






目录
源码下载:
https://github.com/1578630119/Logisitic_Regression
代码和数据集都有。
用Logistic回归进行分类的主要思想:根据现有数据对分类边界线建立回归公式,以此进行分类。
一、Logistic回归和Sigmoid函数
Logistic回归
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度不高。
适用数据类型:数值型和标称型数据。
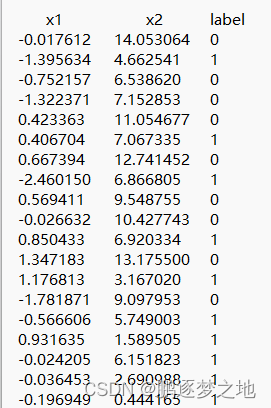
如上第一张表格所示,每一行为一个样本,每个样本有三个数据,前两个数据为该样本的特征值,后一个数据label为样本的类别。
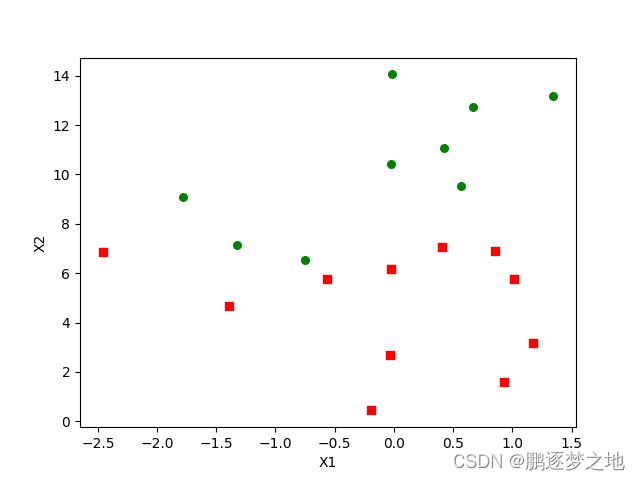
在第二张图像是第一张表格的二维象限图,横坐标纵坐标分别代表,绿色圆点代表label为0的样本,红色方框代表label为1的样本。我们需要找到一条分界线线划分两个类别,这条直线的一侧为一类,另一侧为另外一类。通过已有的数据集得到这条分界线后,当后续样本只有
特征,在不知道具体的label时,通过这条分界线就可以轻松得出它的label值。
假设分界线线的公式为:
其中为特征值,
为参数,而我们的目标是利用第一张表格中已有数据集,得到最佳参数
,
Sigmoid函数:
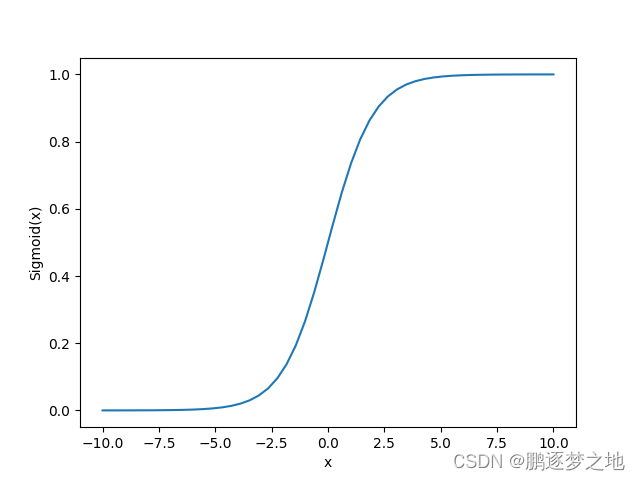
Sigmoid函数作用:回归最终的到z可能为正、为负,不同的结果值的大小差距很大。利用Sigmoid函数可以将所有的值收缩到0~1之间,在最终分类的时候,将高于或等于0.5的结果设为一类,低于0.5的结果设置为另一类。
二、基于最优化方法的最佳回归系数确定
回归公式可以写为:
1.梯度上升法
梯度上升法基于的思想是:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为。则函数f(x,y)的梯度由下式表示:
就是在高数中的偏导数,这个梯度意味着要沿着x的方向移动,沿着y的方向移动
,其中函数f(x,y)必须要在待计算的点上有定义并且可微。
梯度上升算法沿梯度方向移动了一步。可以看到,梯度算子总是指向函数值增长最快的方向。这里所说的是移动方向,而未提到移动量的大小。该量值称为步长,记做α。用向量来表示的话,梯度算法的迭代公式如下:
该公式将一直被迭代执行,直至达到某个停止条件为止,比如迭代次数达到某个指定值或算法达到某个可以允许的误差范围。
注:如果就这样看书本上的这些文字还是很难理解的,需要通过下面的代码和解释进行理解Logistics回归的原理。
2.训练算法:使用梯度上升找到最佳参数
注:对应代码文件为logRegres.py。数据集对应文件为Dataset/testSet.txt。
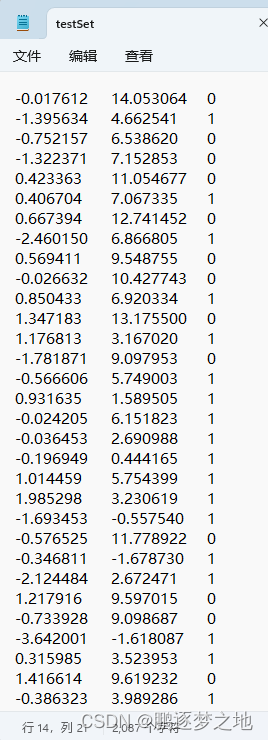
用到的数据集格式如上所示(Dataset/testSet.txt),每一行为一个样本,每行的第一个和第二个数据代表样本的特征值(X1和X2),最后一个数据代表样本的类别,总共100行。
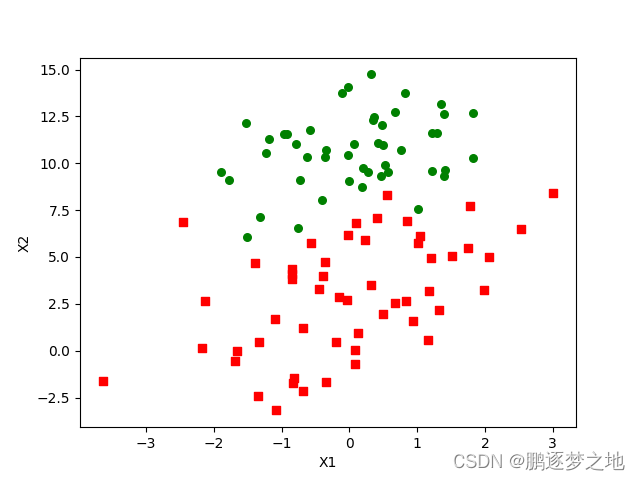
将txt文本中的100个样本其在二维象限中展示图如上,红色方框代表类别为1的样本,绿色圆点代表类别为0的样本。
梯度上升的伪代码如下(可以对比后续的实际代码更容易理解):
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha ✖ gradient更新回归系数
返回回归系数
def load_Dataset():
#load_Dataset是为了将testSet.txt文本中的数据提取出来,并进行预处理
data_Mat = []
label_Mat = []
