







相关链接
- 【计算机二级Python】考试攻略及资料汇总
- 【计算机二级Python】模拟试卷第1套选择题
- 【计算机二级Python】模拟试卷第2套选择题
- 【计算机二级Python】模拟试卷第2套选择题
- 【计算机二级Python】模拟试卷第3套选择题
- 【计算机二级Python】模拟试卷第4套选择题
- 【计算机二级Python】模拟试卷第5套选择题
- 【计算机二级Python】模拟试卷第6套选择题
- 【计算机二级Python】模拟试卷第7套选择题
- 【计算机二级Python】模拟试卷第8套选择题
- 【计算机二级Python】上机历年实操题答案
第一套
(1)键盘输入正整数n,按要求把n输出到屏幕,格式要求:宽度为20个字符,减号字符-填充,右对齐,带千位分隔符。如果输入正整数超过20位,则按照真实长度输出。例如:键盘输入正整数n为1234,屏幕输出---------------1,234
n = eval(input("请输入正整数:"))
s = "{:->20,}".format(n)
print(s)
(2)a和b是两个列表变量,列表a为[3, 6, 9]己给定,键盘输入列表b, 计算a中元素与b中对应元素乘积的累加和。例如:键盘输入列表b为[1,2,3],累加和为13+26+3*9=42,因此,屏幕输出计算结果为42
a = [3,6,9]
b = eval(input()) #例如:[1,2,3]
s = 0
for i in range(len(a)):
s += a[i]*b[i]
print(s)
(3)以123为随机数种子,随机生成10个在1 (含)到999 (含)之间的随机数,每个随机数后跟随一一个逗号进行分隔,屏幕输出这10个随机数。
import random
random.seed(123)
for i in range(10):
print(random.randint(1,1000), end=",")
(4)使用turtle库的turtle.right()函数和turtle.fd()函数绘制一个菱形,边长为 200
像素,4个内角度数为2个60度和2个120度,效果如图所示

import turtle as t
t.right(-30) #起始顶点绝对角度设为正30度
for i in range(4): #画4边,转向4次
t.fd(200)
degree = 60*(1+i%2) #其他3顶点右转角度分别为60、120、60度
t.right(degree)
t.done()
(5)键盘输入一-组人员的姓名、性别、年龄等信息,信息间采用空格分隔,每人一-行,空行回车结束录入,示例格式如下:
张三男23
李四女21
王五男18
计算并输出这组人员的平均年龄(保留2位小数)和其中男性人数,格式如下:
平均年龄是20.67男性人数是2
nstr = input()
malecount = 0
allnumber = 0
age = 0
while nstr:
nlist =nstr.split()
allnumber +=1
age +=int(nlist[2])
if nlist[1] == '男':
malecount +=1
nstr = input()
if nstr =='':
print('平均年龄是{0:.2f},男性人数是{1}'.format(age/allnumber,malecount))
break
(6)考生文件夹下存在 3 个 Python 源文件,分别对应3个问题, 1个文TXT文件,作为本题目输入数据,请按照源文件内部说明修改代码,实现以下功能: 《命运》是著名科幻作家倪匡的作品。这里给出《命运》的一个网络版TXT文件,文件名为“命运.txt ”。
问题 1 ( 5 分):在PY301_1.py文件中修改代码,对“命运.txt ”文件进行字符频次统计,输出频次最高的中文字符(不包含标点符号)及其频次,字符与频次之间采用英文冒号’ : ”分隔,示例格式如下:
理:224
问题 2 ( 5 分):在 PY301_2.py文件中修改代码,对“命运.txt ”文件进行字符频次统计,按照频次由高到低,屏幕输出前10个频次最高的字符,不包含回车符,字符之间无间隔,连续输出,示例格式如下:
理斯卫 … (后略,共 10 个字符)
问题 3 ( 10 分):在 PY301_3 . py文件中修改代码,对“命运.txt ”文件进行字符频次统计,将所有字符按照频次从高到低排序,字符包括中文、标点、英文等符号,但不包含空格和回车。将排序后的字符及频次输出到考生文件夹下,文件名为“命运-频次排序.txt ”。字符与频次之间采用英文冒号” : ”分隔,各字符之间采用英文逗号’ , ’分隔,参考 CSV格式,最后无逗号,文件内部示例格式如下:
理:224,斯:120,卫:100
问题一
fate = open('命运-网络版.txt','r',encoding = 'utf-8')
