









哈喽!EchoMimic更新咯,本次EchoMimicV2版本增加了数字人功能,即输入一张图片、一段音频、一段姿势即可生成一段数字人视频。

如果第一次了解这个项目的朋友可以看下往期文章,看下之前的V1版本
https://blog.csdn.net/weixin_43935971/article/details/140651570
https://blog.csdn.net/weixin_43935971/article/details/140752410
简单吐槽下,在我刚部署项目的时候,官方还没推出gradio界面的代码,于是着手开始写一套,等我写完了,测试完了…GitHub上又有gradio相关的代码了…真的是太速度了!
吐血…不过没关系,也算同步进行了…
我在使用的时候也发现了这个版本的一些问题,并做了一些改动,在下面有讲到。
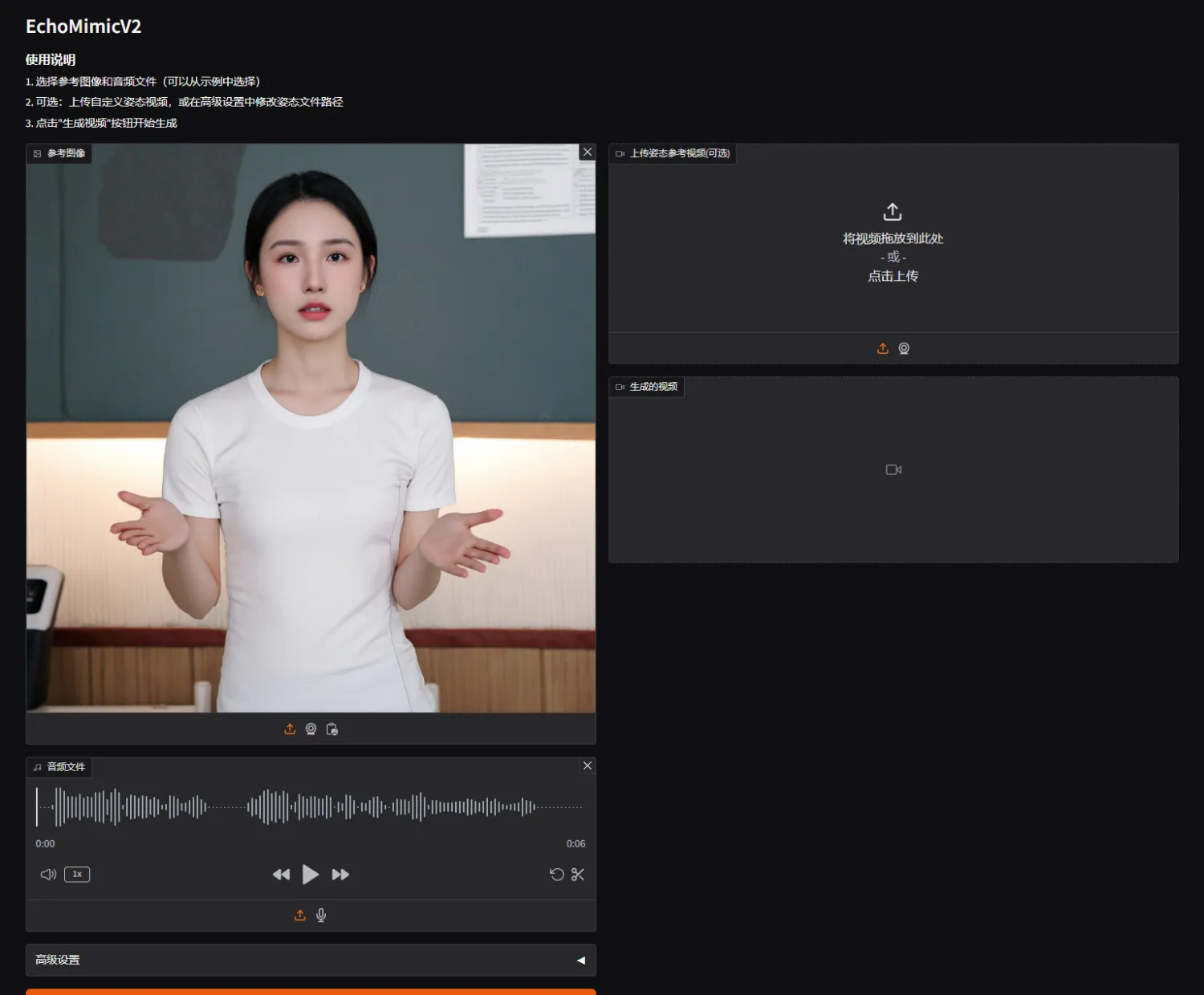
快速上手
使用方法不难,上传一张图片,一段说话的音频。
(图片尽量分辨率不要太大,人物居中,清晰即可。音频不要有嘈杂的背景音,尽量干净的人声。)
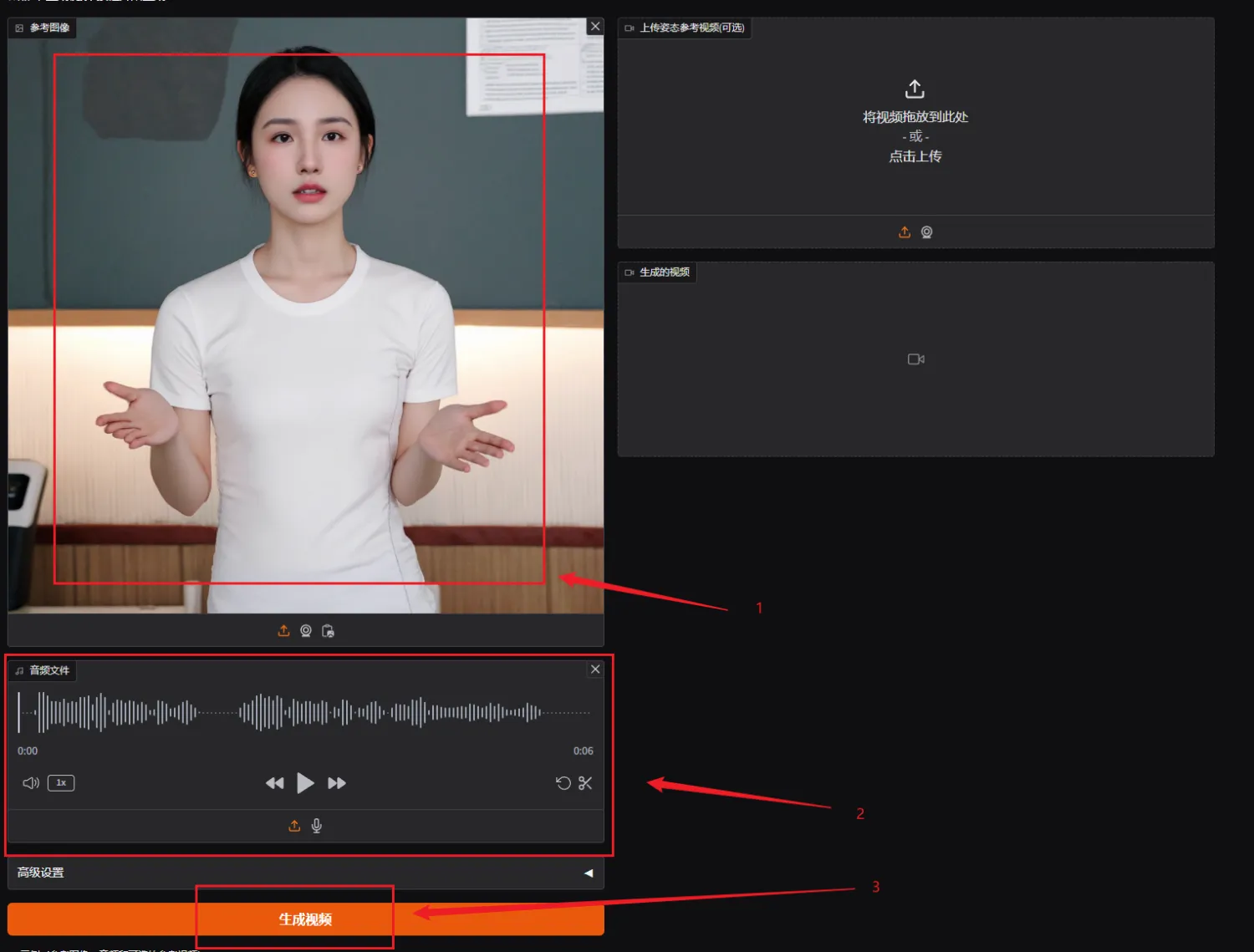
点击生成视频就能得到数字人视频啦!
