







一面+二面+三面+HR面,原神项目组,面完以为稳了,第二周被告知招满了,调剂到绝区零项目组一面完就挂了。
米哈游 一面
对游戏构建开发的了解
C++和JAVA的区别?为什么java可以到处运行
语言特性
- Java语言给开发人员提供了更为简洁的语法;完全面向对象,由于JVM可以安装到任何的操作系统上,所以说它的可移植性强
- Java语言中没有指针的概念,引入了真正的数组。不同于C++中利用指针实现的“伪数组”,Java引入了真正的数组,同时将容易造成麻烦的指针从语言中去掉,这将有利于防止在C++程序中常见的因为数组操作越界等指针操作而对系统数据进行非法读写带来的不安全问题
- C++也可以在其他系统运行,但是需要不同的编码(这一点不如Java,只编写一次代码,到处运行),例如对一个数字,在windows下是大端存储,在unix中则为小端存储。Java程序一般都是生成字节码,在JVM里面运行得到结果
- Java用接口(Interface)技术取代C++程序中的抽象类。接口与抽象类有同样的功能,但是省却了在实现和维护上的复杂性
垃圾回收
- C++用析构函数回收垃圾,写C和C++程序时一定要注意内存的申请和释放
- Java语言不使用指针,内存的分配和回收都是自动进行的,程序员无须考虑内存碎片的问题
应用场景
- Java在桌面程序上不如C++实用,C++可以直接编译成exe文件,指针是c++的优势,可以直接对内存的操作,但同时具有危险性 。(操作内存的确是一项非常危险的事情,一旦指针指向的位置发生错误,或者误删除了内存中某个地址单元存放的重要数据,后果是可想而知的)
- Java在Web 应用上具有C++ 无可比拟的优势,具有丰富多样的框架
- 对于底层程序的编程以及控制方面的编程,C++很灵活,因为有句柄的存在
到处运行是JVM的功劳,不同的平台装有不同的JVM
程序编译的过程?C++代码从编译到汇编中间的一个过程

预处理(Preprocess)
预处理,顾名思义就是编译前的一些准备工作。
预编译把一些#define的宏定义完成文本替换,然后将#include的文件里的内容复制到.cpp文件里,如果.h文件里还有.h文件,就递归展开。在预处理这一步,代码注释直接被忽略,不会进入到后续的处理中,所以注释在程序中不会执行。
预处理之后的程序格式为 *.i,仍是文本文件,可以用任意文本编辑器打开。
编译(Compile)
编译只是把我们写的代码转为汇编代码,它的工作是检查词法和语法规则,所以,如果程序没有词法或则语法错误,那么不管逻辑是怎样错误的,都不会报错。
编译不是指程序从源文件到二进制程序的全部过程,而是指将经过预处理之后的程序转换成特定汇编代码(assembly code)的过程。
编译完成后,会生成程序的汇编代码main.s,这也是文本文件,可以直接用任意文本编辑器查看。
汇编(Assemble)
汇编过程将上一步的汇编代码(main.s)转换成机器码(machine code),这一步产生的文件叫做目标文件(main.o),是二进制格式。
链接(Link)
C/C++代码经过汇编之后生成的目标文件(*.o)并不是最终的可执行二进制文件,而仍是一种中间文件(或称临时文件),目标文件仍然需要经过链接(Link)才能变成可执行文件。
既然目标文件和可执行文件的格式是一样的(都是二进制格式),为什么还要再链接一次呢?
因为编译只是将我们自己写的代码变成了二进制形式,它还需要和系统组件(比如标准库、动态链接库等)结合起来,这些组件都是程序运行所必须的。
链接(Link)其实就是一个“打包”的过程,它将所有二进制形式的目标文件(.o)和系统组件组合成一个可执行文件。完成链接的过程也需要一个特殊的软件,叫做链接器(Linker)。
此外需要注意的是:C++程序编译的时候其实只识别.cpp文件,每个cpp文件都会分别编译一次,生成一个.o文件。这个时候,链接器除了将目标文件和系统组件组合起来,还需要将编译器生成的多个.o或者.obj文件组合起来,生成最终的可执行文件(Executable file)。
inline的作用,template可以被定为inline吗,什么函数不能被定义为inline?
