







 超级会员免费看
超级会员免费看
文章目录
前言
清华智普的GLM-4v-9b模型,作为优化的多模态大模型,特别适用于国内应用场景,解决了国外模型本地化不足的问题。本专栏提供环境安装、数据处理、视觉与语言模型源码理解,并基于Hugging Face重构GLM模型搭建教程,帮助理解、修改和应用GLM墨西哥,指导搭建多模态大模型,帮助读者自由搭建与修改大模型。本节给出glm的环境安装、模型训练与推理。
第一节:GLM-4v-9B大模型安装、推理与训练详细教程
第二节:GLM-4v-9B数据加载源码解读
第三节:GLM-4v-9B数据加载之huggingface数据加载方法教程(通用大模型数据加载实列)
第四节:GLM-4v-9b模型的tokenizer源码解读
第五节:GLM-4v-9b模型model加载源码解读(模型相关参数方法解读)
第六节:GLM-4v-9b模型加载源码解读(模型加载方法解读)
第七节:GLM-4v-9b模型的视觉模型源码解读
第八节:GLM-4v-9b模型的大语言模型源码解读(ChatGLMForConditionalGeneration)
第九节:通过Debug解析ChatGLMForConditionalGeneration的数据流,理解GLM-4v-9b模型架构
第十节:通过Debug解析ChatGLMModel的数据流,理解视觉与语言模型结合架构
第十一节:利用huggingface重构GLM-4v-9B模型数据处理代码Demo
第十二节:利用huggingface重构GLM-4v-9B训练模型代码Demo
第十一、十二节是在理解GLM-4v-9B模型后,使用huggignface重新构建/搭建GLM-4v-9B模型,使读者能自由构建多模态大模型!
一、GLM-4-9B简介
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中, GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。我们还推出了支持 1M 上下文长度(约 200 万中文字符)的 GLM-4-9B-Chat-1M 模型和基于 GLM-4-9B 的多模态模型 GLM-4V-9B。GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
二、GLM-4-9B环境安装
环境安装官网也有给出,但我还是记录一下。我需强调一下,不要先安装torch版本再采用我下面方法安装,而是直接构建完虚拟环境后,直接采用我下面方法安装。
1、代码下载(github)
下载网址:https://github.com/THUDM/GLM-4

2、安装环境
1、虚拟环境构建
下载完代码后,直接通过命令安装,我安装python=3.10,举例如下:
conda create -n glm python=3.10
2、基本环境安装
直接cd到代码位置:GLM-4V-9B/GLM-4-main/basic_demo,然后使用命令安装:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
最后后面跟个pip源,这样会更快,如 -i https://pypi.tuna.tsinghua.edu.cn/simple/。
而 requirements.txt环境包含如下:
torch>=2.4.0
torchvision>=0.19.0
transformers>=4.45.0
huggingface-hub>=0.25.1
sentencepiece>=0.2.0
jinja2>=3.1.4
pydantic>=2.9.2
timm>=1.0.9
tiktoken>=0.7.0
numpy==1.26.4 # Need less than 2.0.0
accelerate>=0.34.0
sentence_transformers>=3.1.1
gradio>=4.44.1 # web demo
openai>=1.51.0 # openai demo
einops>=0.8.0
pillow>=10.4.0
sse-starlette>=2.1.3
bitsandbytes>=0.43.3 # INT4 Loading
# vllm>=0.6.2 # using with VLLM Framework
# flash-attn>=2.6.3 # using with flash-attention 2
# PEFT model, not need if you don't use PEFT finetune model.
# peft>=0.13.0 # Using with finetune model
这样你就基本安装好所需要环境了,不建议独自安装torch在安装这些环境,运气不好情况会直接不能运行。
3、finetune环境安装
和上面方法一样,直接cd到GLM-4-main/finetune_demo文件,使用
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
而requirements.txt包含内容如下:
jieba==0.42.1
datasets==2.20.0
peft==0.12.0
deepspeed==0.14.4
nltk==3.8.1
rouge_chinese==1.0.3
ruamel.yaml==0.18.6
这样,你就安装了finetune训练环境。我需要强调下peft官网给的0.12.2而使用源并没有找到,我改成了0.12.0版本。