lines = fate.read()
fuhao = ['《','》','-','。','?','(',')',',',':','"','、','!','\n','\u3000',' '] #这里\u3000代表全角空格,在考试中没有这种问题存在。在题录中的命运-网络版.txt我呢本中存在全角空格
d={} #定义一个空字典,用于存储相同字符出现的个数
for word in lines:
if word in fuhao: #除去符号
continue
else:
d[word] = d.get(word,0) + 1 #相同字符出现则加1
fate.close()
ls = list(d.items()) #可以通过print(ls)尝试打印出ls的内容是什么样子。
ls.sort(key = lambda x:x[1],reverse = True)#本行代码题目已经给出的,将ls按照统计数量进行从大大小排序,当reverse=False时:为正向排序;当reverse=True时:为反向排序。
print('{}:{}'.format(ls[0][0],ls[0][1]))
问题二
# 把第一问的输出改为
for i in range(10):
print(ls[i][0],end= '') #将字符输出,不包含回车符,字符无间隙
问题三
#把第一问的输出改为
file = open('命运-频次排序.txt','w',encoding='utf-8')
for tu in ls:
filestr = tu[0]+':'+str(tu[1])+','
file.write(filestr)
file.close()
第二套
(1)计算下列数学表达式的结果并输出,小数后保留三位
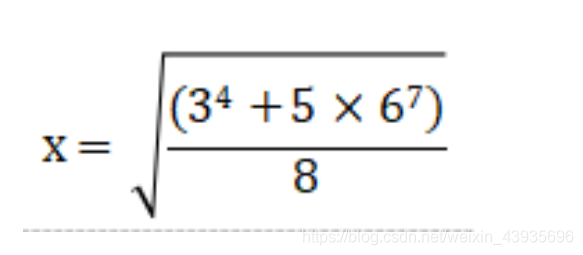
import math
x = math.sqrt((pow(3,4)+5*pow(6,7))/8)
print('{:0.3f}'.format(x))
print()
(2)用Python内置函数及jieba库中已有的计算字符串S的中外文字符个数以及中文词语个数。注意,中文字符包含中文标点符号。
中国特色社会主义进入新时代,我国社会主要矛盾已经转化为人民日益增长的美好生活需要和不平衡不充分的发展之间的矛盾
import jieba
s = '中国特色社会主义进入新时代,我国社会主要矛盾已经转化为人民日益增长的美好生活需要和不平衡不充分的发展之间的矛盾。'
n = len(s)
m = len(jieba.lcut(s))
print('中文字符数为{},中文词语数为{}'.format(n,m))
(3)使用turtle的fd函数和seth函数绘制一个边长为200的正方形
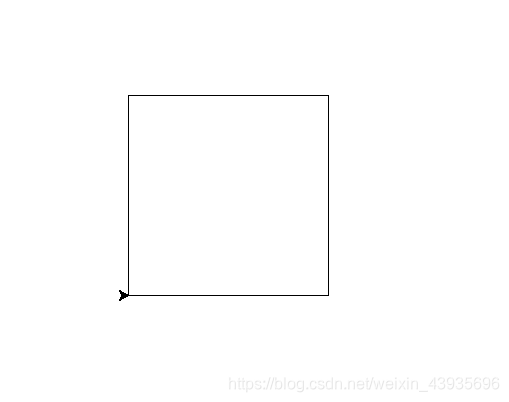
import turtle
d = 0
for i in range(4):
turtle.fd(200)
d =d +90
turtle.seth(d)
print()
(4)输出列表中个元素的数量,格式是
军事:1
农林:1
师范:2
理综:4
综合:5
理工:6
# 方法一
from collections import Counter
ls = ['理综','理工','综合','理综','理工','综合','理综','理工','综合','理综','理工','理工','综合','师范','理工','综合','农林','师范','军事']
# 利用Counter进行统计元素数量
tempdict = dict(Counter(ls).most_common())
# 对字典的值进行排序
tutemp = sorted(tempdict.items(), key = lambda kv:kv[1],reverse =false)
for i in tutemp:
print('{}:{}'.format(i[0],i[1]))、
# 方法二
ls = ['理综','理工','综合','理综','理工','综合','理综','理工','综合','理综','理工','理工','综合','师范','理工','综合','农林','师范','军事']
d = {}
for word in ls:
d[word] = d.get(word,0)+1
# 字典排序
tutemp = sorted(d.items(),key = lambda kv:kv[1],reverse = False)
for i in tutemp:
print('{}:{}'.format(i[0],i[1]))
(5)
第三套
(1)随机选择一个手机品牌屏幕输出。
题目给出的文件如下:
import ___
brandlist=[‘华为’,‘苹果’,‘诺基亚’,‘0PPO’,‘小米’]
random.seed(0)
…
print(name)