with open('Dataset/testSet.txt', 'r') as f:
for line in f.readlines():
line_Arr = line.strip().split()
data_Mat.append([1.0, float(line_Arr[0]), float(line_Arr[1])])
#将数据集中第一二列中的特征值放在data_Mat中,每一行都添加参数1.0,是将w0x0设置为常数w0
label_Mat.append(int(line_Arr[2])) #将数据集中最后一列中的标签放在label_Mat中
return data_Mat, label_Mat
def sigmoid(z):
#sigmodi函数 将得到的值收缩在0~1之间,方便与实际标签计算
return 1.0 / (1 + np.exp(-z))
def grad_ascent(data_mat_in, class_labels):
#梯度上升法
data_matrix = np.mat(data_mat_in)
label_mat = np.mat(class_labels).transpose() #将得到的特征和标签转换为Numpy矩阵数据类型
m, n = np.shape(data_matrix) #获得特征矩阵的形状,m(m=100)行,n(n=3)列
alpha = 0.001 #更新梯度的步长
max_cycles = 500 #迭代次数
weights = np.ones((n, 1)) #w0,w1,w2初始赋值为1.0
for k in range(max_cycles):
h = sigmoid(data_matrix * weights)
#得到特征x0,x1,x2和参数w0,w1,w2相乘后,用sigmoid处理后的值
error = (label_mat - h) #计算label矩阵和预测值矩阵的差
weights = weights + alpha * data_matrix.transpose() * error
#用得到的error和特征矩阵和alpha参数相乘结果作为w0,w1,w2的更新幅度
return weights针对于这个数据集,在代码中对应函数为:
在代码的特征矩阵(data_matrix)中第二列和第三列对应x1和x2,同时也对应着testSet.txt文本中第一二列,而在特征矩阵(data_matrix)中第一列的值全是1,x0的值固定位1,则实际对应的函数应该为
相当于我们在高中大学学习的函数,这样就是w0相当于c,w0作为一个常数参数,w1,w2相当于系数。
如果大家想要更好地理解,建议手动写一次以上代码,同时在def grad_ascent(data_mat_in, class_labels)函数中将h,error,weights用print输出看一下它们的形状结构。
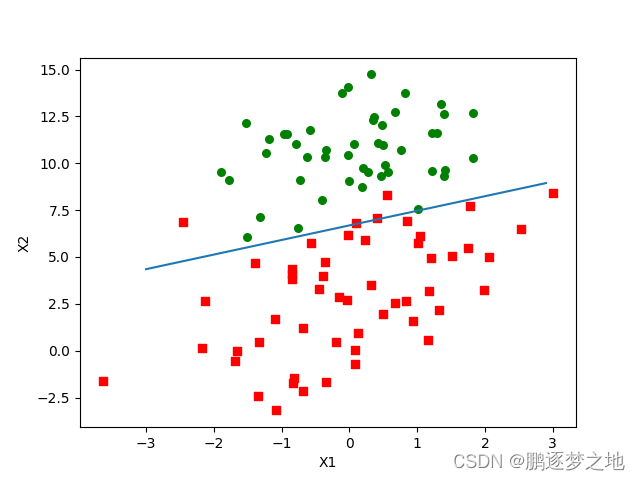
最终结果图展示如下:
3.训练算法:随机梯度上升
梯度上升算法中,每次更新回归系数时会一次性计算整个数据集,现在用的只是100个样本的数据集,一次性进行矩阵运算尚可,当以后遇到成千上万的数据集如果在一次将所有的数据进行运算,可能对硬件要求就太高了。一种改进方法是每次用一个或者一部分样本进行运算更新回归系数,这种方法称为随机梯度上升算法。一次处理的所有数据被称作是“批处理”。
以下是随机梯度上升算法的实现代码。
def stoc_grad_ascent0(data_matrix, class_labels):
#随机梯度上升法
m, n = np.shape(data_matrix)
alpha = 0.01
weights = np.ones(n)
#用数据集的每个样本单独更新一次weights,总共更新100次
for i in range(m):
