







一、XML解码
对于XML的解码,在php中使用simpleXML可能会比较简单:
$content = simplexml_load_string($content,'SimpleXMLElement', LIBXML_NOCDATA);
$json = json_encode($content);
//'SimpleXMLElement', LIBXML_NOCDATA:如果不加这两个参数,将导致CDATA节点无法解析
//参数LIBXML_NOCDATA:将CDATA节点视为文本节点
但是在编码XML文档时,simpleXML的addChild()函数无法添加CDATA节点。
二、XML结构和XML DOM编码
了解XML文本结构
XML文本以节点形式组成,与json类似,HTML、XHTML也是使用XML规则编码的。
主要有以下几种类型:
1.文档的全部内容被视为一个总节点:

2.第一个标签被视为一级节点,或者根节点:

注意:根节点并不一定命名为xml,可以自定义;但标准规范建议用xml命名。
标准规范的XML文档只有一个根节点,否则无法被解析器识别。
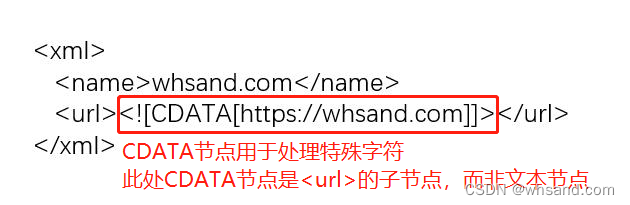
3.子节点:包含在其他标签内部的标签,图示的name和url就是xml节点的子节点。

注意:同处一级的节点,名称不可相同。
4.文本节点:标签内部的文本,包括下级节点内部的文本。

上面name的文本节点,同样属于xml的文本节点。

注意:文本节点的内容可以是换行符、空格或特殊符号等不显示的文本,但不会是空值。
如果为空值,则认为这个节点不存在。标准规范不建议在这些节点写入文本。
4.CDATA节点
当文本节点中包含一些特殊字符,如< &等将导致解析器产生识别错误。
因此在编码时,对于无法保证不包含特殊字符的文本节点,应使用CDATA节点来代替;
同时在解码时,将CDATA节点视为文本节点,就解决了这个问题。
CDATA节点的结构: <![CDATA[ 文本内容 ]]>
5其他属性
命名空间,节点属性等使用较少,后面再填坑吧。
XML DOM
XML DOM是通用的操作XML文档的标准方法,不仅限于php,在js、java等其它语言中同样可用,并且其属性方法基本一致。
在php中:
$xml = new DOMDocument();//实例化DOM类
$xml->loadXML("");//从字符串导入XML文本
$xml->load("file.xml");//从文件导入XML文本
$xml = new \DOMDocument();
//如果在thinkphp、laravel等框架中使用,需要在类名前加反斜杠\,或者将其注册到核心类文件中
XML DOM对象的方法:(用get_class_methods()函数查询)
XML DOM对象的属性:(用var_dump()函数查询)*内容过多,为了不影响阅读就不贴在这里了
解码XML
实例化并导入xml文本之后,此时的$xml是一个总节点,需要使用一系列方法属性来解析:
| 对象属性方法 | 说明 |
|---|---|
| $xml->documentElement | 返回文档的根节点对象DOMElement |
| DOMElement->childNodes | 返回子节点对象的集合DOMNodeList,php没有集合类型,可视为数组 |
| DOMElement->parentNode | 返回父节点对象DOMElement |
| DOMNodeList->item( index ) | 返回节点列表对应索引的节点对象DOMElement |
| DOMElement->nodeName | 返回节点对象DOMElement的名称,文本节点会返回#text |
| DOMElement->nodeValue | 返回节点对象DOMElement的文本节点内容,CDATA节点会被视为文本节点 |
| DOMElement->nodeType | 返回节点对象DOMElement的节点类型 |
| $xml->saveXML() | 返回字符串形式的XML文档 |
DOMNodeList->item( index )函数解释:

正常情况下,item(0)、item(2)、item(4)这些地方不会写入内容,因此在解析时也会被忽略。
如果删除换行符,写成一行的形式,则上图的item(0)、item(2)、item(4)不存在,剩下的item重新排列索引。

php没有列表或集合类型,DOMNodeList可以被视为数组。
DOMNodeList[ index ]、DOMNodeList->item( index ) 返回结果一致。
通过一个循环就可以遍历解析出XML:
(仅适用于单层XML,即根节点内只有一层子节点标签。)
//仅适用于单层XML,即根节点内只有一层子节点标签。
//如果子节点标签内还有子节点标签,这种方式无法导出内层子节点的标签名,需要进一步做递归遍历
$xml = new DOMDocument();
$xml->loadXML("");
$array=[];
foreach ($xml->documentElement->childNodes AS $item){
if($item->nodeName != "#text"){//#text节点忽略
$node = [$item->nodeName=>$item->nodeValue];
$array=array_merge_recursive($array , $node);
}
}
return $array;//后续可转换为json
返回结果:
array:2 [
"name" => "whsand.com"
"url" => "https://whsand.com"
]
多层XML的递归遍历解析:
(尚有不足,未考虑节点属性、命名空间等,仅适用于标准规范的XML文本)
function xml_handle($xmlstr){
$xml = new DOMDocument();
$xml->loadXML($xmlstr);
$GLOBALS['node'] = [];
function get_last_node($xml){//获取最底层的非#text节点
foreach($xml->childNodes as $item){
if($item->nodeType == 1)
get_last_node($item);
else{
$item = $item->parentNode;
if(!$item->childNodes[1])
$GLOBALS['node']=array_merge($GLOBALS['node'],[$item->nodeName=>$item->nodeValue]);
}
}
}
get_last_node($xml);
$xmlArray=[];
foreach($GLOBALS['node'] as $k=>$v){//循环递归获取父节点,直到根节点
$array = [$k=>$v];
$item=$xml->getElementsByTagName($k)[0];
while($item->parentNode->nodeName != "#document"){
$array = [$item->parentNode->nodeName => $array];
$item = $item->parentNode;
}
$xmlArray=array_merge_recursive($xmlArray,$array);//拼接数组
}
return $xmlArray;
}
暂时肝不动了,未完待续















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









