






一、概述
生存分析(Survival Analysis)是用来描述和分析时间因素对个体生存的影响,其中生存曲线一般是常见的图表之一。而通过Kaplan-Meier(KM)法,可以绘制生存曲线用以描述研究对象的存活情况。
KM生存曲线是用来描述随时间推移一个群体中存活的比例,通常是用来描述疾病的存活率。在 KM 生存曲线上,X 轴表示时间,而 Y 轴表示生存率(或存活概率或累计存活率),即一个人在某一时间存活下来的概率。KM 生存曲线通常呈现出一条向下的曲线,这个曲线被称为“生存函数”。
- 生存函数始终在 1.0 以上开始;
- 随着时间的推移,生存函数会逐渐降低,最后可能趋向于 0;
- 每次出现事件(如死亡,治愈等)时,生存函数都会发生一次跳跃。
KM 生存曲线可以用来描述随时间变化的生存率。在医学、流行病学、生物学等领域,它被广泛应用于对疾病、药物、手术等治疗方法的效果评估和预测。
二、数据集
2.1 安装及其使用
library(survival)
library(survminer)
library(mice)
library(pROC)
str(lung)2.2 读取数据
'data.frame': 228 obs. of 10 variables:
$ inst : num 3 3 3 5 1 12 7 11 1 7 ...
$ time : num 306 455 1010 210 883 ...
$ status : num 2 2 1 2 2 1 2 2 2 2 ...
$ age : num 74 68 56 57 60 74 68 71 53 61 ...
$ sex : num 1 1 1 1 1 1 2 2 1 1 ...
$ ph.ecog : num 1 0 0 1 0 1 2 2 1 2 ...
$ ph.karno : num 90 90 90 90 100 50 70 60 70 70 ...
$ pat.karno: num 100 90 90 60 90 80 60 80 80 70 ...
$ meal.cal : num 1175 1225 NA 1150 NA ...
$ wt.loss : num NA 15 15 11 0 0 10 1 16 34 ...
2.3 数据预处理
# 数据补全
input.data <- mice(lung,seed=5)
data <- complete(input.data,3)结果展示
'data.frame': 228 obs. of 10 variables:
$ inst : num 3 3 3 5 1 12 7 11 1 7 ...
$ time : num 306 455 1010 210 883 ...
$ status : num 2 2 1 2 2 1 2 2 2 2 ...
$ age : num 74 68 56 57 60 74 68 71 53 61 ...
$ sex : num 1 1 1 1 1 1 2 2 1 1 ...
$ ph.ecog : num 1 0 0 1 0 1 2 2 1 2 ...
$ ph.karno : num 90 90 90 90 100 50 70 60 70 70 ...
$ pat.karno: num 100 90 90 60 90 80 60 80 80 70 ...
$ meal.cal : num 1175 1225 825 1150 488 ...
$ wt.loss : num 15 15 15 11 0 0 10 1 16 34 ...三、使用方法
3.1 基础使用方法
km_fit <- survfit(Surv(time, status) ~ sex, data = lung)
plot(km_fit, main = "KM Survival Curve for Lung Cancer Patients")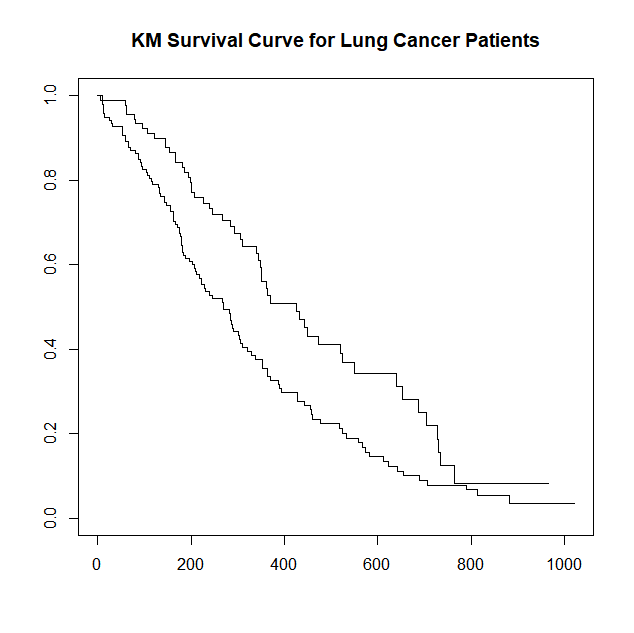
3.2 进阶使用方法
KM曲线适用于分类变量,那连续变量是如何做KM曲线的呢?
