







好久不见,昨天看到智谱AI推出了端到端的语音模型GLM-4-Voice,迫不及待的来部署体验下。

GLM-4-Voice 能够直接理解和生成中英文语音,进行实时语音对话,并且能够遵循用户的指令要求改变语音的情感、语调、语速、方言等属性。
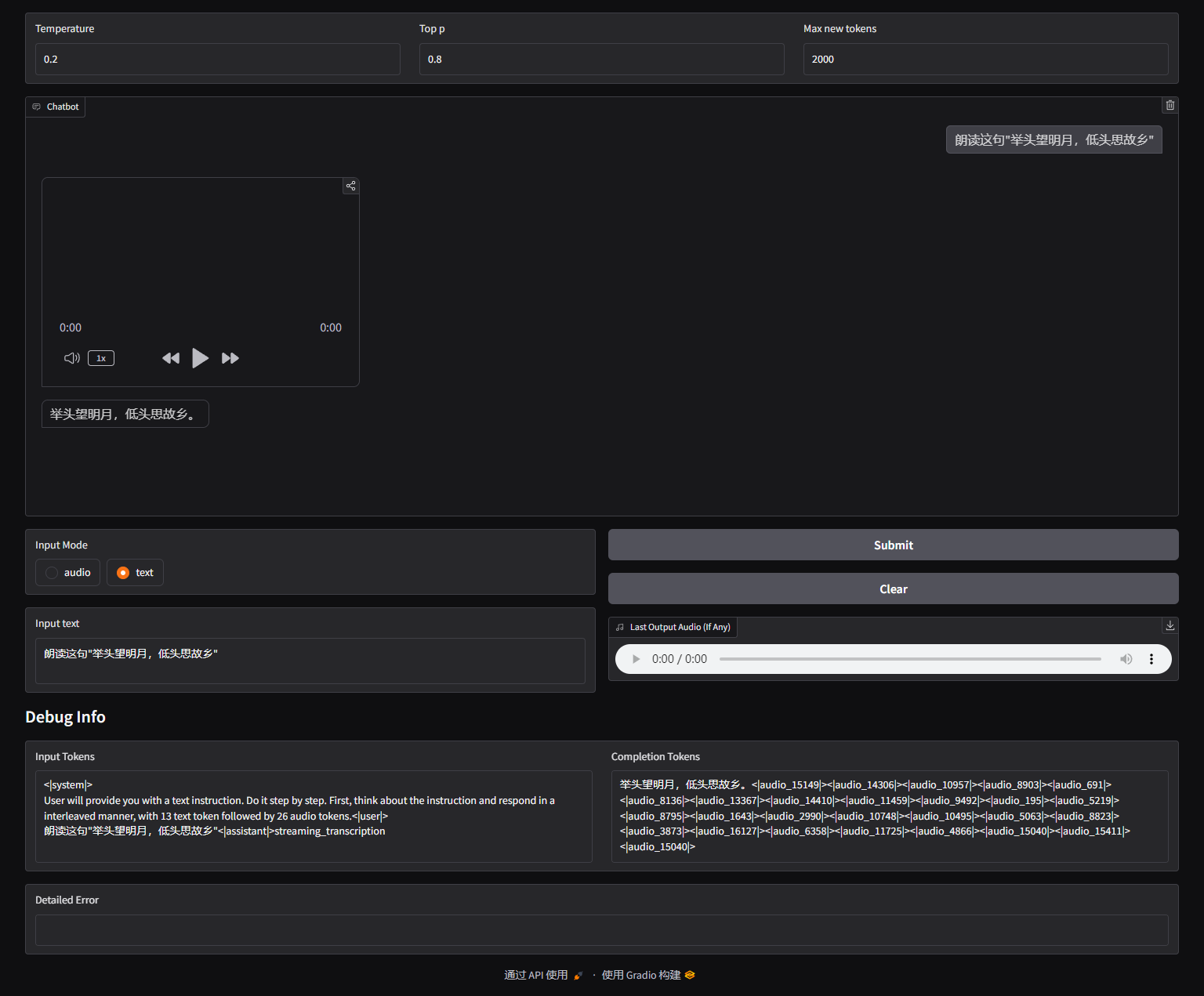
用户可以输入语音或文本,模型会同时给出语音和文字回复。
效果
那先看看效果
我先让GLM-4-Voice朗读一段诗词