当项目部署完在跑测试的时候,我发现官方放出的示例并没有自定义姿势的逻辑,也就是说只能使用官方提供的一段固定手势。
额…(挠头.gif)
于是我增加了一个上传姿态参考视频的逻辑。

现在你可以上传一段视频作为动作参考,生成的数字人会模仿视频里的动作。
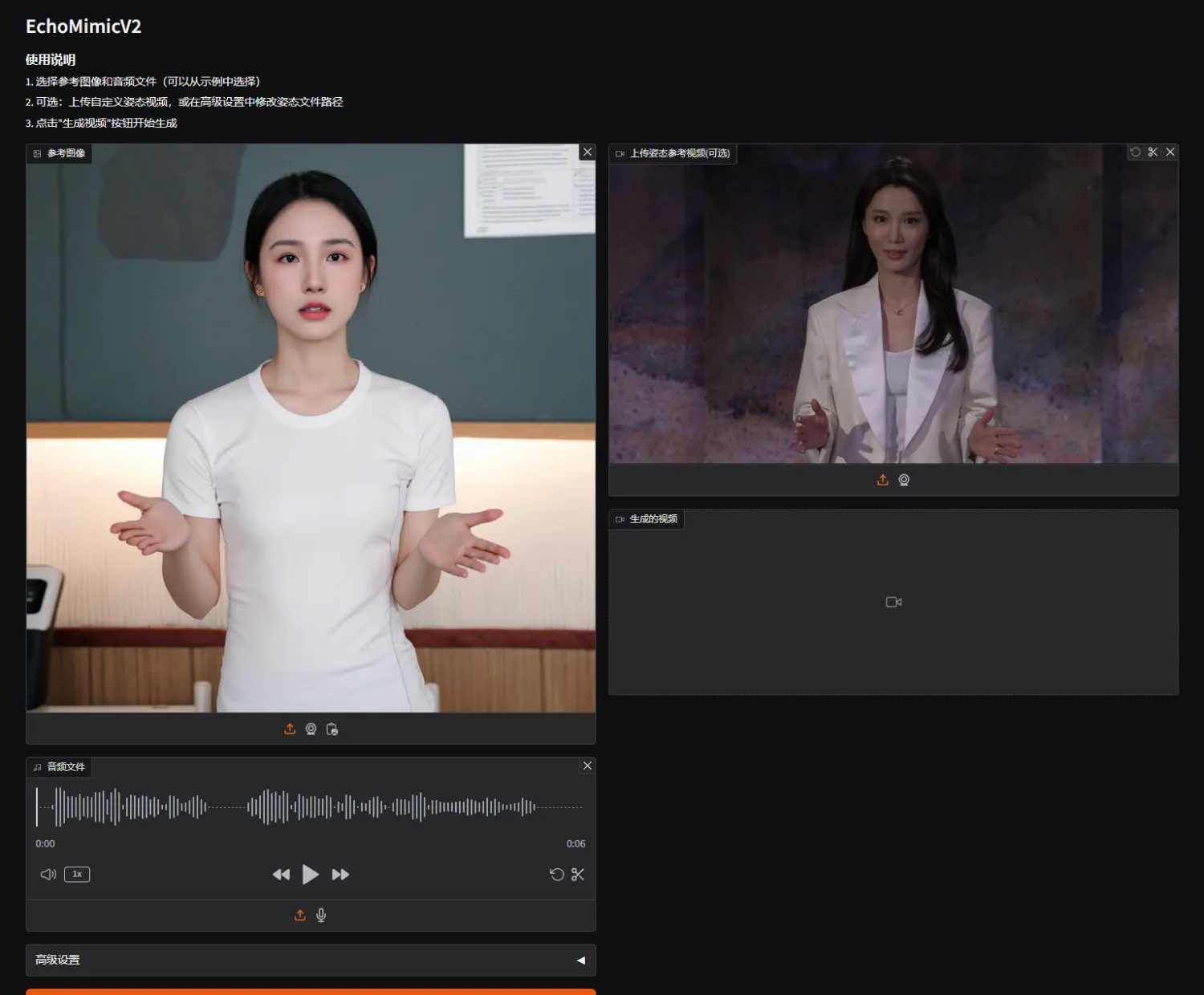
当然,官方也在开发这个模块,也期待一波官方的更新!
高级设置这里可以调节更多的参数,具体的都有解释。建议视频帧率和音频采样率不要乱改。
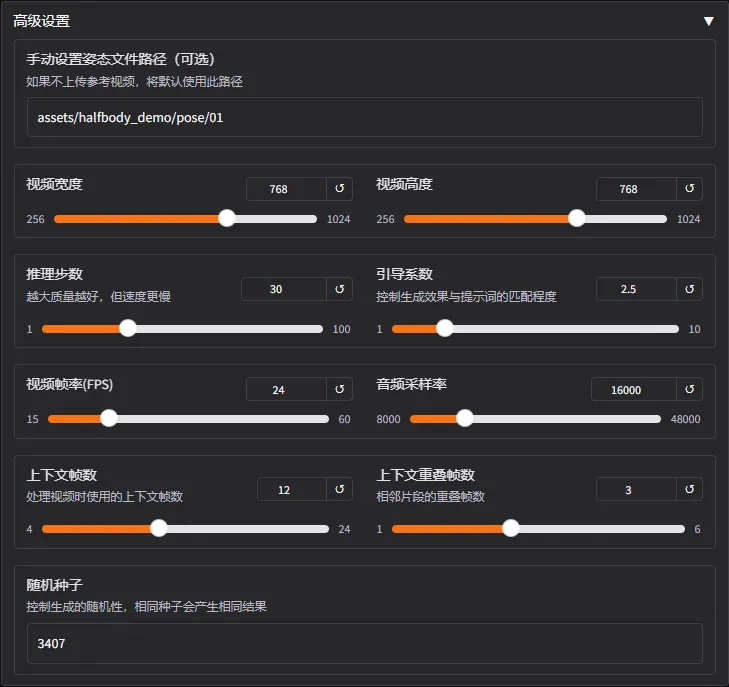
手动设置姿态文件路径就是官方示例里的默认姿态文件。如果你不上传参考视频的话,就是默认使用这个。
配置需求
WIN
N卡需12G显存以上。推荐16G显存。
截止我写这篇文章的时候,官方已经推出了int8量化,目前可以优化到12G显卡可以使用。
MAC
(带不动,咱们MAC用户还是上云吧🤦)
云端镜像稍后更新
整合包获取
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻
关注公众号,发送【EchoMimic数字人】关键字获取整合包。
如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!
制作不易,如果本文对您有帮助,还请点个免费的赞或在看!感谢您的阅读!


















 9778
9778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









