




目录
一:深度可分离卷积
深度可分离卷积被提出于MobileNet中,其主要作用用于减少模型参数和运算量。
深度可分离卷积主要由两部分构成:DW卷积和PW卷积
网络中的亮点在于(1)DW卷积(大大的减少了运算量和参数数量)
(2)增加了参数α和β
传统卷积和DW卷积的对比图如下所示:
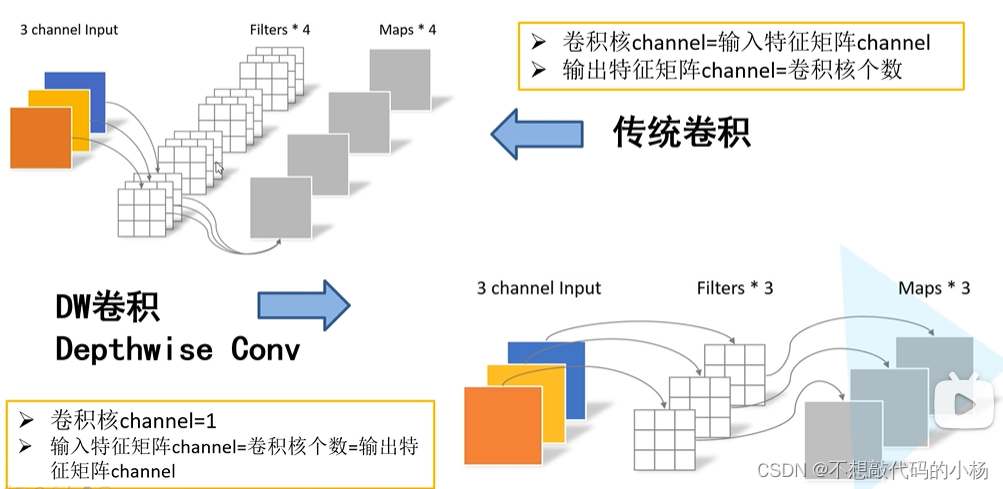
在DW卷积中每个卷积核的深度都是为1的,每个卷积核只负责与输入特征矩阵的一个channel进行卷积运算,然后再得到相应的输出矩阵的一个channel
深度可分离卷积完整示意图
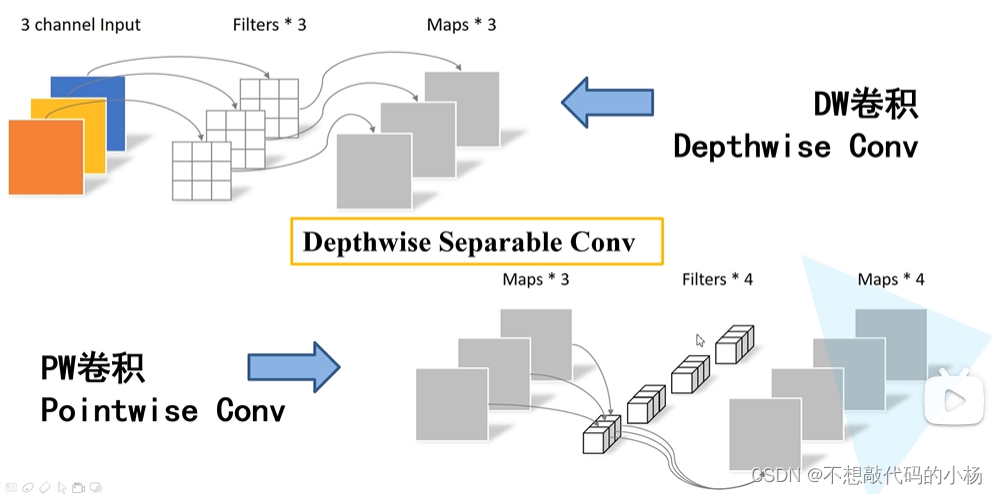
图中的PW卷积其实和普通的卷积区别不大,只是将卷积核大小变为1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9346
9346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









