







 本文深入解析主成分分析(PCA),涵盖数据变换、降维、特征提取及人脸识别应用,通过实例展示PCA在高维数据可视化、图像特征提取和提高分类器精度上的作用。
本文深入解析主成分分析(PCA),涵盖数据变换、降维、特征提取及人脸识别应用,通过实例展示PCA在高维数据可视化、图像特征提取和提高分类器精度上的作用。
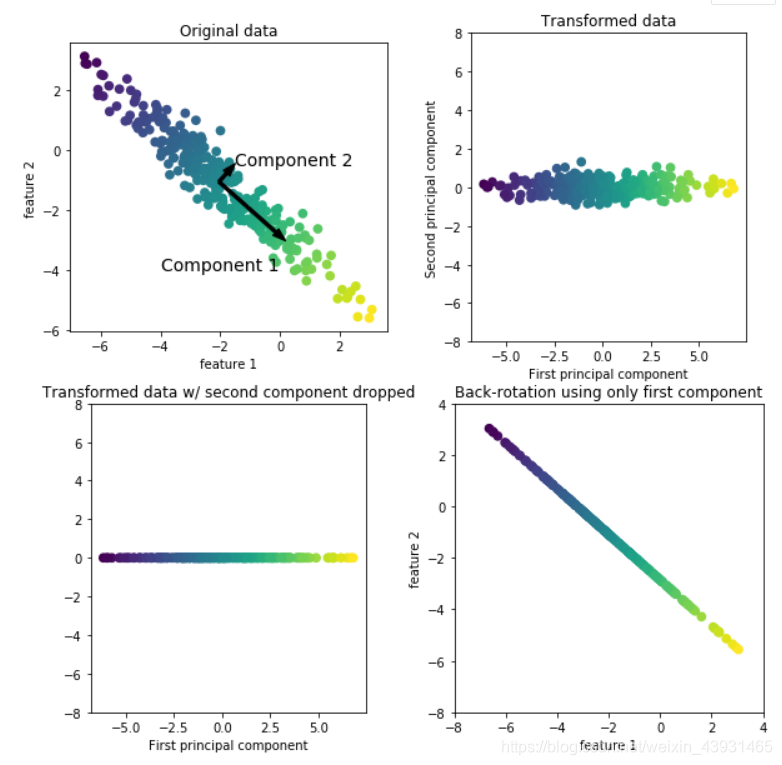
主成分分析(PCA)是一种旋转数据集的方法,旋转后的特征在统计上不相关。
用PCA做数据变换
- 首先,算法在原始数据点集中,找到方差最大的方向(包含最多信息),标记为‘成分1’。->找到与“成分1”正交(成直角)且包含最多信息的方向,标记为“成分2”。利用这一过程找到的方向被称为主成分(重建的最佳方向),一般主成分个数和原始特征数相同。
- 从数据中减去平均值,是的变换后的数据以0为中心->旋转数据:使第一主成分与x轴平行,第二主成分与y轴平行。两坐标轴是不相关的,除了对角线,相关矩阵全为0。
- 仅保留一部分主成分(第一主成分)进行PCA降维。二维数据集->一维数据集。(这个方向不是原始特征之一)
- 反向旋转并将平均值重新加到数据中。
这种变换可以用于去除数据中的噪声影响,或者将主成分中保留的那部分信息可视化。
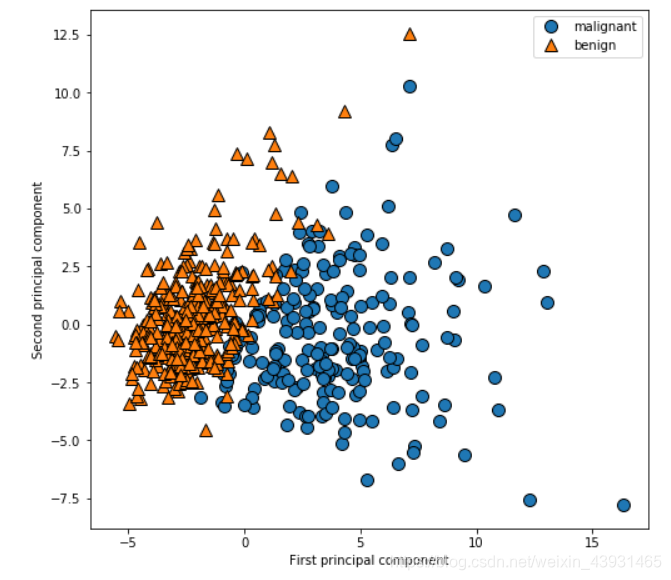
将PCA应用于高维数据可视化(cancer数据集)
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
# 预处理:缩放数据是每个特征方差均为1
cancer = load_breast_cancer()
scaler = StandardScaler()
scaler.fit(cancer.data)
x_scaled = scaler.transform(cancer.data)
# 保留数据的前两个主成分,对数据集拟合PCA模型
pca = PCA(n_components=2) # 实例化对象并指定想要保留的主成分个数,默认情况下所有主成分都保留
pca.fit(x_scaled) # 找到主成分
# 变换数据集方向
x_pca = pca.transform(x_scaled) # 旋转并降维
print(x_scaled.shape) # 原始数据形状:(569, 30)
print(x_pca.shape) # 变换后的数据形状:(569, 2)
# 对第一主成分和第二主成分作图,按类别着色
plt.figure(figsize=(8, 8))
mglearn.discrete_scatter(x_pca[:, 0], x_pca[:, 1], cancer.target)