h = sigmoid(np.sum(data_matrix[i] * weights)) #每次取出一个样本计算
error = class_labels[i] - h
weights = weights + alpha * error * np.array(data_matrix[i])
return weights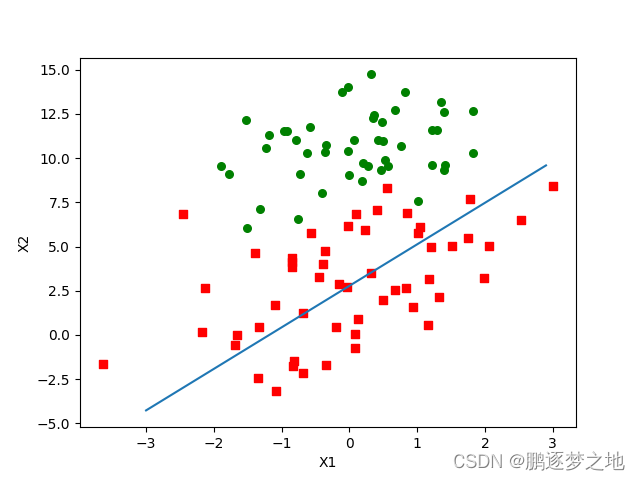
由代码可以看见,随机梯度上升法,每次用一个样本计算更新weights,总共更新weights次数为样本总数(100)次,仅仅遍历了一次数据集,相对于梯度上升法运行500次(遍历了500次数据集)最终的结果较差。针对这种情况需要加大随机梯度上升法的迭代次数。同时为改变在系数收敛较稳定的时候更新幅度过大,步长alpha在每次迭代时候会进行调整,在迭代初期步长较大,随着迭代次数逐渐减小,最终使weights收敛到更好。
def stoc_grad_ascent1(data_matrix, class_labels, num_iter=150):
m, n = np.shape(data_matrix)
weights = np.ones(n)
for j in range(num_iter):
data_index = list(range(m))
for i in range(m):
alpha = 4 / (1.0 + j + i) + 0.01 #每次迭代更新alpha
rand_index = int(random.uniform(0, len(data_index)))
# 随机选择更新,减少周期性的波动
h = sigmoid(np.sum(data_matrix[rand_index] * weights))
error = class_labels[rand_index] - h
weights = weights + alpha * error * np.array(data_matrix[rand_index])
del(data_index[rand_index]) #删除已经使用过的样本
return weights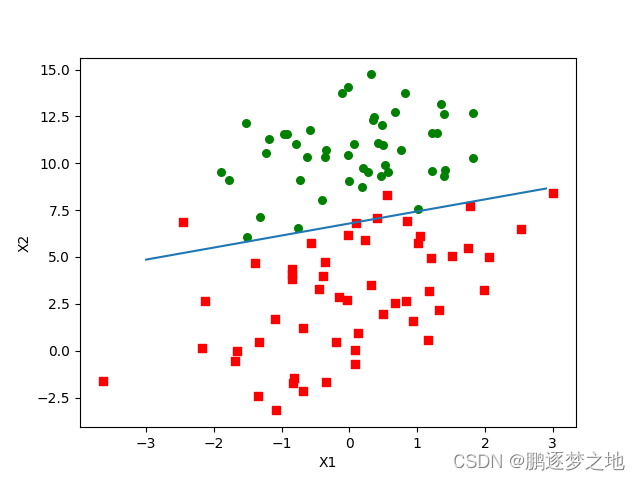
在代码中不仅增加了迭代次数,alpha更新机制,还增加了随机选择样本,即每次迭代时,样本都是随机选择来更新系数weights。最终得到的结果如函数图像所示,分类效果更好,而且这种方法只需要遍历数据集150次。
三、示例:从疝气病症预测兵马的死亡率
本节将使用Logistic回归来预测患有疝气病的马的存活问题。这里数据包含368个样本和28个特征。
示例:使用Logisitic回归估计马疝病的死亡率
- (1)收集数据:给定数据文件。
- (2)准备数据:用Python解析文本文件并填充缺失值。
- (3)分析数据:可视化并观察数据。
- (4)训练算法:使用优化算法,找到最佳的系数
- (5)测试算法:为了量化回归的效果,需要观察错误率。根据错误率决定是否回退到训练阶段,通过改变迭代的次数和步长等参数来得到更好的回归参数。
- (6)使用算法:实现一个简单的命令行程序来收集马的症状并输出预测结果1并非难事,这可以作为留给读者的一道习题。
1.准备数据:处理数据集中的缺失值
在数据中有缺失值是很棘手的问题,缺失的样本在代码中无法直接运算,因系数不可能和空白相乘得到一个结果,所以必须采用一些方法来解决这个问题。
以下是一些可选的做法
- 使用可用特征的均值来填补缺失值
- 使用特殊值来填补缺失值,如-1;
- 忽略有缺失值的样本
- 使用相似样本的均值添补缺失值;
- 使用另外的机器学习算法预测缺失值。
针对于本节使用的马的疝气病数据集,所有缺失值使用实数0来进行替换。
回归系数的更新公式如下:
weights = weights + alpha * data_matrix* error
