







GPT-SoVITS是一款创新的声音克隆工具,它在很短的时间内就能克隆出别人的声音,并且所需的素材量极少。与此前的SoVITS相比,GPT-SoVITS只需要1分钟的音源就可以实现高质量的声音克隆,而原先的SoVITS则需要半个小时以上的干声音。

功能亮点:
- 零次TTS: 用户仅需输入一段5秒的语音样本,GPT-SoVITS-WebUI就能立即将其转换为文本,实现即时的语音到文本转换。
- 少次TTS: 通过对模型进行微调,即使是1分钟的训练数据也能显著提升语音的相似度和真实感,这对个性化语音合成非常关键。
- 跨语言支持: GPT-SoVITS-WebUI能够处理与训练数据集不同语言的语音,目前支持英语、日语和中文,大大拓宽了应用范围。
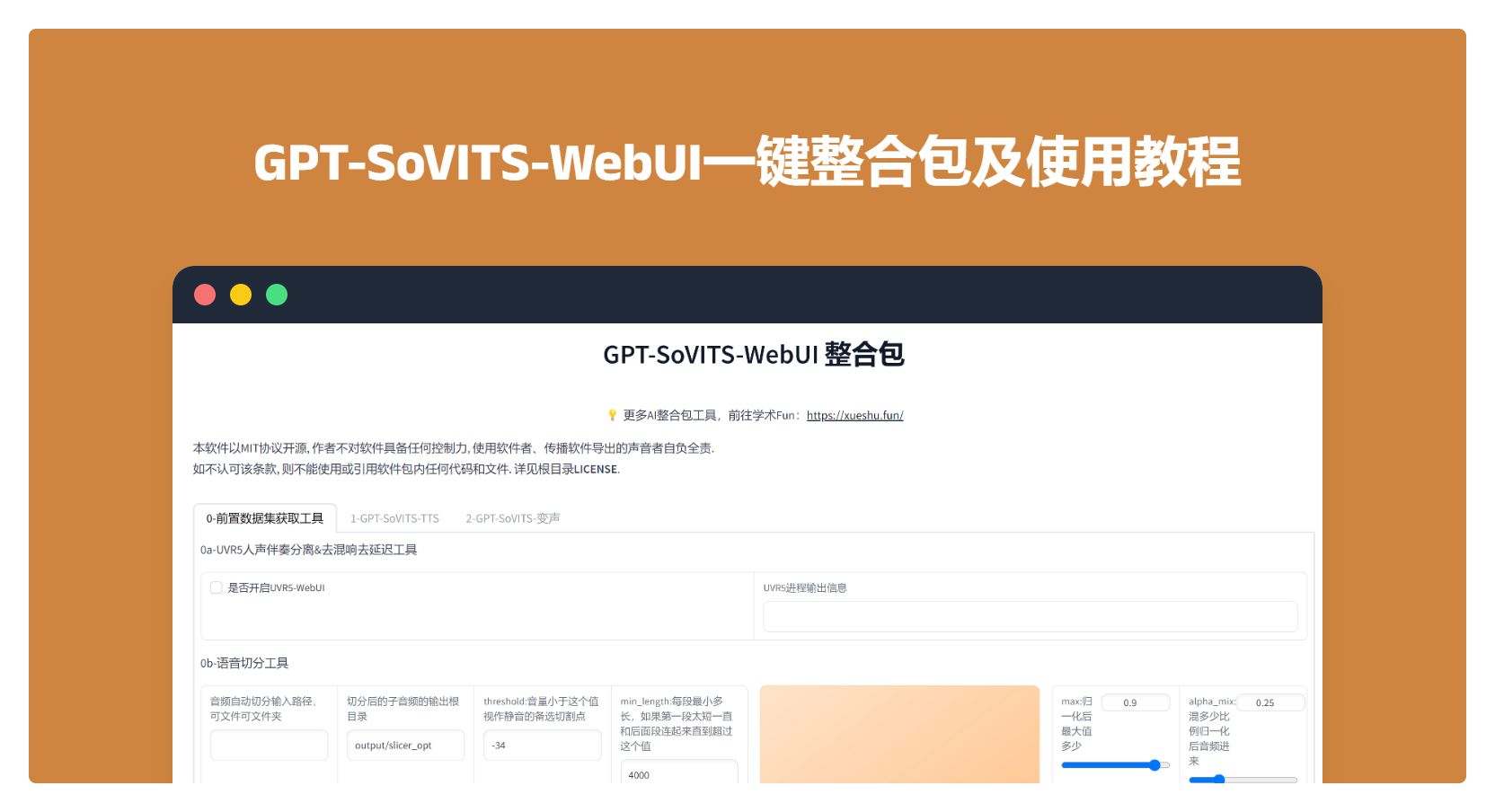
- WebUI集成: 集成了多种AI工具,包括语音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,方便用户创建训练数据集和GPT/SoVITS模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