举头望明月
还不错,上点强度

粤菜
当然也可以说指定的文案

粤语指定
还尝试了东北话(但是不太明显)

东北话
除了可以说方言以外,GLM-4-Voice还支持语速控制、感情控制等。你只需要输入描述文字即可。这里我不过多演示。
使用
我们制作了Windows版本的整合包,原本想Mac版本也出一个,但是看到占用显存很大,直接放弃。
整合包目录下有两个exe
先点击启动服务
启动成功后,这个窗口不要关闭,双击启动webui.exe
进入程序界面
在这里输入你的文本,点击提交
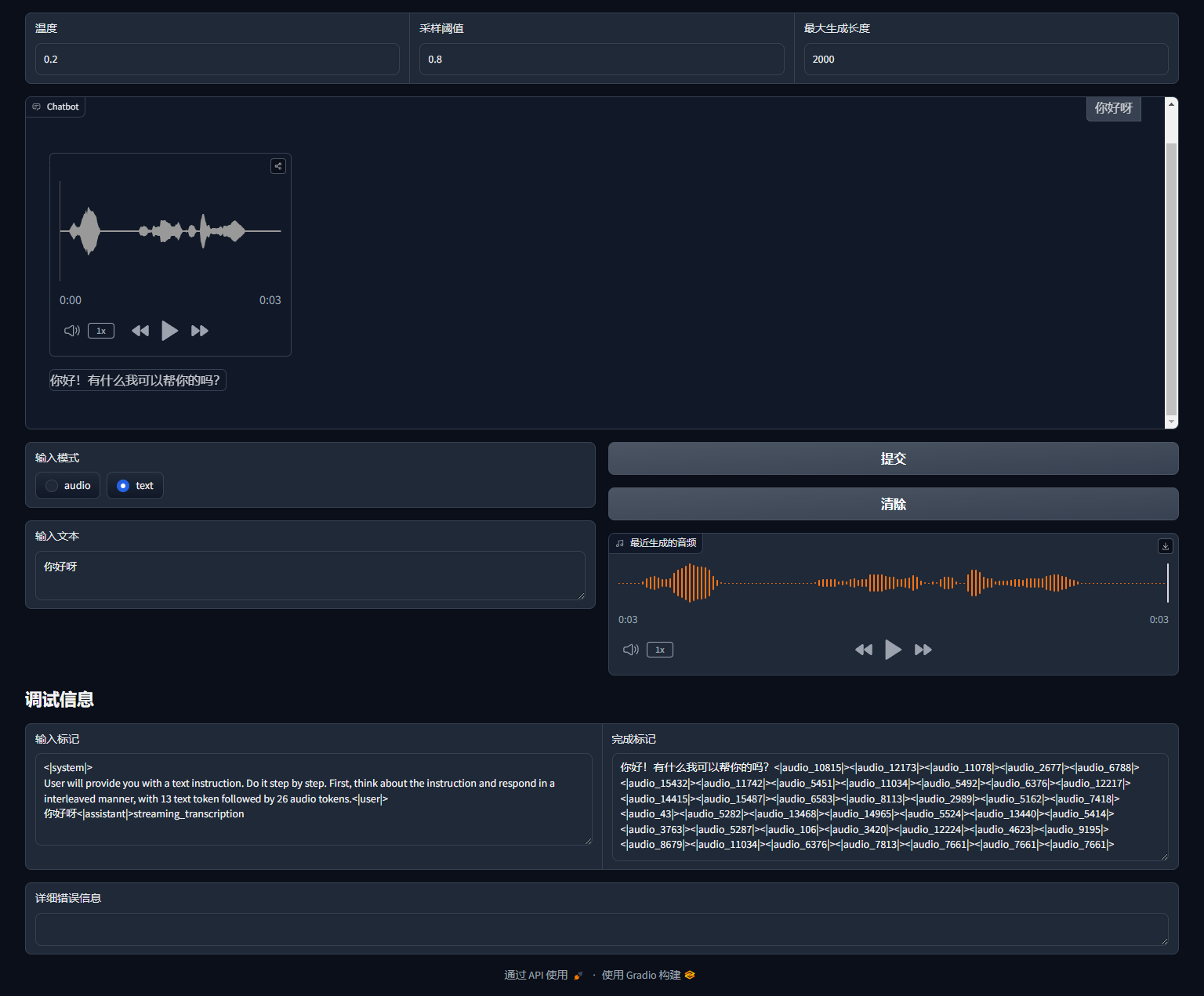
成功生成,需要注意的是,生成时音频时流式传输,会一部分一部分的进行播放,全部生成完毕后会显示完整的音频。
本地部署中遇到的问题
这部分是自己部署时遇到的一些问题总结。如果你是用的整合包,可以忽略这部分内容。
ERROR: ERROR: Failed to build installable wheels for some pyproject.toml based projects (pynini)
这是由于pip编译pynini失败导致的。用conda安装
conda install -c conda-forge openfst
conda install -c conda-forge pynini==2.1.5默认gradio不显示音频问题
降低gradio版本
pip install gradio==4.44.1ModuleNotFoundError: No module named 'matcha.models'; 'matcha' is not a package
依赖文件中少写了matcha相关的
pip install matcha-tts端口号问题