plt.legend(cancer.target_names, loc="best")
plt.gca().set_aspect("equal") # 获取当前子图,并设置x,y轴坐标刻度相等
plt.xlabel("First principal component")
plt.ylabel("Second principal component")
使用plt.gcf()和plt.gca()方法获得当前的图表和子图。
ax.set_aspect(“equal”)方法设定坐标轴间距、长度相等。
python matplotlib.pyplot画矩形图 以及plt.gca()
3.plt.gca().set_aspect(“equal”)
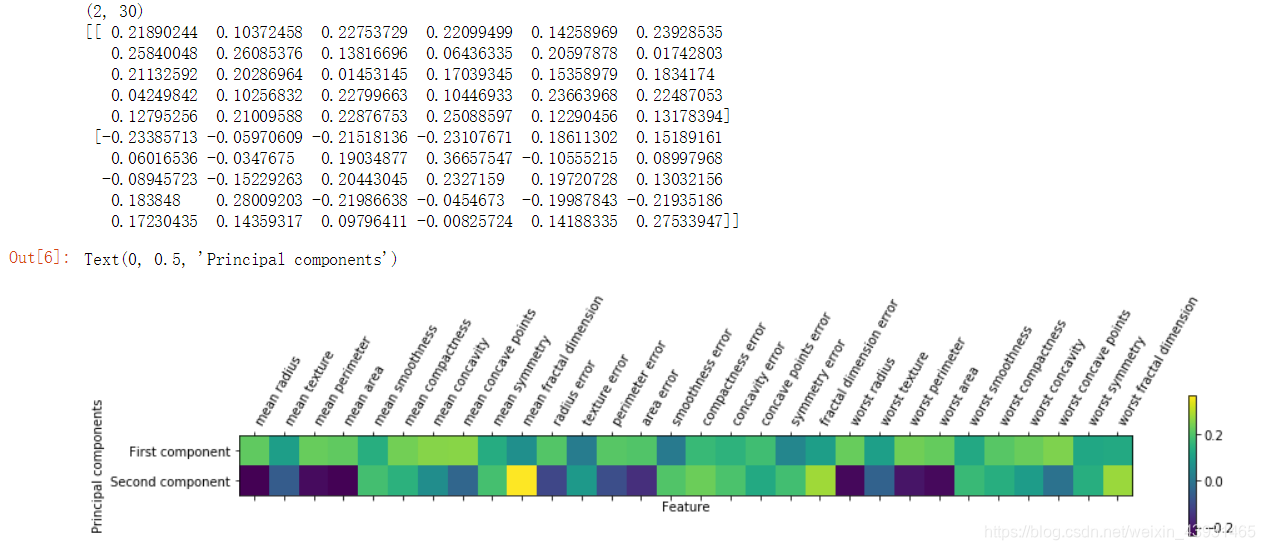
PCA是一种无监督方法,缺点是,通常不容易对两个轴做出解释。主成分对应原始数据中的方向,所以它们是原始特征的组合。在拟合过程中,主成分被保存在PCA对象的components_属性中,每一行对应一个主成分,列对应PCA的原始属性。
PCA对象系数可视化(热图)
# cancer数据集有30个属性
print(pca.components_.shape)
print(pca.components_)
# 用热图将系数可视化
plt.matshow(pca.components_, cmap='viridis')
plt.yticks([0, 1], ['First component', 'Second component'])
plt.colorbar()
plt.xticks(range(len(cancer.feature_names)), cancer.feature_names, rotation=60, ha='left')
plt.xlabel("Feature")
plt.ylabel("Principal components")
将PCA应用于特征提取(Wild数据集)
特征提取:可以找到一种数据表示,比给定的原始数据更适合于分析。
像素值:图片的尺寸大小。
灰度值:指的是单个像素点的亮度。灰度值越大表示越亮。范围一般从0到255,白色为255 ,黑色为0。
Wild数据集中的人脸图像
这个数据集有3023张图片,每张87*65像素,分别属于62个人,每个人照片数量不等。
from sklearn.datasets import fetch_lfw_people
import matplotlib.pyplot as plt
import numpy as np
people = fetch_lfw_people(min_faces_per_person=20, resize=0.7)
image_shape = people.images[0].shape
