







EchoMimic更新啦,我24号刚出的一篇,到了25号官方就更新了新的加速模型。

着实没赶上官方更新的速度......
那本次我主要讲下更新了什么内容,如何修改使用acc加速模型。
另外还准备了v2版本的整合包!大家可以体验下!
更新内容
那先来看下本次更新的内容:
Audio Driven加速模型及管道发布,推理速度提升10 倍(V100 GPU 上从 ~7mins/240frames 提升至 ~50s/240frames)
简单来说就是更新了新的加速模型,比上个版本的速度提升了不少(官方说是10倍)。
实际测试下来,之前同样的素材,(4090)未加速的话6steps是要2分钟左右,加速后的只需要30多秒左右,提升确实很大。
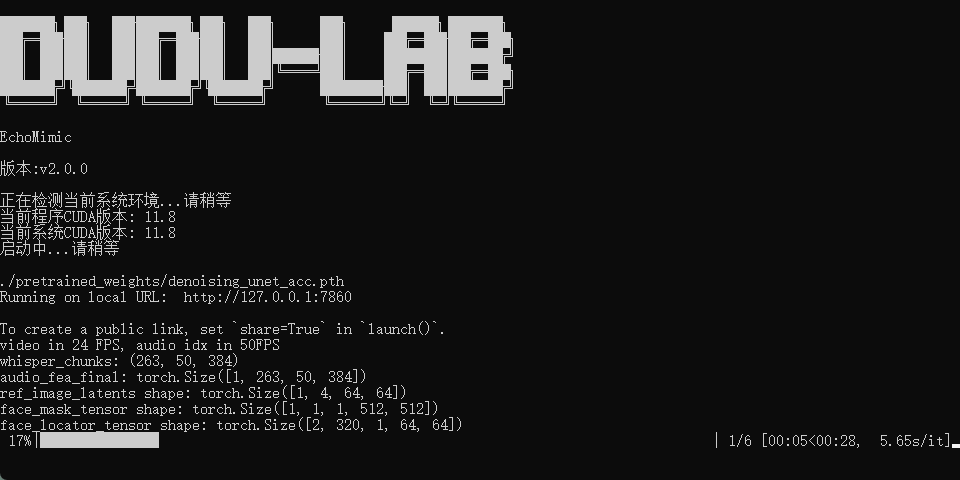
webui修改acc加速
虽说官方更新了加速模型和相关示例代码,但是webgui脚本还是2周前的,新版本使用还是会报错。
然后看到GitHub上有很多小伙伴也都遇到了这个问题
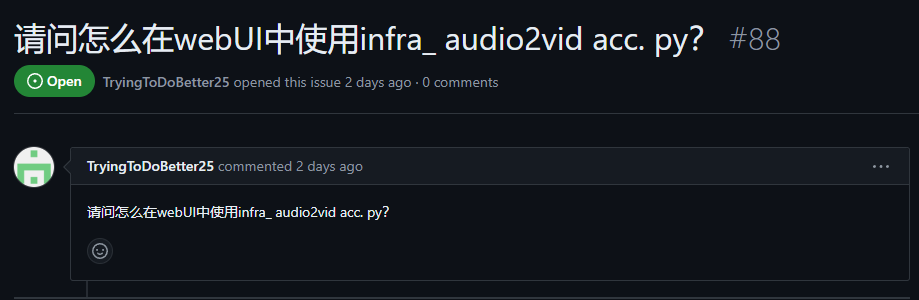
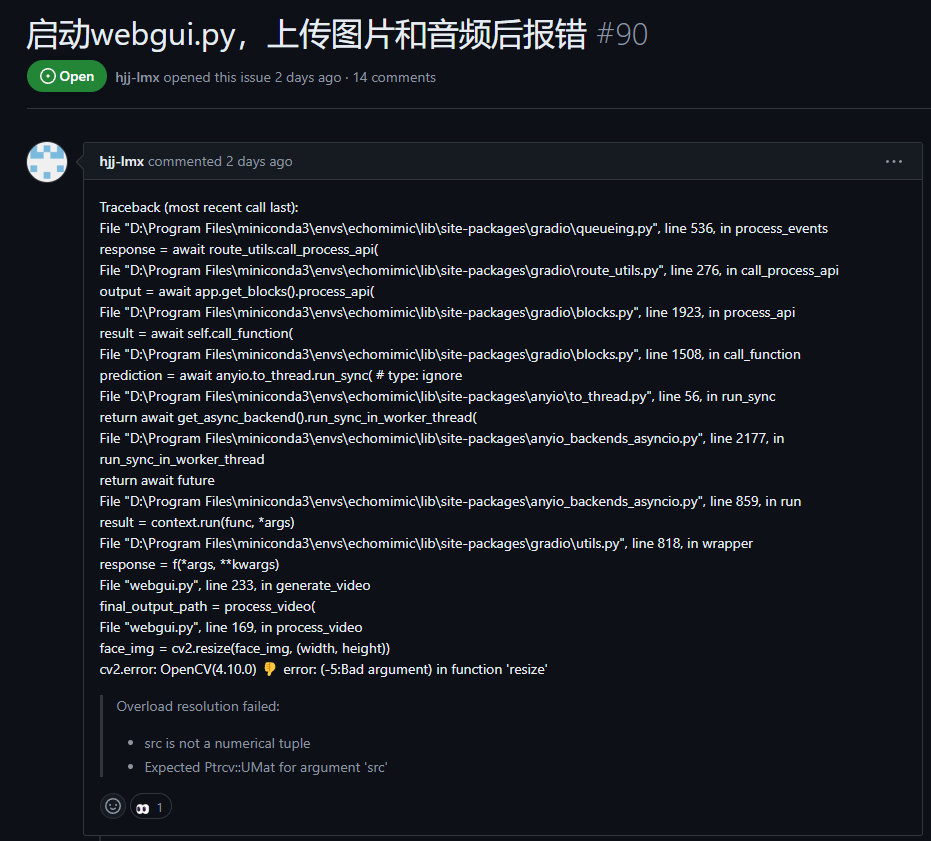
这里说下解决方法,来到webgui.py脚本下
process_video函数下:
face_img,crop_rect = crop_and_pad(face_img, crop_rect)
face_mask,crop_rect = crop_and_pad(face_mask, crop_rect)修改为
face_img,_ = crop_and_pad(face_img, crop_rect)
face_mask,_ = crop_and_pad(face_mask, crop_rect)脚本导入模块这里
from src.pipelines.pipeline_echo_mimic import Audio2VideoPipeline修改为
from src.pipelines.pipeline_echo_mimic_acc import Audio2VideoPipelineconfig_path这里
config_path = "./configs/prompts/animation.yaml"修改为
config_path = "./configs/prompts/animation_acc.yaml"修改完以上内容后,启动webgui.py就可以正常使用加速模型啦!
整合包获取
当然如果你不想修改也可以直接下载好我制作的整合包
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻

关注我们的公众号:嘟嘟实验室,发送【EchoMimic】关键字获取整合包。
如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!
注意关键字大小写
制作不易,如果本文对您有帮助,还请点个免费的赞或在看!感谢您的阅读!


















 1607
1607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









