






AutoDL界面
① autodl-tmp文件夹:数据盘,一般用来存放大的文件。
② 其他文件夹“autodl-pub” “miniconda3” “tf-logs”等等存放在系统盘,其中tf-logs是用于存放训练过程tensorboard的记录日志。
迁移数据
① 在保存镜像时,镜像将完整保存系统盘的所有文件,数据盘等不会被保存在其中。
② 跨实例拷贝数据,仅支持拷贝数据盘下的文件(夹)至同地区其它实例,目标实例必须处于开机状态。"跨实例拷贝数据"和“克隆实例”都仅支持同地区间迁移数据。
③ 如果当前使用的实例显卡都被占用了,可以在同地区选择空闲的服务器,然后“跨实例拷贝数据”,比起“克隆实例”要快很多,但是“克隆实例”会把系统盘也克隆过去。
④ 跨地区迁移实例数据盘,参考AutoDL帮助文档
Llama2-chat-13B-Chinese-50W部署测试
项目参考教程:Llama2—文字版部署教程 - 飞书云文档 (feishu.cn)
硬件和环境选择

关键问题
问题一:在安装gradio时特别地慢,装了很多重复组件。
问题二:在有卡模式开机,运行大模型时,命令“python gradio_demo.py --base_model /root/autodl-tmp/Llama2-chat-13B-Chinese-50W --tokenizer_path /root/autodl-tmp/Llama2-chat-13B-Chinese-50W --gpus 0”报错:
Vocab of the base model: 49954
Vocab of the tokenizer: 49954
Traceback (most recent call last):
File "gradio_demo.py", line 298, in <module>
user_input = gr.Textbox(