/generate_stream (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fd6219fe680>: Failed to establish a new connection: [Errno 111] Connection refused'))
由于端口号该项目默认是固定的10000,我执行的时候会显示端口号被占用。
修改model_server.py脚本中的第111行
parser.add_argument("--port", type=int, default=8927)修改web_demo.py脚本中106行
with torch.no_grad():
response = requests.post(
"http://localhost:8927/generate_stream",
data=json.dumps({
"prompt": inputs,
"temperature": temperature,
"top_p": top_p,
"max_new_tokens": max_new_token,
}),
stream=True
)配置要求
windows GPU占用22G左右。还是非常吃配置的
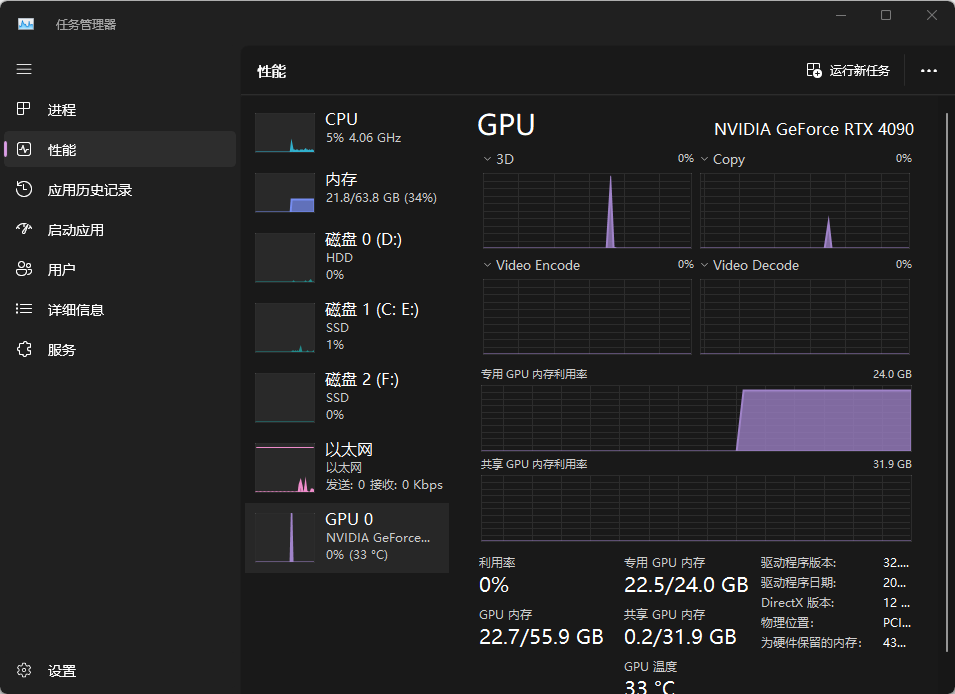
配置不够的朋友,可以用云端来体验下。
仙宫云体验
仙宫云 | GPU 算力租赁 | Xiangongyun.com
魔塔云端体验
整合包获取
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻
关注公众号,发送【GLM-4-Voice】关键字获取整合包。
如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!


















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