简介
在计算机科学中,内联函数(有时称作在线函数或编译时期展开函数)是一种编程语言结构,用来建议编译器对一些特殊函数进行内联扩展(有时称作在线扩展);也就是说建议编译器将指定的函数体插入并取代每一处调用该函数的地方(上下文),从而节省了每次调用函数带来的额外时间开支。但在选择使用内联函数时,必须在程序占用空间和程序执行效率之间进行权衡,因为过多的比较复杂的函数进行内联扩展将带来很大的存储资源开支。另外还需要特别注意的是对递归函数的内联扩展可能引起部分编译器的无穷编译。
设计内联函数的动机
内联扩展是一种特别的用于消除调用函数时所造成的固有的时间消耗方法。一般用于能够快速执行的函数,因为在这种情况下函数调用的时间消耗显得更为突出。这种方法对于很小的函数也有空间上的益处,并且它也使得一些其他的优化成为可能。
没有了内联函式,程式员难以控制哪些函数内联哪些不内联;由编译器自行决定是否内联。加上这种控制维度准许特定于应用的知识,诸如执行函式的频繁程度,被利用于选择哪些函数要内联。
此外,在一些语言中,内联函数与编译模型联系紧密:如在C++中,有必要在每个使用它的模块中定义一个内联函数;与之相对应的,普通函数必须定义在单个模块中。这使得模块编译独立于其他的模块
与宏的比较
通常,在C语言中,内联展开的功能由带参宏(Macros)在源码级实现。内联提供了几个更好的方法:
- 宏调用并不执行类型检查,甚至连正常参数也不检查,但是函数调用却要检查。
- C语言的宏使用的是文本替换,可能导致无法预料的后果,因为需要重新计算参数和操作顺序。
- 在宏中的编译错误很难发现,因为它们引用的是扩展的代码,而不是程序员键入的。
- 许多结构体使用宏或者使用不同的语法来表达很难理解。内联函数使用与普通函数相同的语言,可以随意的内联和不内联。
- 内联代码的调试信息通常比扩展的宏代码更有用
内联函数与一般函数的区别
1)内联含函数比一般函数在前面多一个inline修饰符
2)内联函数是直接复制“镶嵌”到主函数中去的,就是将内联函数的代码直接放在内联函数的位置上,这与一般函数不同,主函数在调用一般函数的时候,是指令跳转到被调用函数的入口地址,执行完被调用函数后,指令再跳转回主函数上继续执行后面的代码;而由于内联函数是将函数的代码直接放在了函数的位置上,所以没有指令跳转,指令按顺序执行
3)一般函数的代码段只有一份,放在内存中的某个位置上,当程序调用它是,指令就跳转过来;当下一次程序调用它是,指令又跳转过来;而内联函数是程序中调用几次内联函数,内联函数的代码就会复制几份放在对应的位置上
4)内联函数一般在头文件中定义,而一般函数在头文件中声明,在cpp中定义
哪些函数不能声明为内联函数
- 包含了递归、循环等结构的函数一般不会被内联。
- 虚拟函数一般不会内联,但是如果编译器能在编译时确定具体的调用函数,那么仍然会就地展开该函数。
- 如果通过函数指针调用内联函数,那么该函数将不会内联而是通过call进行调用。
- 构造和析构函数一般会生成大量代码,因此一般也不适合内联。
- 如果内联函数调用了其他函数也不会被内联。
什么时候不能使用内联函数
1)函数代码量多,功能复杂,体积庞大。对于这种函数,就算加上inline修饰符,系统也不一定会相应,可能还是会当成一般函数处理
2)递归函数不能使用内联函数
类与内联函数
1)类内定义的函数都是内联函数,不管是否有inline修饰符
2)函数声明在类内,但定义在类外的看是否有inline修饰符,如果有就是内联函数,否则不是。
原文链接:https://blog.csdn.net/ypshowm/article/details/89110896
经过测试模板函数应该也是能定义成inline函数的。
多重继承菱形继承的话,虚函数表的实现机制?
解决菱形继承的一个常用的办法就是改为虚继承,实际上虚继承中就是将从最基类中继承的公共部分提取出来放在最子类的末尾,然后在提取之前的位置用一个叫做vbptr的指针指向这里。
https://blog.csdn.net/albertsh/article/details/103757118
多线程同步的方式,选两种比较熟悉的方式具体讲讲
互斥锁、
条件变量和信号量的区别:
(1)最大的区别应该是使用条件变量可以一次唤醒所有等待者,但信号量不行。
(2)信号量有一个表示状态的值,而条件变量是没有的,没有地方记录唤醒(发送信号)过多少次,也没有地方记录唤醒线程(wait返回)过多少次。从实现上来说一个信号量可以是用mutex + counter + condition variable实现的。因为信号量有一个状态,如果想精准的同步,那么信号量可能会有特殊的地方。信号量可以解决条件变量中存在的唤醒丢失问题。
(3)在Posix.1基本原理一文声称,有了互斥锁和条件变量还提供信号量的原因是:“本标准提供信号量的主要目的是提供一种进程间同步的方式,这些进程可能共享也可能不共享内存区。互斥锁和条件变量是作为线程间的同步机制说明的,这些线程总是共享(某个)内存区。”尽管信号量的意图在于进程间同步,互斥锁和条件变量的意图在于线程间同步,但是信号量也可用于线程间,互斥锁和条件变量也可用于进程间。信号量最有用的场景是用以指明可用资源的数量。
原文链接:https://blog.csdn.net/xywams/article/details/123719528
死锁发生条件,怎么避免死锁?