AttributeError: 'Textbox' object has no attribute 'style'解决办法:打开Llama2/gradio_demo.py文件,删除第301、302行“.style(container=False)”. 删除之后点击Ctrl+S保存。
问题三:还是在运行大模型这一步,报错:
Could not create share link. Please check your internet connection or our status page: https://status.gradio.app这个错误是因为gradio无法生成可分享的外部连接,解决方法:cd进入frpc_linux_amd64文件的位置(这里是在miniconda3/lib/python3.8/site-packages/gradio),输入以下命令给予权限:
chmod +x frpc_linux_amd64_v0.2注意这里不要开启Autodl的学科加速,要开启自己的VPN才能生成外部分享链接。
最终效果
Llama2 8Bit试运行效果:
python gradio_demo.py --base_model /root/autodl-tmp/Llama2-chat-13B-Chinese-50W --tokenizer_path /root/autodl-tmp/Llama2-chat-13B-Chinese-50W --load_in_8bit --gpus 0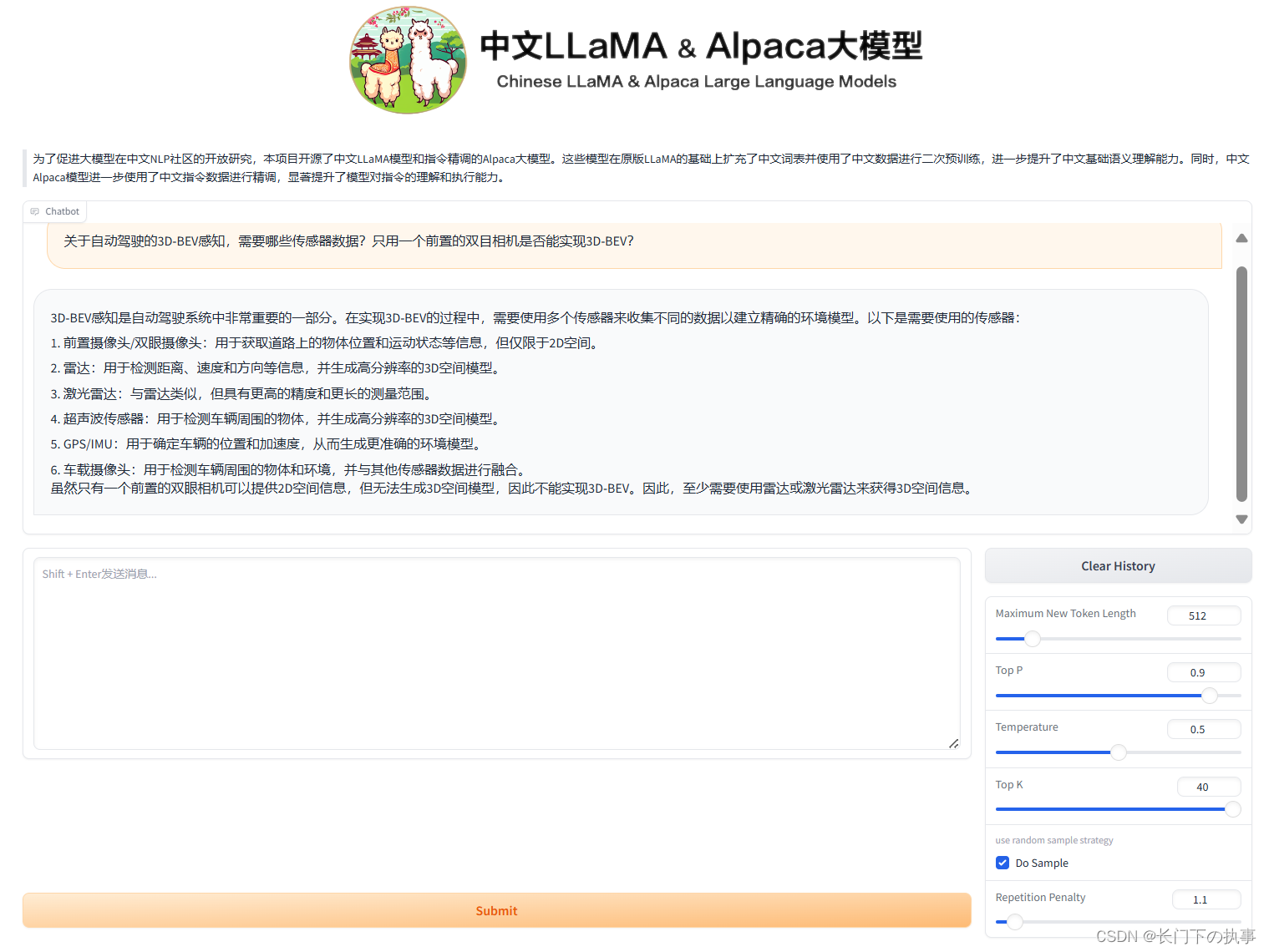
Llama2 原始模型运行效果:
python gradio_demo.py --base_model /root/autodl-tmp/Llama2-chat-13B-Chinese-50W --tokenizer_path /root/autodl-tmp/Llama2-chat-13B-Chinese-50W --gpus 0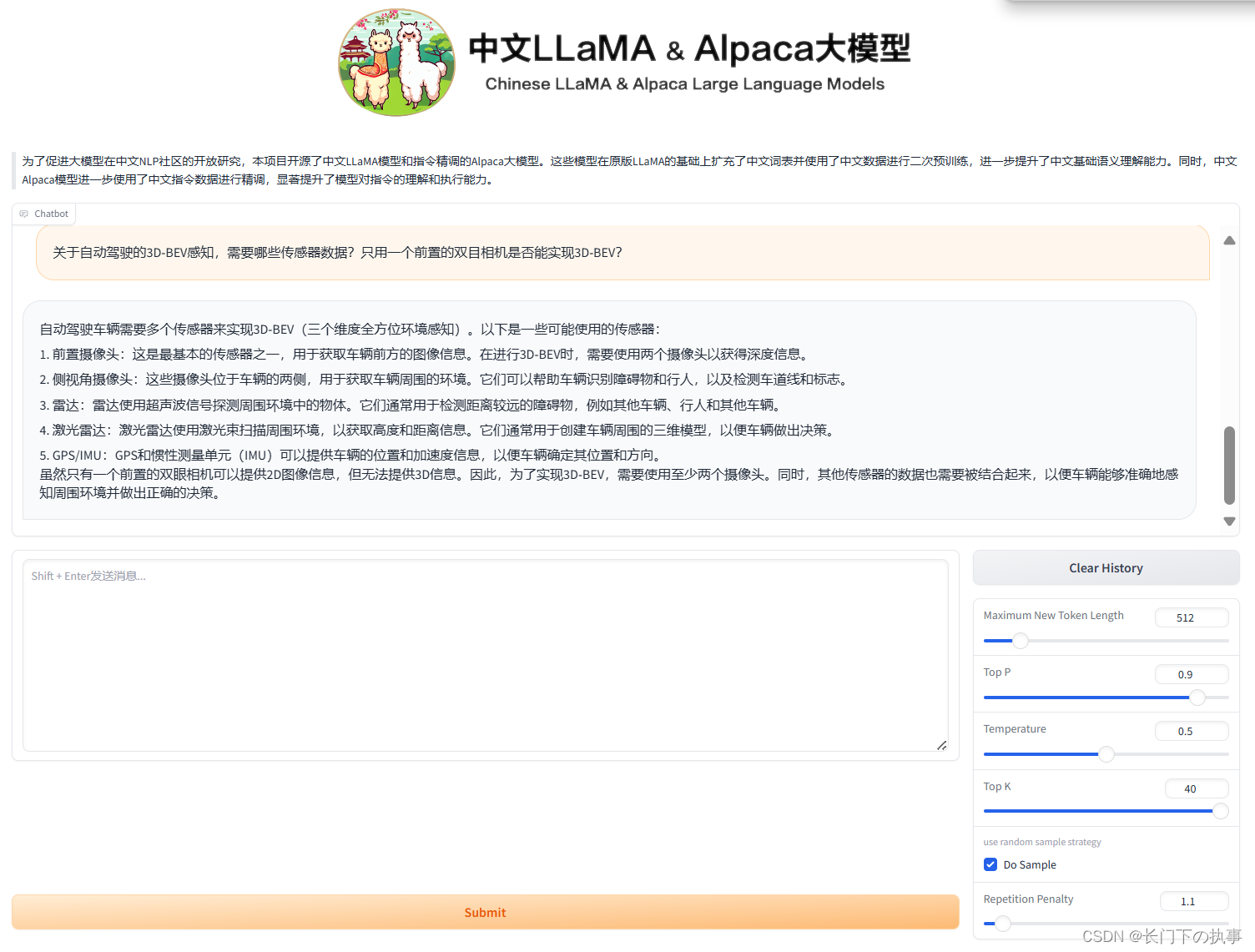
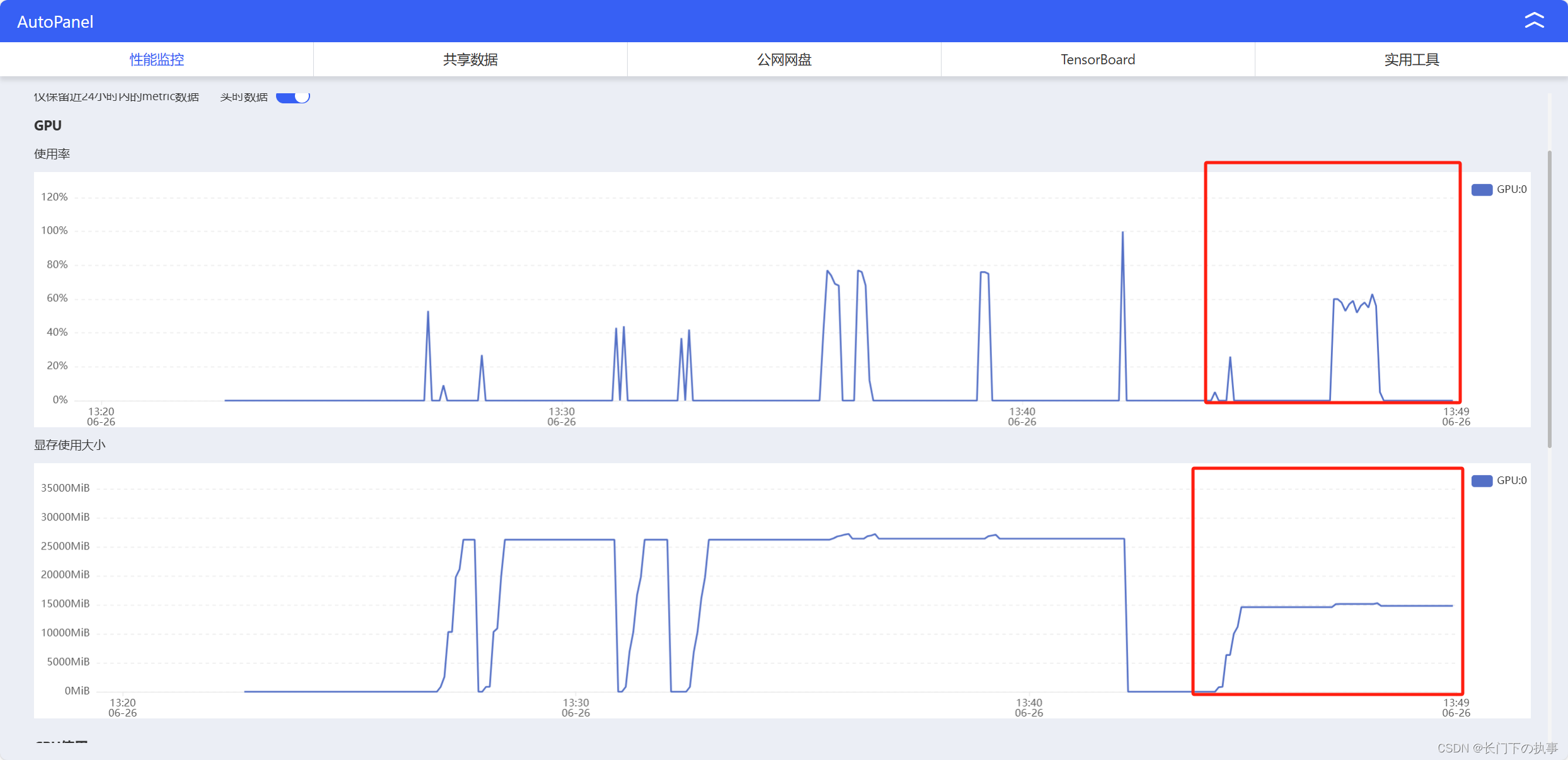
实例监控:
