







一、数据处理
先获取数据集常见的数据集整理中的iris.txt。

150条数据,然后3个类别。
加载数据
df=pd.read_csv('Dataset/iris.txt',header=None,sep=' ').values
data=df[:,1:]
dic={}#将标签数字化隐射
id=0
for val in Counter(data[:,-1]).keys():
dic[val]=id
id+=1
X_data=data[:,0:4]
Y_data=[]
for val in data[:,-1]:
Y_data.append(dic[val])
Y_data=np.array(Y_data)
#特征归一化
min_max_scaler = MinMaxScaler()
min_max_scaler.fit(X_data)
X_data = min_max_scaler.transform(X_data)
# 对训练集进行切割,然后进行训练
train_x,test_x,train_y,test_y = train_test_split(X_data,Y_data,test_size=0.2)
lb=preprocessing.LabelBinarizer().fit(np.array(range(3)))#对标签进行one_hot编码
train_y=lb.transform(train_y)#因为是多分类任务,必须进行编码处理
输出归一化和one_hot编码后的标签
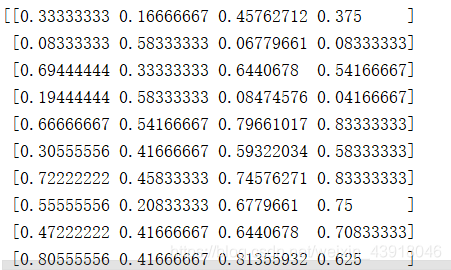
标签类型为

每行中位置x为1,说明标签为x,比如[0,1,0]表示标签1,[1,0,0]表示标签1,这和softmax映射函数进行神经网络训练时的结构有关。
二、搭建网络
#模型结构,采用relu函数为激活函数,输入层为N个属性
#下面为4层隐含层,每层的神经元个数依次为500,500,250,250
#输入层对应N个属性
model = keras.Sequential([
keras.layers.Dense(500,activation='relu',input_shape=[4]),#输入特征数目为4
keras.layers.Dense(500,activation='relu'),
keras.layers.Dense(250,activation='relu'),
keras.layers.Dense(250,activation='relu'),
keras.layers.Dense(3, activation='softmax')])#输出的类别为3个,所以输出层3个节点
#编译模型,定义损失函数loss,采用的优化器optimizer为Adam
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#开始训练模型
model.fit(train_x,train_y,batch_size = 32,epochs=20)#训练1000个批次,每个批次数据量为126
y_pre=model.predict(test_x).argmax(axis=1)#开始预测,axis=1表示返回每行中数值(表示每个类别的概率)最大的下标,就是对应的标签
print("验证集 accuracy_score: %.4lf" % accuracy_score(y_pre,test_y))
三、训练和预测结果
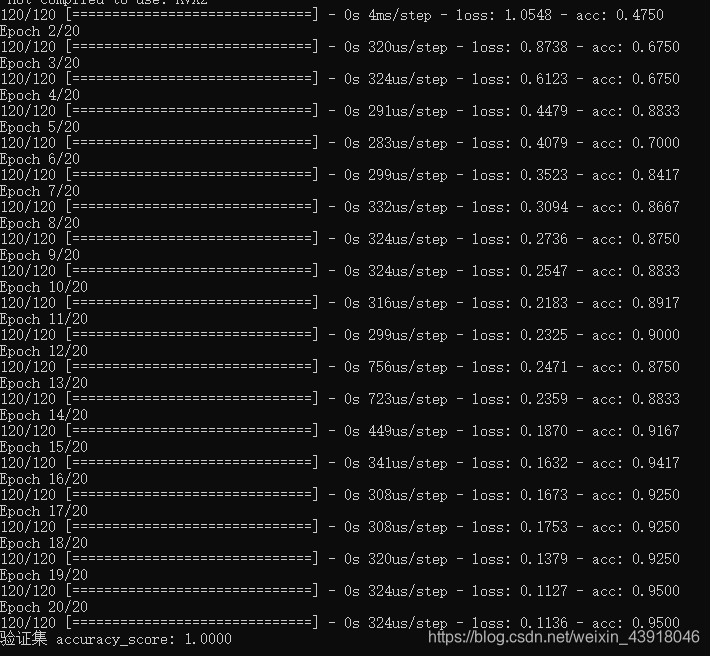
训练集准确率达到了95%,验证集达到了100%。看来神经网络还是比较强大的,可能数据集也比较简单,特征数目比较少。
希望我的分享对你的学习有所帮助,如果有问题请及时指出,谢谢~

















 5388
5388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