死锁发生条件:
- 互斥条件
- 持有等待条件
- 不可剥夺条件
- 环路等待条件
怎么避免死锁:
顺序获取锁
https://zhuanlan.zhihu.com/p/61221667
扩展:死锁检测:
死锁检测算法:
每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
谈谈页表的作用,为什么要多级页表?有什么办法可以快点查表
虚拟内存,减少内存占用,TLB快表
对树的了解,有哪些?红黑树是什么样的?
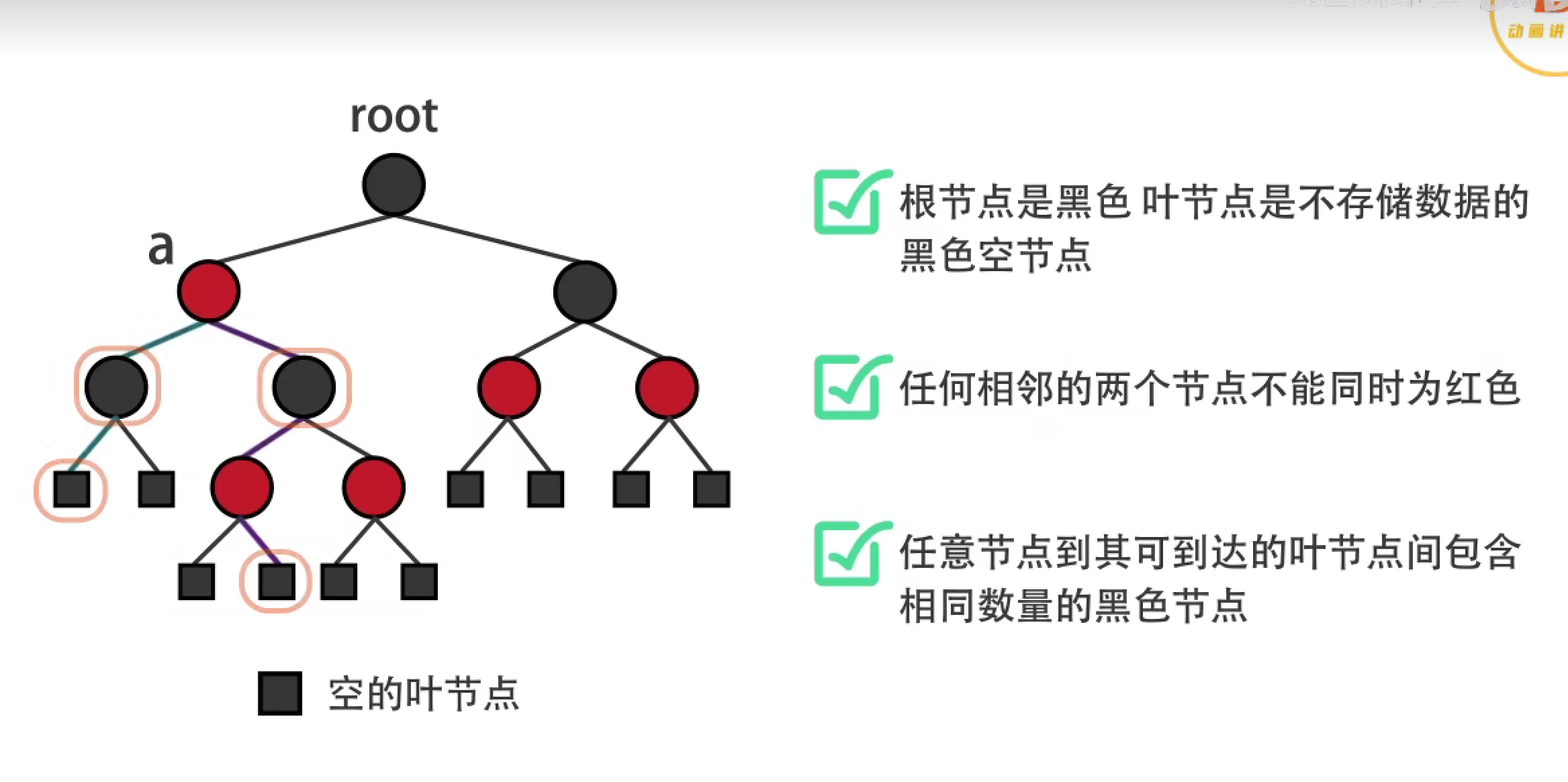
手撕,求二叉搜索树有多少种结构
米哈游 二面
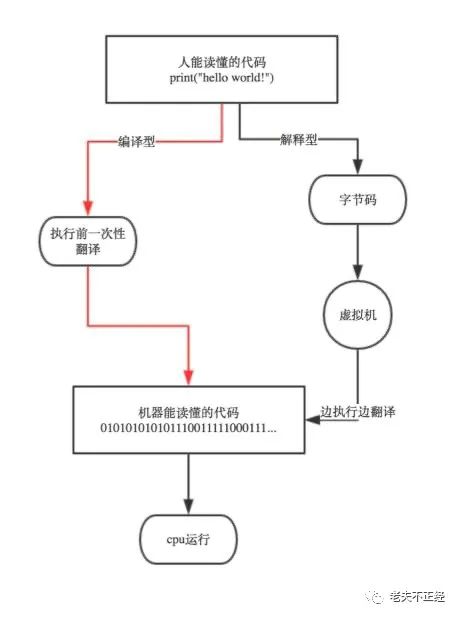
解释型语言和编译型语言的区别
众所周知,计算只能识别二进制,任何程序或软件,最终都要经过编译或解释转换成二进制才能被计算机识别。源代码,源代码就是由程序员使用各种编程语言编写的还未经编译或者解释的程序文本,编译或解释能把源代码翻译成等效的二进制代码,也就是CPU能够识别的机器语言。
编译和解释
编译和解释都是对源代码的解释处理方式,而由于他们的操作方法不同,所以会有不同的运行的效果:
- 编译是把源代码的每一条语句都编译成机器语言,并最终生成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,在运行时会有很好的性能;
- 解释器是只有在执行到对应的语句时才会将源代码一行一行的解释成机器语言,给计算机来执行,所以使用解释器来执行的语言也被称为动态语言;
举个现实中的例子,比如你现在想读一本英文书,但你自己又不懂英文,然后你去找了个英文翻译小姐姐来帮忙,翻译小姐姐给你提供了两种选择:
- 全本翻译:由翻译小姐姐帮你把整本书翻译完,完成校稿后给你一本翻译完成的中文书,在这个过程中翻译就会花费较长的时间,你阅读时就会很快、很轻松;
- 随身翻译:就是翻译小姐姐随时守在你身边,你想阅读那一句,他就给你翻译那一句,这这种方式翻译时很快,但对你来说,阅读就会花费较长的时间;