三、GLM-4-9B模型训练与推理
1、GLM-4-9B权重下载
网址依然是:https://github.com/THUDM/GLM-4
进入官网点击图像的符号下载即可:
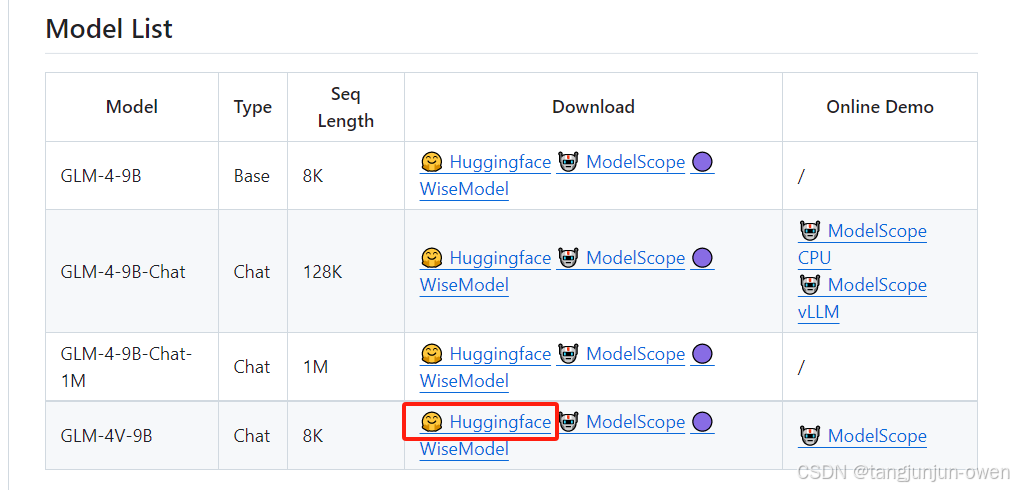
我也给了huggingface直达地址:https://huggingface.co/THUDM/glm-4v-9b
2、GLM-4-9B模型推理
1、原始模型推理
下载完后,直接使用下面代码可实现推理,基本也不会报错,如下:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 设置 GPU 编号,如果单机单卡指定一个,单机多卡指定多个 GPU 编号
MODEL_PATH = "THUDM/glm-4-9b-chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
device_map="auto"
).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
推理结果如图显示:

2、lora权重推理
如果你训练了模型,使用lora训练,那么我们可以直接使用lora权重+原始权重进行推理,实际使用PEFT加载这句代码即可实现,如下:
from peft import PeftModel
# 使用PEFT加载LoRA权重
model = PeftModel.from_pretrained(model, LORA_WEIGHTS_PATH, torch_dtype=torch.bfloat16)
而整个推理代码如下:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 设置 GPU 编号,如果单机单卡指定一个,单机多卡指定多个 GPU 编号
MODEL_PATH = "/GLM-4V-9B/GLM-4-main/THUDM/glm-4v-9b"
IMAGE_PATH = "/GLM-4V-9B/GLM-4-main/THUDM/data/glm_hncy/images/train/1707220435792.jpg"
LORA_WEIGHTS_PATH = "/GLM-4V-9B/GLM-4-main/output/checkpoint-1000"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
query = '描述图片中城市管理方面的问题?'
image = Image.open(IMAGE_PATH).convert('RGB')
inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}],
add_generation_prompt=True, tokenize=True, return_tensors="pt",
return_dict=True) # chat mode
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
device_map="auto"
).eval()
from peft import PeftModel
# 使用PEFT加载LoRA权重
model = PeftModel.from_pretrained(model, LORA_WEIGHTS_PATH, torch_dtype=torch.bfloat16)
gen_kwargs = {"max_length": 120, "do_sample": True, "top_k": 1}
# gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))
3、多轮对话推理添加内容:2024-12-25
和上面类似,多轮对话思路是,把前面n-1轮模型输出内容叠加到prompt上,和后面说的训练数据格式类似,我不在过多解读,直接给出代码:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1' # 设置 GPU 编号,如果单机单卡指定一个,单机多卡指定多个 GPU 编号
MODEL_PATH = "/GLM-4V-9B/GLM-4-main/THUDM/glm-4v-9b"
IMAGE_PATH = "/train_images/005c778c-90c0-4149-9d4e-49d1a8c4e37f.jpg"
LORA_WEIGHTS_PATH = "/GLM-4V-9B/GLM-4-main/output/train_hf/checkpoint-3000"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
query_multi = ['请指出管理问题标签。','简短回答']
image = Image.open(IMAGE_PATH).convert('RGB')
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
device_map="auto"
).eval()
from peft import PeftModel
# # 使用PEFT加载LoRA权重
model = PeftModel.from_pretrained(model, LORA_WEIGHTS_PATH, torch_dtype=torch.bfloat16)
# 这个循环是多轮对话循环。
for i,query in enumerate(query_multi):
if i==0:
prompt = query
else:
prompt = prompt+"<|assistant|>"+tokenizer.decode(outputs[0]).replace("<|endoftext|>","")+"<|user|>"+ "\n"+query
inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": prompt}],
add_generation_prompt=True, tokenize=True, return_tensors="pt",
return_dict=True) # chat mode
inputs = inputs.to(device)
# "<|assistant|>" "<|user|>" "\n"
gen_kwargs = {"max_length": 300, "do_sample": True, "top_k": 1}
# gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
results = model.generate(**inputs, **gen_kwargs)
outputs = results[:, inputs['input_ids'].shape[1]:]
outputs_print = tokenizer.decode(outputs[0]).replace("<|endoftext|>","")
print("第{}轮提问回答:{}\n".format(i+1,outputs_print))
3、GLM-4-9B模型训练
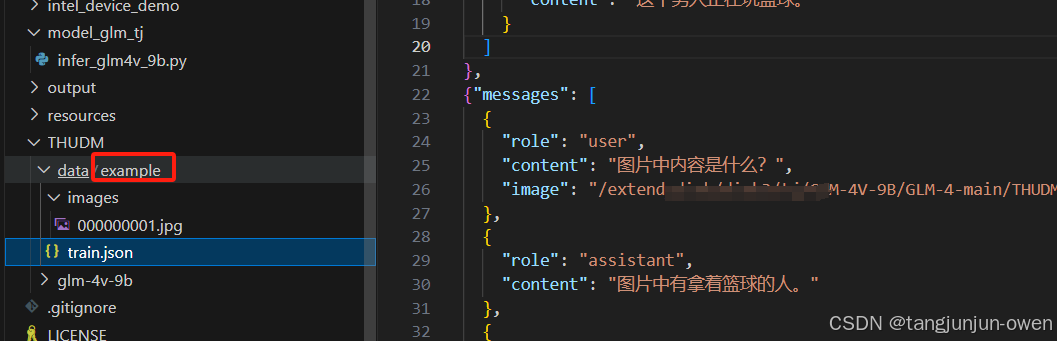
1、数据制作
直接参考官网:https://github.com/THUDM/GLM-4/blob/main/finetune_demo/README.md
如下图显示:

我制作数据如下:
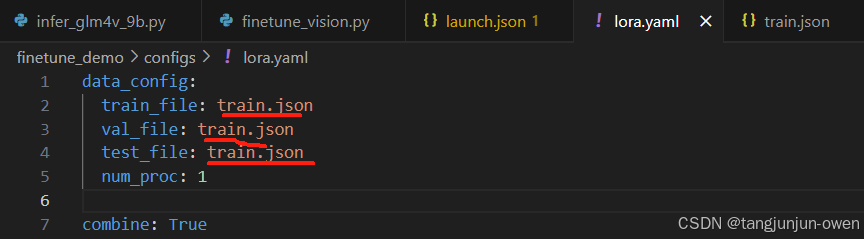
当然,我们需要给数据路径,直接在lora.yaml中修改,如下:
2、sh命令训练
然后使用cd进入/finetune_demo文件,使用如下命令训练即可:
OMP_NUM_THREADS=1 torchrun --standalone --nnodes=1 --nproc_per_node=1 finetune_vision.py /extend_disk/disk3/tj/GLM-4V-9B/GLM-4-main/THUDM/data/example /extend_disk/disk3/tj/GLM-4V-9B/GLM-4-main/THUDM/glm-4v-9b configs/lora.yaml
3、使用vscode方法训练
这个方法主要是为了debug方便,如果只是训练就不需要使用该方法,其配置文件如下:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python Debugger: Current File",
"type": "debugpy",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal"
},
{
"name": "run_finetune_vision",
"type": "python",
"request": "launch",
"program": "/home/anaconda3/envs/glm/bin/torchrun",
"console": "integratedTerminal",
"justMyCode": false,
"args": [
"--standalone",
"--nnodes","1",
"--nproc_per_node","1",
"/GLM-4V-9B/GLM-4-main/finetune_demo/finetune_vision.py",
"/GLM-4V-9B/GLM-4-main/THUDM/data/example",
"/GLM-4V-9B/GLM-4-main/THUDM/glm-4v-9b",
"/GLM-4V-9B/GLM-4-main/finetune_demo/configs/lora.yaml"
],
}
]
}
4、训练结果显示
给出训练成功显示,如下图:


















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