import random
brandlist=['华为','苹果','诺基亚','OPPO','小米']
random.seed(0)
random.seed()
idx=random.randint(0,4)
name= brandlist[idx]
print(name)
(3)键盘输入一段文本,保存在一个字符串变量s中,分别用Python内置函数及jieba库中已有函数计算字符串s的中文字符个数及中文词语个数。注意:中文字符包含中文标点符号。
例如,键盘输入:俄罗斯举办世界杯 ,屏幕输出:中文字符数为8,中文词语数为3。
import jieba
s=input("请输入一个字符串")
n=len(s)
m=len(jieba.lcut(s))
print("中文字符数为{},中文词语数为{}。".format(n,m))
(4)某商店出售某品牌运动鞋,每双定价160,1双不打折,2双(含)到4双(含)打九折,5双(含)到9双(含)打八折,10双(含)以上打七折,键盘输入购买数量,屏幕输出总额(保留整数)。
示例格式如下:输入:1 输出:总额为160
n=eval(input("请输入数量:"))
if n<=1:
r=1
elif n<=4:
r=0.9
elif n<=9:
r=0.8
else:
r=0.7
cost=int(n*160*r)
print("总额为:",cost)
(5)使用 turtle 库的 turtle.fd()函数和turtle.seth()函数绘制一个边长为200的正菱形,菱形 4个内角均为 90 度。效果如下图所示,箭头与下图严格一致。
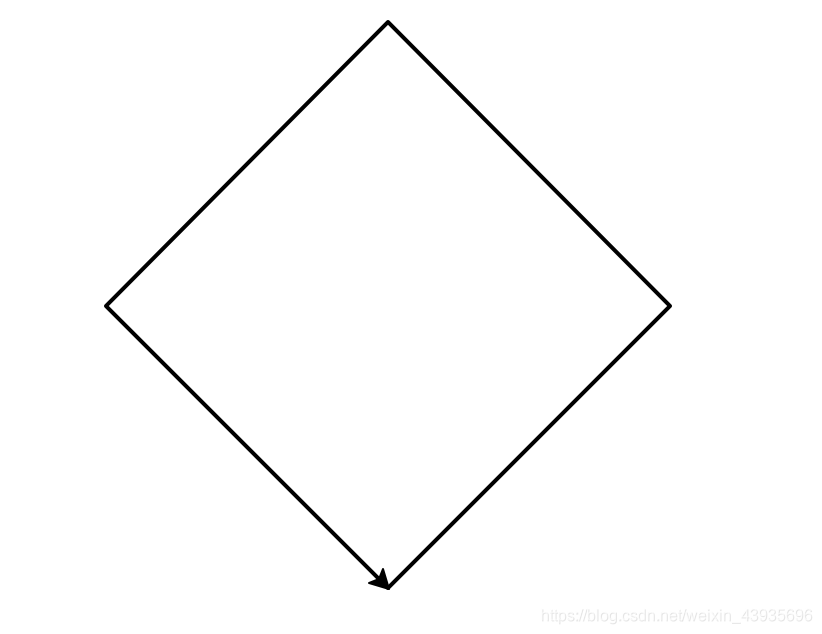
import turtle
turtle.pensize(2)
d=45
for i in range(4):
turtle.seth(d)
d +=90
turtle.fd(200)
(6)下面所示为一套由公司职员随身佩戴的位置传感器采集的数据,文件名称为“sensor.txt”,其内容示例如下
2016/5/31 0:05, vawelon001,1,1
2016/5/31 0:20, arpa001,1,1
2016/5/31 2:26, arpa001,1,6
… (略)
第一列是传感器获取数据的时间,第二列是传感器的编号,第三列是传感器所在的楼层,第四列是传感器所在的位置区域编号。
问题1 : 读入sensor.txt文件中的数据,提取出传感器编号为arpa001的所有数据,将结果输出保存到“arpa001.txt”文件。
输出文件格式要求:原数据文件中的每行记录写入新文件中,行尾无空格,无空行。参考格式如下:
2016/5/31 7:11, arpa001,2,4
2016/5/31 8:02, arpa001,3,4
2016/5/31 9:22, arpa001,3,4
…(略)
问题2: 读入“ arpa001.txt”文件中的数据,统计 arpa001对应的职员在各楼层和区域出现的次数,保存到“ earpa001_count.txt”文件,每条记录一行,位置信息和出现的次数之间用英文半角逗号隔开,行尾无空格,无空行。参考格式如下
1-1,5
1-4,3
…(略)
含义如下:第1行“1-1,5”中1-1表示1楼1号区域,5表示出现5次;第2行“1-4,3”中1-4表示1楼4号区域,3表示出现3次;
# 问题一
fi = open("sensor.txt",'r',encoding='utf-8') #如果运行后出现了Unicode错误,则添加上encoding='utf-8'
fo = open("earpa001.txt","w")
for line in fi:
ls = line.strip("\n").split(",") #strip("\n")除去行尾的换行符,split(",")将每行的逗号进行分隔,可以通过print(ls)查看一下该内容是什么样的。
if "earpa001" in ls[1]:
fo.write('{},{},{},{}\n'.format(ls[0],ls[1],ls[2],ls[3]))
fi.close()
fo.close()
# 问题二
fi = open("earpa001.txt","r")
fo = open("earpa001_count.txt","w")
d = {}
for line in fi:
t = line.strip(" \n").split(",")
s = t[2] + "-" + t[3]
d[s] = d.get(s,0) + 1 # 如果字典d中存在键s则将字典d中键为s的值+1,如果不存在,则默认值为0再+1,也对应是第一次遍历到该楼层和区域。
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 该语句用于排序,当reverse=False时:为正向排序;当reverse=True时:为反向排序。
