部署状态,确认全部 Pod 已经运行起来。
演示视频
参考
https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md#how-does-cluster-autoscaler-work-with-pod-priority-and-preemption
https://notes.elmiko.dev/2020/10/22/hacking-on-openshift-autoscaler.html

















 1823
1823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