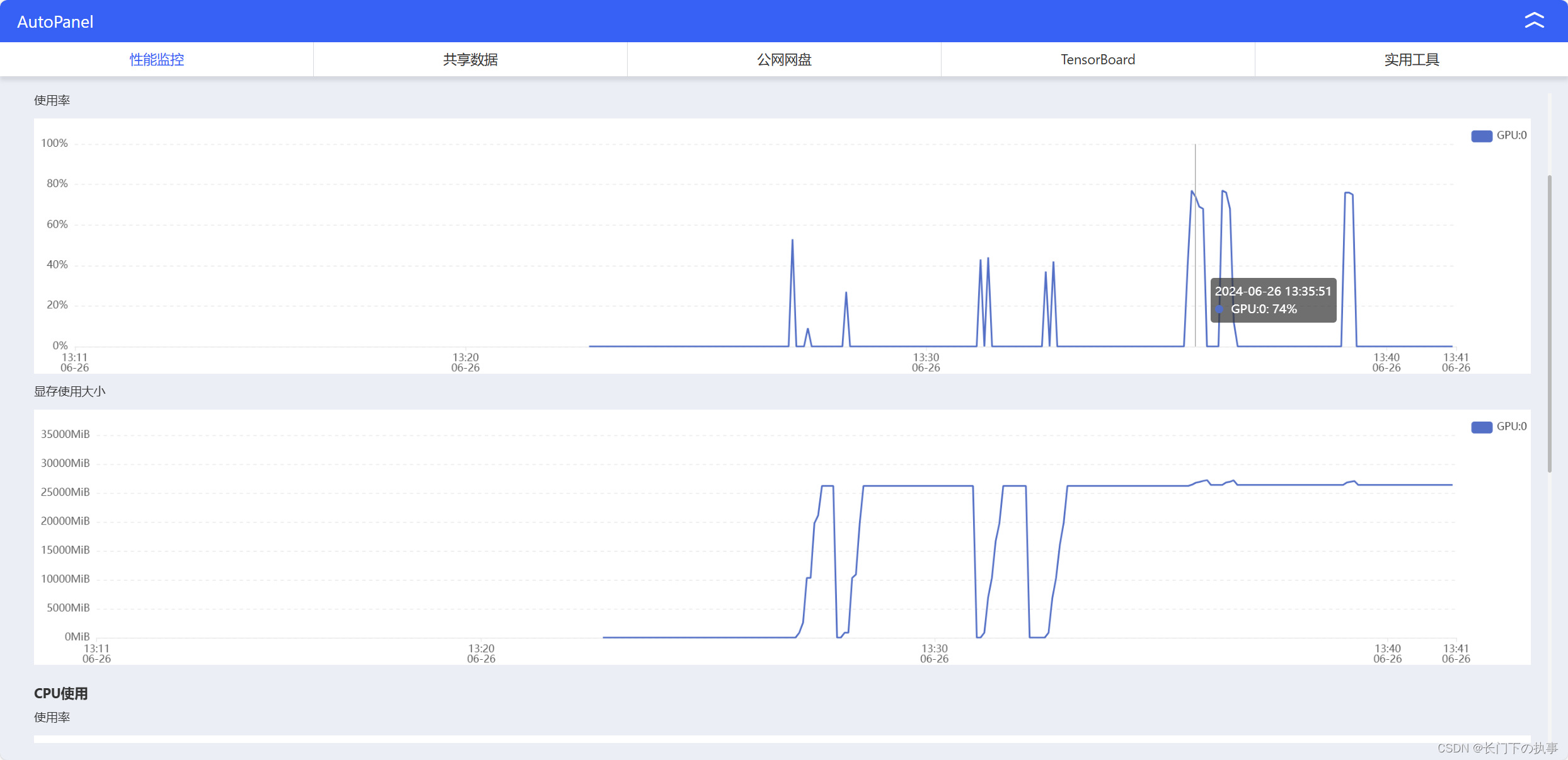
过程分析与总结
部署过程还是比较顺利的,就是安装gradio的时候出了点问题安装特别慢。使用“8bit”运行时GPU只占用了50%左右,生成文字反倒比较慢,可能是这块环境更多的是在原始模型上进行的优化,原始模型运行是比较流畅的。
Llama2-chat-13B-Chinese-50W微调训练
项目参考教程:Llama2—文字版微调教程(针对autodl平台) - 飞书云文档 (feishu.cn)
硬件和环境选择
原本使用的是上面的 V100-32G*1 的服务器,但是按教程中运行在微调时出现显存溢出的情况,不得已改成用 A100-40G*1服务器。

关键问题
问题一:在教程中使用access token在jupyter中登录Hugging Face用以后面导入模型,但实际操作时无论使用Autodl的学科加速还是挂VPN都登录不进去。
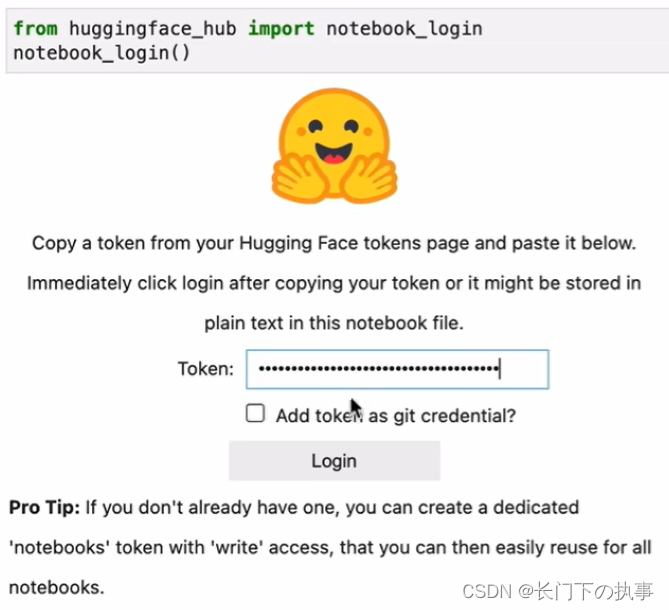