- 通常可以将连续变量按照一定的区间进行分组,以得到离散的自变量变量,然后进行KM曲线的绘制与比较。
- 通常ROC曲线分析计算出的截断值进行分组
roc <- roc(status ~ ph.karno,data = data)
roc_data <- coords(roc,"best",transpose = FALSE) # 敏感度 特异度 截断值
roc_data$threshold
data$phc[data$ph.karno < roc_data$threshold] <- 0
data$phc[data$ph.karno >= roc_data$threshold] <- 1
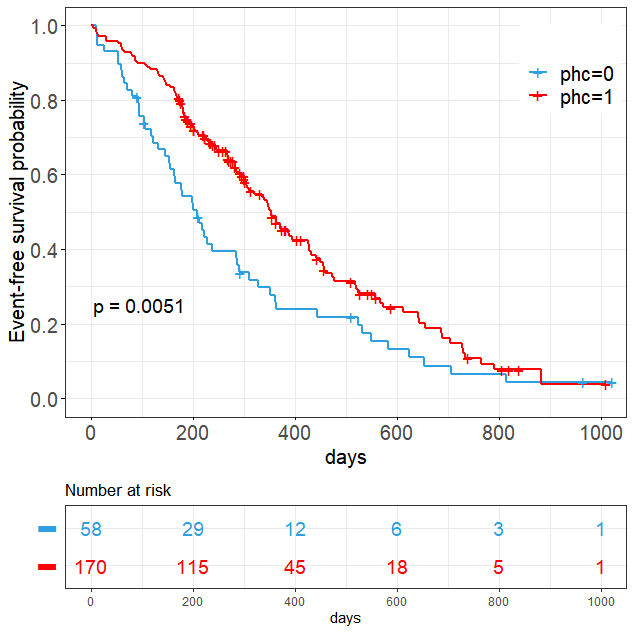
fit <- survfit(Surv(time,status) ~ phc,data = data)
ggsurvplot(fit, data = data,risk.table = TRUE,
ggtheme = theme_bw(),
xlab = "days",break.x.by=200,
tables.y.text=FALSE,legend.title="",
fontsize=5,break.y.by=0.2,
font.x = 15,
font.y = 15,
font.tickslab = 15,
font.legend = 15,
ylab='Event-free survival probability',
legend = c(0.90,0.85),pval.coord = c(5,0.25),pval.size=5,
pval.family="Times New Roman",palette = c("red","green"))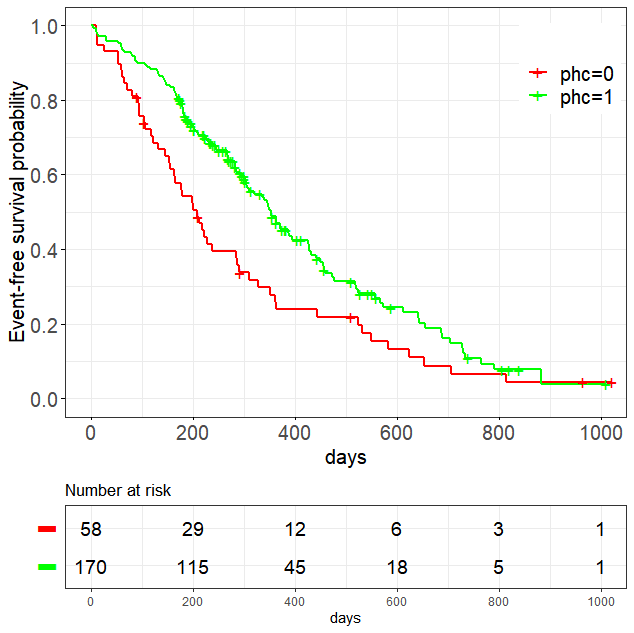
3.3 ggsurvplot参数介绍
fit
允许的值包括:
一个 survfit 对象
生存对象列表。传递给ggsurvplot_list()
包含生存曲线摘要的数据框。传递给 。ggsurvplot_df()
data
用于拟合生存曲线的数据集。如果未提供,则数据 将从“适合”对象中提取。
fun
定义生存变换的任意函数 曲线。可以使用字符指定常用转换 参数:“事件”绘制累积事件 (f(y) = 1-y),“cumhaz”绘制 累积风险函数 (f(y) = -log(y)) 和生存的“PCT” 概率百分比。
color
用于生存曲线的颜色。
如果 地层数/组数(n.strata)=1,期望值为颜色名称。 例如,颜色=“蓝色”。
如果 n.strata > 1,则期望值为 分组变量名称。默认情况下,生存曲线按地层着色 使用参数颜色=“地层”,但您也可以为生存曲线着色 通过用于拟合生存曲线的任何其他分组变量。在此 在这种情况下,可以使用参数指定自定义调色板 调色板。
palette
要使用的调色板。允许的值包括 “色调” 默认色相色标;“灰色”表示灰色调色板;布鲁尔调色板 例如“RdBu”、“Blues”等;或自定义调色板,例如 c(“蓝色”、“红色”);以及来自ggsci R软件包的科学期刊调色板,例如:“npg”, “AAAS”、“柳叶刀”、“JCO”、“UCSCGB”、“芝加哥”、“辛普森一家”和 “里坎德莫蒂”。 有关详细信息,请参阅详细信息部分。也可以是 长度(组);在这种情况下,使用 函数面板。
linetype
线类型。允许的值包括 i) 用于更改的“分层” 按地层划分的线型(即组);ii) 数字向量(例如,C(1, 2))或 字符向量 c(“实心”、“虚线”)。
conf.int
