






本文已经发表在知乎,辛苦移步~《deepseek中的MLA与MoE技术解析》
最近详细的学习了一下deepseek中一些独特的技术,例如MLA和MoE,记录笔记如下。
MLA(Multiple Latent Attention)是对传统的多头注意力(MHA)的改进,主要解决了大模型推理过程中kv cache占用显存过多的问题,核心解决路径是降低缓存的kv cache的维度,例如以前要缓存的每个向量的维度是2048,改进后只缓存256,这样就减少为以前的1/8,然后在推理过程中再从256还原到2048,相当于用时间换了空间。对MHA的改进也有其它的方法,例如MQA,GQA,这两种方法有效果上打了折扣。综合来看,MLA在综合效果上最优。
MoE(混合专家)也是一种常用的技术,主要解决的问题是FFN模块参数量和计算量过大的问题。(FFN模块的参数量占整个大模型的60%以上)。核心的解决路径就是将一个整体的FFN拆分成多个expert(例如64个),在每个token的处理过程中,只激活部分expert(例如6个),这样相当于激活的参数量大大的减少了。deepseek在传统的MoE的基础之上,有一些创新,例如增加了共享expert(例如2个),也就是共享expert一直会被激活。在设计意图上各个专家能够专注于更细致的知识领域,提高了专家的专业化程度。而共享专家用于捕捉和整合常见的跨上下文知识。这样可以减少路由专家之间的知识冗余,每个路由专家可以更专注于独特的知识领域。
本来也想实际的看一下MTP (Multi-Token Prediction, 多 token 预测机制)的计算过程,但因为有MTP的deepseek模型都是几百个B以上的参数量,本地无法部署,所以就只能看一看理论了。
关于MLA,MoE,MTP可以参考:Deepseek-V2技术详解,【LLM技术报告】DeepSeek-V3技术报告(全文)。前两个技术点其实在Deepseek-V2中已经引入了,而MTP是在Deepseek-v3中引入。
另外(与本文无关),关于deepseek R1的训练过程,可参考此文(deepseek r1的技术报告):https://www.53ai.com/news/LargeLanguageModel/2025020569317.html,写得非常好。
环境部署:
deepseek官方代码并没有对环境有明确说明,我就自行选择了以下版本:
Python 3.10.18
torch 2.4.0
transformers 4.39.3
flash-attn 2.6.3
上面讲过,deepseek的模型都比较大,特别是V3和R1及以上的版本,本地无法部署。而MLA和MoE技术在V2版本中已经引入,正好V2版本有较小的模型,所以选择了DeepSeek-V2-Lite-Chat (16B参数量,已经最小了)进行部署。
GPU显存在推理时实际使用38G显存(bf16)。我本地的3090 24G显存也不够,所以就选择了auto-dl上一个48G的GPU进行部署测试。
代码就使用hugging face网站的示例代码即可,如下:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2-Lite"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
本文仅从工程的角度介绍实际计算过程中一些关键变量,理论部分请参考上面的参考文章。
MLA
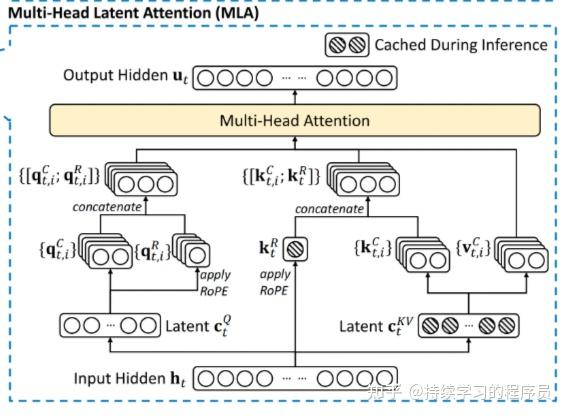
输入:
40是token的数量,hidden_states就是上面图片底部的Input Hidden
hidden_states.shape
torch.Size([1, 40, 2048])
query处理:
1,升维
将2048升到3072
q = self.q_proj(hidden_states)
2,reshape
q.shape
#3072 = 16(head num)*192(dim)
torch.Size([1, 16, 40, 192])

















 2185
2185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