for i in range(len(ls)):
a,b = ls[i]
fo.write('{},{}\n'.format(a,b))
fi.close()
fo.close()
第四套
(1)从键盘输入 4 个数字,各数字采用空格分隔,对应为变量 x0 , y0 , x1 , y1 。计算两点(x0 , y0)和 ( X1 , y1 )之问的距离,屏幕输出这个距离,保留 2 位小数。
例如:键盘输入: 0 1 3 5
屏幕输出:5 . 00
import math
nlist = input().split()
intlist = list(map(int,nlist))
result = math.sqrt(pow((intlist[0]-intlist[2]),2)+pow((intlist[1]-intlist[3]),2))
print('{0:.2f}'.format(result))
(2)键盘输入一段中文文本,不含标点符号和空格,命名为变量 s ,采用jieba库对其进行分词,输出该文本中词语的平均长度,保留 1 位小数。
例如:键盘输入:吃葡萄不吐葡萄皮
屏幕输出:1.6
import jieba
nlist = input()
jielen = len(jieba.lcut(nlist))
wordlen = len(nlist)
print(wordlen/jielen)
(3)键盘输入一个 9800 到 9811 之间的正整数 n ,作为 Unicode 编码,把 n -1 、 n 和 n + 1 三个 Unicode 编码对应字符按照如下格式要求输出到屏幕:宽度为 11 个字符,加号字符+填充,居中。
例如:键盘输入: 9802 屏幕输出:++++♉♊♋++++
n = eval(input())
print("{:+^11}".format(chr(n - 1) + chr(n) + chr(n+1)))
(4)使用 turtle 库的 turtle.fd()函数和 turtle.seth ()函数绘制一个每方向为 100 像素长度的十字形,效果如图所示。

import turtle
for i in range(4):
turtle.fd(100)
turtle.fd(-100)
turtle.seth((i+1)*90)
(5)与上面的题重复,略
(6)《论语》是儒家学派的经典著作之一,主要记录了孔子及其弟了言行。这里给出了一个网络版本的《论语》,文件名称为“论语.txt",其内容采用逐句“原文”与逐句‘’注释”相结合的形式组织,通过【原文】标记《论语》原文内容,通过【注释】 标记《论语》注释内容,具体文件格式框架请参考“论语.txt”文件。
问题1 在 PY301_1.py 文件中修改代码,提取“论语.txt ”文件中的原文内容,输出保存到考生文件夹下,文件名为“论语-原文.txt ”。
具体要求:仅保留“论语.txt ”文件中所有【原文】标签下面的内容,不保留标签,并去掉每行行首空格及行尾空格,无空行。原文小括号及内部数字是源文件中注释项的标记,请保留。示例输出文件格式请参考“沦语-原文-输出示例.txt”文件。
注意:示例输出文件仅帮助考生了解输出格式,不作它用。
问题 2 在 PY301-2.py文件中修改代码,对“论语-原文.txt ”或“论语.txt ”文件进一步提纯,去掉每行文字中所有小括号及内部数字,保存为“论文-提纯原文.txt”文件。示例输出文件格式请参考“论语-提纯原文-输出示例.txt ”文件。
# 问题一
fi = open ('/论语.txt',"r",encoding='utf-8')
fo = open ( "论语-原文.txt", "w" )
wflag = False
for line in fi :
if "【" in line:
wflag = False
if "【原文】" in line :
wflag = True
continue
if wflag == True :
line = line.strip(" ")
if line.count('\n') != len(line):
fo.write(line)
fi.close()
fo.close()
# 问题二
fi = open("论语-原文.txt", "r")
fo = open( "论语-提纯原文.txt" , "w")
for line in fi: #逐行遍历
for i in range (1,23): #对产生 1 到 22 数字
line = line.replace("({})".format(i),"") #构造( i )并替换
fo.write(line)
fi.close()
fo.close()


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