fix, axes = plt.subplots(2, 5, figsize=(15, 8), subplot_kw={'xticks':(), 'yticks':()})
for target, image, ax in zip(people.target, people.images, axes.ravel()):
ax.imshow(image)
ax.set_title(people.target_names[target])
print(people.images.shape) # (3023, 87, 65)
print(len(people.target_names)) # 62
# 计算每个目标出现的次数
counts = np.bincount(people.target)
for i,(count, name) in enumerate(zip(counts, people.target_names)):
print("{0:25}{1:3}".format(name, count), end=' ')
if (i + 1) % 3 == 0:
print()
min_faces_per_person参数:默认无,提取的数据集将仅保留具有条件的人的图片,每个人至少min_faces_per_person不同的图片。
resize参数:默认值0.5,比率,用于调整每张脸部图片的大小。
subplot_kw参数:字典类型,可选参数。把字典的关键字传递给add_subplot()来创建每个子图。

处理数据:降低数据偏斜
防止图片数量过多的数据影响特征提取,对每个人最多只取50张图片,并对图片灰度值进行缩放。
mask = np.zeros(people.target.shape, dtype=np.bool)
for target in np.unique(people.target):
mask[np.where(people.target == target)[0][:50]] = 1
x_people = people.data[mask]
y_people = people.target[mask]
# 缩放灰度值至0-1,保证数据稳定性
x_people= x_people / 255
np.zeros函数:返回来一个给定形状和类型的用0填充的数组。zeros(shape, dtype=float, order=‘C’)。shape:形状;dtype参数:数据类型,可选参数,默认numpy.float64;order参数:可选参数,c代表与c语言类似,行优先;F代表列优先。
np.where(condition)函数:输出满足条件 (即非0) 元素的坐标 (等价于numpy.nonzero)。坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