逻辑值。如果为 TRUE,则绘制置信区间。
pval
逻辑值、数字或字符串。如果合乎逻辑且为 TRUE,则 p 值将添加到图上。如果是数字,则计算 p 值为 替换为使用此参数传递的那个。如果字符,则 自定义字符串将显示在绘图上。请参阅示例 - 示例 3。
pval.method
是否添加具有用于 的测试名称的文本 计算 p值,对应于生存曲线的比较 - 仅在以下情况下使用pval=TRUE
test.for.trend
逻辑值。默认值为 FALSE。如果为 TRUE,则返回 检验趋势 p 值。趋势测试旨在检测有序 生存曲线的差异。也就是说,对于至少一个组。测试内容 对于趋势,仅当组数> 2 时才能执行。
surv.median.line
用于绘制水平/垂直的字符矢量 中位生存期线。允许的值包括 c(“none”, “hv”, “h”, “v”)。V:垂直,H:水平。
risk.table
允许的值包括:
对或错 指定是否显示风险表。默认值为 FALSE。
“绝对”或“百分比”。分别按时间显示绝对数量和处于危险中的受试者百分比。
“abs_pct” 以显示绝对数字和百分比。
“nrisk_cumcensor”和 “nrisk_cumevents”。显示有风险的数量,以及 分别审查和事件。
cumevents
指定是否显示 的表的逻辑值 事件的累积数。默认值为 FALSE。
cumcensor
指定是否显示 的表的逻辑值 审查的累计次数。默认值为 FALSE。
tables.height
指定一般高度的数值(在 [0 - 1] 中) 主生存图下的所有表。
group.by
包含分组变量名称的字符向量。长度应为 <= 2。 函数的别名。ggsurvplot_group_by()
facet.by
包含分组变量名称的字符向量 将生存曲线刻面为多个面板。长度应为 <= 2。 函数的别名。ggsurvplot_facet()
add.all
逻辑值。如果为 TRUE,则将合并患者的生存曲线(零模型)添加到主图上。 函数的别名。ggsurvplot_add_all()
combine
逻辑值。如果为 TRUE,则在同一图上组合一个列表 survfit 对象。 函数的别名。ggsurvplot_combine()
ggtheme
函数,ggplot2 主题名称。默认值为 theme_survminer。允许的值包括 ggplot2 官方主题:请参见。theme
tables.theme
函数,ggplot2 主题名称。默认值为 theme_survminer。允许的值包括 ggplot2 官方主题:请参见。请注意,是增量的。themetables.themeggtheme
...
下文所述的进一步论点和 要传递给 i) 的其他参数 i) 到 ggplot2 geom_*() 函数,例如 作为线型, 大小, ii) 或函数 ggpar() 的 自定义绘图。请参阅详细信息部分。
x
类 ggsurvplot 的对象
surv.plot.height
网格上生存图的高度。违约 为 0.75。当 risk.table = FALSE 时被忽略。
risk.table.height
网格上风险表的高度。增加 拥有多个地层时的值。默认值为 0.25。在以下情况下忽略 风险表=假。
ncensor.plot.height
审查情节的高度。在 时使用。ncensor.plot = TRUE
newpage
打开一个新页面。看grid.arrange✔
















 4708
4708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