当data_matrix中的某特征(i)因缺失而设置为0,alpha * data_matrix[i]* error结果也为0,对应的系数weights(i)不变。
针对于标签缺失的样本只能丢弃,标签丢失和特征值丢失不同,标签是很难用某个合适的值来替换。同时将标签为“已经死亡”和“已经安乐死”和并为“未能存活”,最终处理好的数据集保存为两个文件:horseColicTest.txt和ihorseColicTraining.txt。
2 测试算法:用Logistics回归进行分类
代码如下:
def colic_test():
fr_train = open('Dataset/horseColicTraining.txt')
fr_test = open('Dataset/horseColicTest.txt')
training_set = []
training_labels = []
for line in fr_train.readlines():
curr_line = line.strip().split('\t')
line_arr = []
for i in range(21):
line_arr.append(float(curr_line[i])) #将训练集的所有特征值保存在training_set中
training_set.append(line_arr) #最后一列的标签保存在training_labels
training_labels.append(float(curr_line[21]))
train_weights = stoc_grad_ascent1(np.array(training_set), training_labels, 500)
#调用随机上升梯度法,根据训练集得到各个参数weights的值
error_count = 0
num_test_vec = 0.0
for line in fr_test.readlines():
num_test_vec += 1.0
curr_line = line.strip().split('\t')
line_arr = []
for i in range(21):
line_arr.append(float(curr_line[i])) #取出测试集的所有信息保存在line_arr
if int(classify_vector(np.array(line_arr), train_weights)) != int(curr_line[21]):
#使用得到的参数weights与测试样本的特征相乘得到预测结果,预测结果和实际标签相比较
error_count += 1 #统计预测错误数目
error_rate = float(error_count) / num_test_vec #计算错误率
print(f"the error rate of this test is {error_rate}")
return error_rate
def multi_test():
num_tests = 10
error_sum = 0.0
for k in range(num_tests):
error_sum += colic_test()
#平均num_tests次预测结果的错误率
print(f"after {num_tests} iterations the average error rate is {error_sum/float(num_tests)}")
由测试结果看来错误率达到30%多,但针对于这个有缺失值的数据集,这个结果已很不错了。
完成代码如下:
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import random
matplotlib.use('TkAgg')
def load_Dataset():
#load_Dataset是为了将testSet.txt文本中的数据提取出来,并进行预处理