人脸识别:单一近邻分类
预测某个人脸是否属于数据库中的某个已知人物。
- 构建一个分类器,每个人是一个类别,但是类别的训练数据不足(同一个人图像不足),难添加新人物。- 使用单一近邻分类器(寻找与要分类的人脸最为相同的一个)
# 数据集分成训练集和测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_people, y_people, random_state=0)
# 构建模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(x_train, y_train)
print(knn.score(x_test, y_test)) # 0.28294573643410853
精度较低,因为计算原始像素空间中的距离时,如果使用像素距离,将人脸右移一个像素将会发生巨大变化,得到一个完全不同的表示。
用像素比较两张图片是,比较的是每个像素灰度值与另一张图像对应位置的像素灰度值。
于是进行处理,沿着主成分方向的距离可以提高精度↓
使用PCA进行数据变换之后的人脸识别
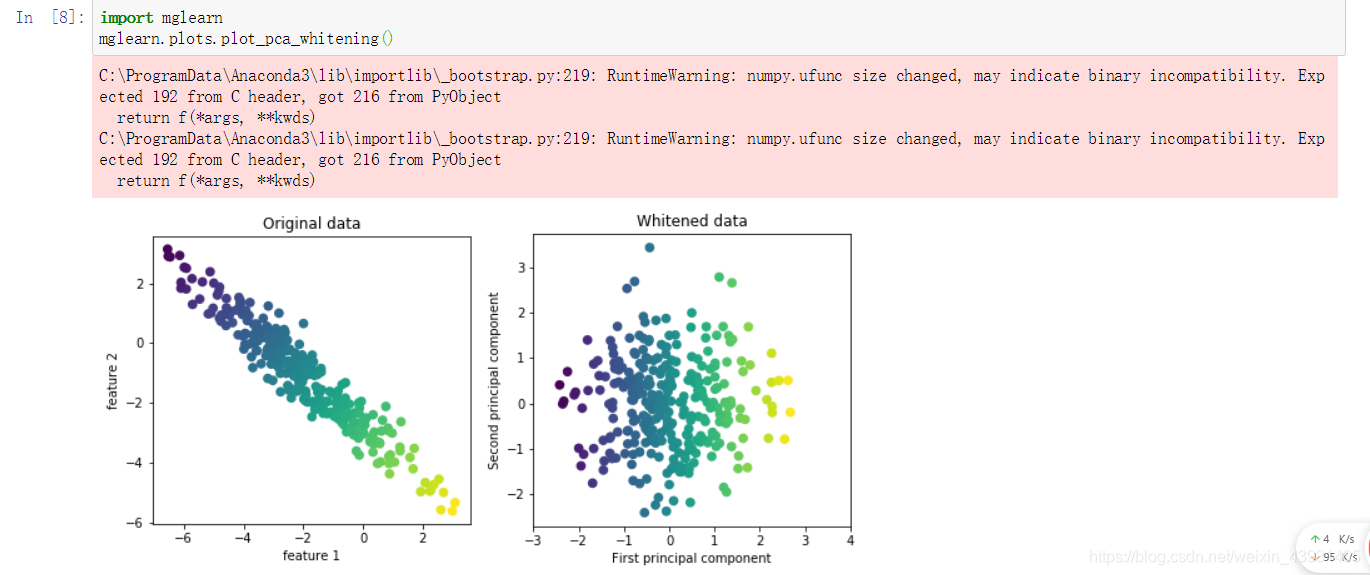
启用PCA的白化选项(旋转缩放数据),将主成分缩放到相同的尺度。变换后与使用StandardScaler(每个特征的平均值为0,方差为1)相同。
# 缩放数据,并提取钱100个主成分
from sklearn.decomposition import PCA
pca = PCA(n_components=100, whiten=True, random_state=0).fit(x_train)
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
print(x_train_pca.shape) # (1547, 100)
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(x_train_pca, y_train)
print(knn.score(x_test_pca, y_test)) # 0.32751937984496127
误差分析
PCA模型是基于像素的,因此人脸的相对位置(眼睛、下巴、鼻子的位置)和明暗程度都对两张图像在像素表示中的相似程度有很大影响。而认为辨别人脸相似度,可能会使用年龄、发型和面部表情等属性,这些很难从像素强度中推出来。

















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