解决办法:不使用登录Hugging Face的方式,而是在导入相关的包时,使用它的镜像网站。pycharm通过hf mirror镜像访问huggingface模型(无需翻墙)_import os os.environ() hf-mirror-CSDN博客
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from datasets import load_dataset
import torch,einops
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer, TrainingArguments
from peft import LoraConfig
from trl import SFTTrainer问题三:按教程中的步骤微调模型显卡爆显存,即使换成A100显卡也爆显存。
解决办法:没有很好的办法,把batch_size调成2。
问题四:在保存合并模型的时候,数据盘空间不足。
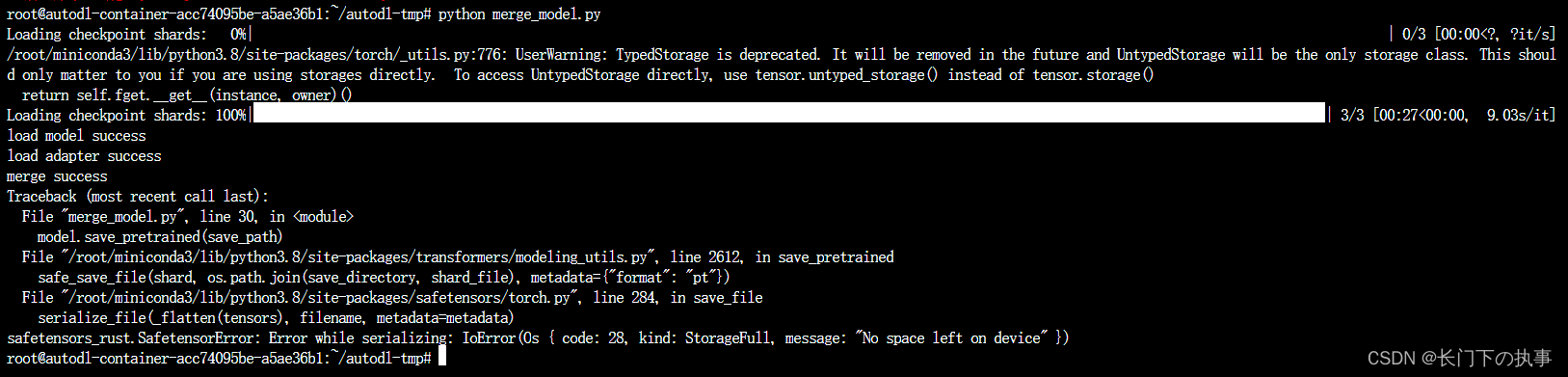
解决办法:这也没有很好的办法。。。要么扩容数据盘,要么换成小体量的模型。这里我扩容了20G硬盘,合并后保存的模型居然有25G,难怪硬盘会爆。
最终效果
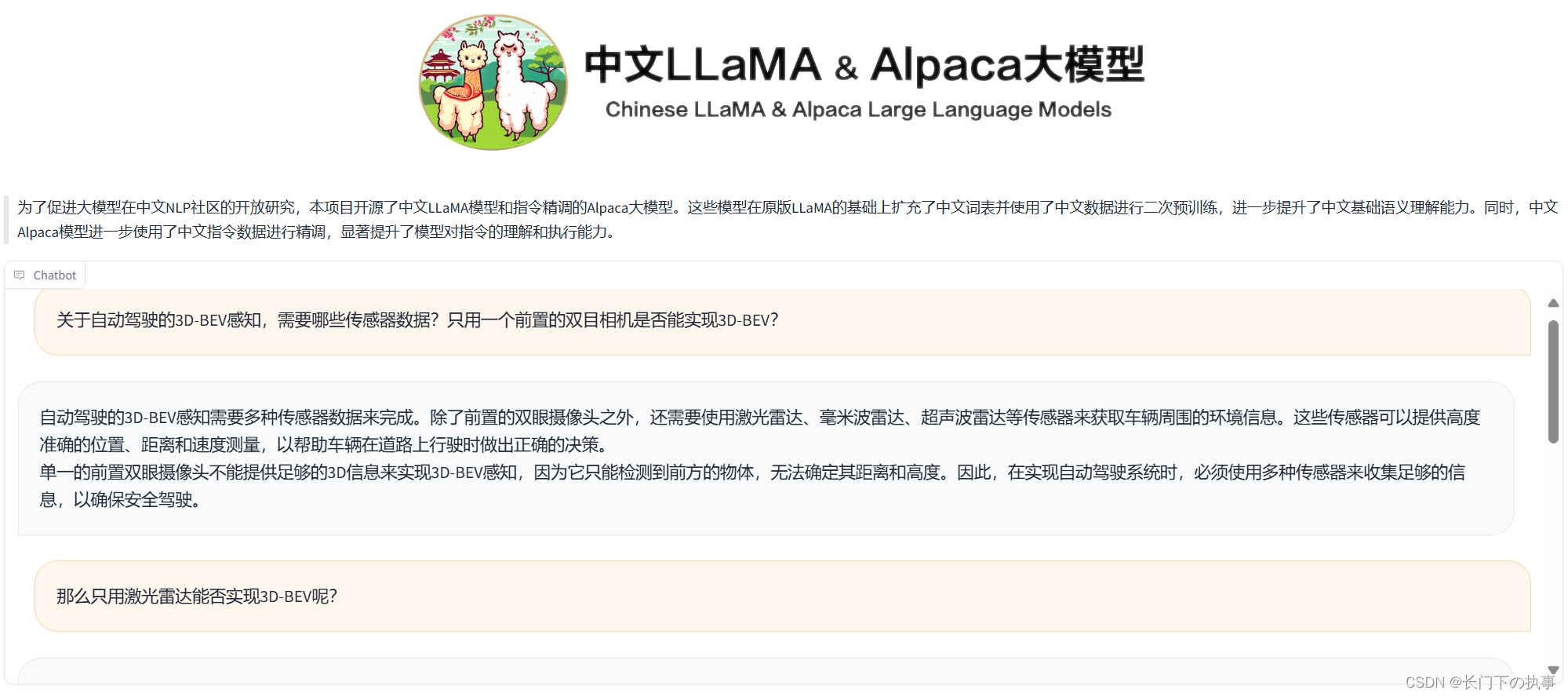
过程分析与总结
大模型微调这块需要的显存和硬盘空间都超乎想象,不知道为什么比教程里消耗的资源要高不少。在使用LoRA微调时,batch_size=2才能在A100上跑起来,合并后保存的模型占用硬盘容量25G,不愧是大模型。因为训练的轮数很少,所以效果一般,并且这是chat模型,微调的Belle数据集也是对话数据集,因此只适合通用知识的对话。















 2022
2022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