data_Mat = []
label_Mat = []
with open('Dataset/testSet.txt', 'r') as f:
for line in f.readlines():
line_Arr = line.strip().split()
data_Mat.append([1.0, float(line_Arr[0]), float(line_Arr[1])])
#将数据集中第一二列中的特征值放在data_Mat中,每一行都添加参数1.0,是将w0x0设置为常数w0
label_Mat.append(int(line_Arr[2])) #将数据集中第一二列中的特征值放在label_Mat中
return data_Mat, label_Mat
def sigmoid(z):
#sigmodi函数 将得到的值收缩在0~1之间,方便与实际标签计算
return 1.0 / (1 + np.exp(-z))
def grad_ascent(data_mat_in, class_labels):
#梯度上升法
data_matrix = np.mat(data_mat_in)
label_mat = np.mat(class_labels).transpose() #将得到的特征和标签转换为Numpy矩阵数据类型
m, n = np.shape(data_matrix) #获得特征矩阵的形状,m(m=100)行,n(n=3)列
alpha = 0.001 #更新梯度的步长
max_cycles = 500 #迭代次数
weights = np.ones((n, 1)) #w0,w1,w2初始赋值为1.0
for k in range(max_cycles):
h = sigmoid(data_matrix * weights) #得到特征x0,x1,x2和参数w0,w1,w2相乘后,用sigmoid处理后的值
error = (label_mat - h) #计算label矩阵和预测值矩阵的差
weights = weights + alpha * data_matrix.transpose() * error
#用得到的error和特征矩阵和alpha参数相乘结果作为w0,w1,w2的更新幅度
return weights
def plot_best_fit(weights):
data_mat, label_mat = load_Dataset()
data_arr = np.array(data_mat)
n = np.shape(data_arr)[0]
xcord1 = []
ycord1 = []
xcord2 = []
ycord2 = []
for i in range(n):
if int(label_mat[i]) == 1:
xcord1.append(data_arr[i, 1])
ycord1.append(data_arr[i, 2])
else:
xcord2.append(data_arr[i, 1])
ycord2.append(data_arr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
# 最佳拟合直线
x = np.arange(-3.0, 3.0, 0.1)
print(weights)
y = (-weights[0] - weights[1] * x) / weights[2]
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
def stoc_grad_ascent0(data_matrix, class_labels):
#随机梯度上升法
m, n = np.shape(data_matrix)
alpha = 0.01
weights = np.ones(n)
