







文章目录
数据集及其拆分
1. 类别标签的ground truth与gold standard
- ground truth:可翻译为地面实况等。在机器学习领域一般用于表示真实值、标
准答案等,表示通过直接观察收集到的真实结果 - gold standard:可翻译为金标准。医学上一般指诊断疾病公认的最可靠的方法。
2. 数据集与有监督学习
有监督学习中数据通常分成训练集、测试集两部分。
- 训练集(training set):用来训练模型,即被用来学习得到系统的参数取值
- 测试集(testing set):用于最终报告模型的评价结果,因此在训练阶段测试
集中的样本应该是unseen的。
有时对训练集做进一步划分为训练集和验证集(validation set)。验证集与测试集类似,
也是用于评估模型的性能。区别是验证集主要用于模型选择和调整超参数,因而一般不
用于报告最终结果
3. 训练集、测试集的拆分
3.1 留出法
数据拆分步骤:
- 将数据随机分为两组,一组做为训练集,一组做为测试集
- 利用训练集训练分类器,然后利用测试集评估模型,记录最后的分类准确率为此分类器的性能指标
3.2 K折交叉验证(常用)
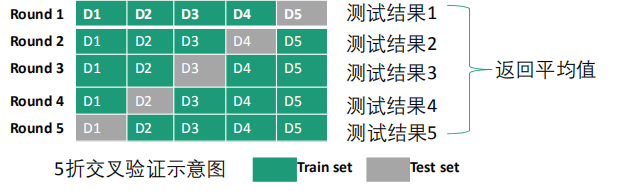
过程:
- 数据集被分成K份(K通常取5或者10)
- 不重复地每次取其中一份做测试集,用其他K‐1份做训练集训练,这样会得到K个评价模型
- 将上述步骤2中的K次评价的性能均值作为最后评价结果
分层抽样策略(Stratified k‐fold) :
将数据集划分成k份,特点在于,划分的k份中,每一份内各个类别数据的比例和原始数据集中各个类别的比例相同。
用网格搜索来调超参数
- 超参数:
在学习过程之前需要设置其值的一些变量,而不是通过训练得到的参数数据。如深度学习中的学习速率等就是超参数。 - 网格搜索:
- 假设模型中有2个超参数:A和B。 A的可能取值为{a1, a2, a3},B的可能取值为连续的,如在区间[0‐1]。由于B值为连续,通常进行离散化,如变为
{0, 0.25, 0.5, 0.75, 1.0} - 如果使用网格搜索,就是尝试各种可能的(A, B)对值,找到能使的模型取
得最高性能的(A, B)值对。
网格搜索与K折交叉验证结合调整超参数
- 确定评价指标;
- 对于超参数取值的每种组合,在训练集上使用交叉验证的方法求得其K次评价的性能均值;
- 最后,比较哪种超参数取值组合的性能最好,从而得到最优超参数的取
值组合。
分类及其性能度量
分类问题
- 分类问题是有监督学习的一个核心问题。分类解决的是要预测样本属于哪个或者哪些预定义的类别。此时输出变量通常取有限个离散值。
- 分类的机器学习的两大阶段:1)从训练数据中学习得到一个分类决策函数或分类模型,称为分类器(classifier);2)利用学习得到的分类器对新的输入样本进行类别预测。
- 两类分类问题与多类分类问题。多类分类问题也可以转化为两类分类问题解决,如采用一对其余(One-vs-Rest)的方法:将其中一个类标记为正类,然后将剩余的其它类都标记成负类
2. 分类性能度量
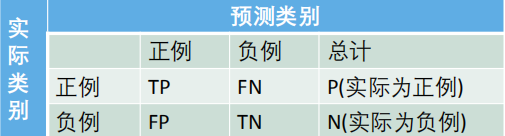
2.1 准确率(accuracy)
假设只有两类样本,即正例(positive)和负例(negative)。通常以关注的类为正类,其他类为负类。
表中AB模式:第二个符号表示预测的类别,第一个表示预测结果对了(True)还是错了(False)
分类准确率(accuracy):分类器正确分类的样本数与总样本数之比:
a
c
c
u
r
a
c
y
=
T
P
+
T
N
P
+
N
accuracy=\frac{TP+TN}{P+N}
accuracy=P+NTP+TN
2.2 精确率(precision)和召回率(recall)
精确率(precision)和召回率(recall):是二类分类问题常用的评价指标
p
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
precision=\frac{TP}{TP+FP}
precision=TP+FPTP
r
e
c
a
l
l
=
T
P
P
recall=\frac{TP}{P}
recall=PTP
- 精确率
反映了模型判定的正例中真正正例的比重。在垃圾短信分类器
中,是指预测出的垃圾短信中真正垃圾短信的比例。 - 召回率
反映了总正例中被模型正确判定正例的比重。医学领域也叫做灵敏度(sensitivity)。在垃圾短信分类器中,指所有真的垃圾短信被
分类器正确找出来的比例。
2.3 P‐R曲线 +AUC
Area (Area Under Curve, 或者简称AUC)
-
Area定义(p-r曲线下的面积)
-
Area有助于弥补P、R的单点值局限性,可以反映全局性能。
2.4 F值
- F值(
F
β
−
s
c
o
r
e
F_\beta-score
Fβ−score)是精确率和召回率的调和平均:
F β − s c o r e = ( 1 + β 2 ) ∗ p r e c i s i o n ∗ r e c a l l β 2 ∗ p r e c s i o n + r e c a l l F_\beta-score=\frac{(1+\beta^2)*precision*recall}{\beta^2*precsion+recall} Fβ−score=β2∗precsion+recall(1+β2)∗precision∗recall -
β
\beta
β一般大于0。当
β
=
1
\beta=1
β=1,退化为F1:
F β − s c o r e = 2 ∗ p r e c s i i o n ∗ r e c a l l p r e c i s i o n + r e c a l l F_\beta-score=\frac{2*precsiion*recall}{precision+recall} Fβ−score=precision+recall2∗precsiion∗recall - 比较常用的是F1 , 即表示二者同等重要
2.5 ROC
- 横轴: 假正例率 f p r a t e = F P N fprate=\frac{FP}{N} fprate=NFP
- 纵轴: 真正例率 t p r a t e = T P P tprate=\frac{TP}{P} tprate=PTP
- ROC(receiver operating characteristic curve)
描绘了分类器在𝑡𝑝𝑟𝑎𝑡𝑒(真正正例占总正例的比率,反映命中概率,纵轴)和𝑓𝑝𝑟𝑎𝑡𝑒 (错误的正例占反例的比率,反映误诊率、假阳性率、虚惊概率,横轴) 间的trade‐off
2.5 ROC-AUC计算
- ROC‐ AUC(Area Under Curve)定义为ROC曲线下的面积
- AUC值提供了分类器的一个整体数值。通常AUC越大,分类器更好
- 取值范围为[0,1]
回归问题及其性能评价
1.回归问题
- 回归分析(regression analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
- 和分类问题不同,回归通常输出为一个实数数值。而分类的输出通常为若干指定的类别标签。