编译型语言与解释型语言
编译型语言:使用编译器来编译执行的编程语言,这类语言往往会花费较长的编译时间,但编译完成后,会有很好的运行性能;因此,这类语言编写的程序每次修改都要再次经历一遍完整编译过程后,修改效果才能生效,迭代时间会比解释型语言要长。
由于要经历完整编译过程,因此在程序有任何语法错误都能在编译期被发现,大大降低程序的运行错误。
代表语言:C、C++

解释型语言:使用解释器来解释执行的编程语言,这类语言不需要编译,程序执行到了,解释器才会去解释对应的语句,这类语言更多的时间花费在了运行期间;但是这类语言编写的程序的修改迭代不要经历漫长的编译过程,效果能够很快生效;
这类语言由于没有经历编译过程,所以即便是语法错误,也得等到运行期间才会被发现。
米哈游 三面
LRU的适用场景
LRU使用场景
- Memcached
Memcached 前面有文章已讲解过,思想与Multi Queue类似,详情看: Memcached内存管理模型与LRU算法优化
- MySQL
MySQL change buffer缓存,使用的是类LRU-k的算法,读取新数据页页,不是放于LRU列表首部,而是放于5/8处,因为索引或数据扫描需要访问很多页,非活跃热点数据,放于首部,可能会移除真正的热点数据
- Redis
Redis中的数据整体上是一个大的字典,Redis采用了基于采样的近似LRU算法,redis并没有去遍历所有对象,每个对象都记有最近访问时间戳。LRU算法也比较简单,Redis有一个全局的LRU时钟,每次随机取出5(maxmemory-samples默认参数)个redis对象,淘汰时间戳最小的。
原文链接:https://blog.csdn.net/Kindle_code/article/details/107805289
复活赛
多重区间存储
[a, b], [c, d]设计数据结构,有插入、删除两种操作
花的时间太长挂掉了。















 1279
1279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









