






论文链接:https://arxiv.org/pdf/2306.04039
一、摘要
信息检索和推荐应用中,检索任务是从大规模的语料库中找到一小部分相关的候选项。检索的关键组成部分是建模(用户,物品)的相似度,通常表示为两个学习嵌入向量的点积。这种形式允许高效的推理,通常称为最大内积搜索(MIPS)。尽管点积在实践中非常流行,但它无法捕捉复杂的用户-物品交互,这些交互是多方面的且可能具有较高的级别。因此,我们研究了在加速器上的非点积检索设置,并提出了混合对数几率(MoL)方法,它将(用户,物品)的相似度建模为基本相似度函数的自适应组合。这种新的形式具有表达力,可以建模高级别的用户-物品交互,并进一步适用于长尾数据。当与分层检索策略(h-indexer)相结合时,我们能够将MoL扩展到具有1亿条语料库的单个GPU上,并且延迟与MIPS基准相当。在公开数据集上,我们的方法可以提高命中率(HR)高达77.3%。在Meta公司的大型推荐平台上进行的实验显示出较强的指标提升和减少的流行度偏差,验证了所提出方法的性能和改进的泛化能力。
二、这篇论文做了什么
这是一篇双塔模型DSSM搜索优化的工作,传统的DSSM通过点积运算实现高效的向量查询,但是忽略了用户-物品之间复杂的交互信息,因此提出了改进希望能够学习到用户-物品之间复杂的交互信息。传统的DSSM检索是直接从海量数据中通过高纬向量查询算法得到topK个最相似的结果,而这篇工作的做法是:
(1)先通过h-indexer算法从海量数据中检索得到1e5个最相似的结果。
(2)从1e5个结果中采用MoL算法进行用户-物品的复杂信息计算得到更精确更相似的topK个物品结果。
大体的做法就是这样,但是这篇工作还涉及到很多工程方面的优化,比如向量压缩,浮点数计算优化等,去提升计算查询的速度,同时减少计算资源消耗。
2.1 h-indexer检索

h-indexer的检索流程如上图所示,主要流程是:
(1)输入所有参数,data表示海量的物品向量集合,query表示用户的查询向量信息,k表示最终需要返回给用户的物品数目,\lambda表示超参数。
(2)随机打乱data的索引,并选择\lambda个索引存入randIndices中,并利用点积运算计算这\lambda个物品向量与用户查询向量的相似度分数存入到sampledSimilarities中。
(3)选择相似度分数最高的第k/|data| * \lambda个相似度分数赋值给t,作为一个阈值。
(4)再去海量物品向量集合中找点积相似度分数大于t的物品,作为查询结果。
进一步涉及到3个细节优化处理。
2.1.1 点积运算优化
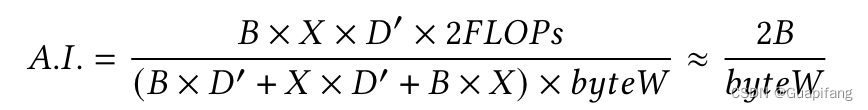
整理查询过程中GPU资源消耗如上述公式所示,可以直观看到,其计算强度可以粗略看成与批处理大小B成正比,与输入数据的字节宽度(byteW)成反比。因此提出利用INT8量化用户的请求,与半精度相比,由于INT8的存在,点积显示出1.5倍的速度提升。此外,INT8 GEMM的输出为INT32,可以直接通过顶部-k选择进行处理,而无需像常规做法中那样应用缩放/偏置进行反量化为FP32。
2.1.2 选择top-K个结果
在包含X个物品的集合中查找top-k’的时间复杂度为Ω(X log k’),这个复杂度由于较大的k’值而变得更加严重。因此,论文提出了一种近似的top-k方法,随机采样物品集合的一小部分来估计top k’项的阈值t,然后找到满足该阈值t的最多k’个样本。这将时间复杂度降低为Ω(X + rX log k’),其中采样比例r的取值范围为0.01到0.1。在实际生产环境中,这种改变比精确的top-k方法快约2.5倍,并且减少了h-indexer的延迟30%。值得一提的是,我们常用的用于查询高维向量top-k的算法为FAISS和TPUKNN,这两种算法可以非常高效快速的返回top-k个结果,但是由于其算法本身的设计逻辑问题,其k不能取很大,一般都是2048以内,而本文提出的算法是希望该步骤能查询返回1e5的结果,因此FAISS和TPUKNN算法不太适用。
2.1.3 索引选择
在算法2中,进一步优化了top-K选择后的索引选择操作。从一个包含1000万个项的池中提取和连接10万个项的嵌入向量是一项昂贵的操作,吞吐量约为0.15 TB/s。为此,本文设计了一个优化的GPU内核,通过利用数据局部性和高效的缓存机制,实现了2倍的吞吐量提升。
2.2 MoL检索
利用h-indexer算法得到1e5个结果后,现在进一步从1e5个结果中找出更符合我们需要的top-k个结果,因此引出了本文设计的MoL检索算法。算法流程如下图所示。
















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