2. 回归性能度量方法
常用的评价回归问题的方法:
-
平均绝对误差MAE(mean_absolute_error)
-
均方误差MSE (mean_squared_error)及均方根差RMSE
-
Log loss,或称交叉熵loss(cross‐entropy loss)
-
R方值,确定系数( r2_score)
2.1交叉熵损失(cross‐entropy loss)
常用于评价逻辑回归LR和神经网络
代码示例
# coding=utf-8
"""
#演示目的:利用鸢尾花数据集画出P-R曲线
"""
print(__doc__)
import matplotlib.pyplot as plt
import numpy as np
from sklearn import svm, datasets
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.preprocessing import label_binarize #二分类
from sklearn.multiclass import OneVsRestClassifier #一对多
# from sklearn.cross_validation import train_test_split #适用于anaconda 3.6及以前版本
from sklearn.model_selection import train_test_split # 适用于anaconda 3.7
# 以iris数据为例,画出P-R曲线
iris = datasets.load_iris()
X = iris.data #150x4 ,4个features
y = iris.target #150x1
# 标签二值化,将三个类转为001, 010, 100的格式.因为这是个多类分类问题,后面将要采用
# OneVsRestClassifier策略转为二类分类问题
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
print(y)
# 增加了800维的噪声特征
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]#c相当于column,样本个数不变,增加4x200=800例
# Split into training and test,0.5表示一半一半
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5, random_state=random_state) # 随机数,填0或不填,每次都会不一样
# Run classifier probability : boolean, optional (default=False)Whether to enable probability estimates. This must be enabled prior to calling fit, and will slow down that method.
classifier = OneVsRestClassifier(svm.SVC(kernel='linear', probability=True, random_state=random_state))
y_score = classifier.fit(X_train, y_train).decision_function(X_test)#fit(..)输入开始训练,之后,,decision就是把测试样本输入,得到预测值
# Compute Precision-Recall and plot curve
# 下面的下划线是返回的阈值。作为一个名称:此时“_”作为临时性的名称使用。
# 表示分配了一个特定的名称,但是并不会在后面再次用到该名称。
precision = dict()
recall = dict()
average_precision = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i], y_score[:,
i]) # The last precision and recall values are 1. and 0. respectively and do not have a corresponding threshold. This ensures that the graph starts on the x axis.
average_precision[i] = average_precision_score(y_test[:, i], y_score[:, i]) # 切片,第i个类的分类结果性能
# y_test[:, i]前面的:表示所有的第一维数据,i表示第二维的第i个
# Compute micro-average curve and area. ravel()将多维数组降为一维
precision["micro"], recall["micro"], _ = precision_recall_curve(y_test.ravel(), y_score.ravel())
average_precision["micro"] = average_precision_score(y_test, y_score,
average="micro") # This score corresponds to the area under the precision-recall curve.
# Plot Precision-Recall curve for each class
plt.clf() # clf 函数用于清除当前图像窗口
plt.plot(recall["micro"], precision["micro"],
label='micro-average Precision-recall curve (area = {0:0.2f})'.format(average_precision["micro"]))
for i in range(n_classes):
plt.plot(recall[i], precision[i],
label='Precision-recall curve of class {0} (area = {1:0.2f})'.format(i, average_precision[i]))
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05]) # xlim、ylim:分别设置X、Y轴的显示范围。
plt.xlabel('Recall', fontsize=16)
plt.ylabel('Precision', fontsize=16)
plt.title('Extension of Precision-Recall curve to multi-class', fontsize=16)
plt.legend(loc="lower right") # legend 是用于设置图例的函数
plt.show()















 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