#用数据集的每个样本单独更新一次weights,总共更新100次
for i in range(m):
h = sigmoid(np.sum(data_matrix[i] * weights)) #每次取出一个样本计算
error = class_labels[i] - h
weights = weights + alpha * error * np.array(data_matrix[i])
return weights
def stoc_grad_ascent1(data_matrix, class_labels, num_iter=150):
m, n = np.shape(data_matrix)
weights = np.ones(n)
for j in range(num_iter):
data_index = list(range(m))
for i in range(m):
alpha = 4 / (1.0 + j + i) + 0.01 #每次迭代更新alpha
rand_index = int(random.uniform(0, len(data_index))) # 随机选择更新,减少周期性的波动
h = sigmoid(np.sum(data_matrix[rand_index] * weights))
error = class_labels[rand_index] - h
weights = weights + alpha * error * np.array(data_matrix[rand_index])
del(data_index[rand_index]) #删除已经使用过的样本
return weights
def classify_vector(in_x, weights):
prob = sigmoid(np.sum(in_x * weights))
if prob > 0.5:
return 1.0
else:
return 0.0
def colic_test():
fr_train = open('Dataset/horseColicTraining.txt')
fr_test = open('Dataset/horseColicTest.txt')
training_set = []
training_labels = []
for line in fr_train.readlines():
curr_line = line.strip().split('\t')
line_arr = []
for i in range(21):
line_arr.append(float(curr_line[i])) #将训练集的所有特征值保存在training_set中
training_set.append(line_arr) #最后一列的标签保存在training_labels
training_labels.append(float(curr_line[21]))
train_weights = stoc_grad_ascent1(np.array(training_set), training_labels, 500)
#调用随机上升梯度法,根据训练集得到各个参数weights的值
error_count = 0
num_test_vec = 0.0
for line in fr_test.readlines():
num_test_vec += 1.0
curr_line = line.strip().split('\t')
line_arr = []
for i in range(21):
line_arr.append(float(curr_line[i])) #取出测试集的所有信息保存在line_arr
if int(classify_vector(np.array(line_arr), train_weights)) != int(curr_line[21]):
#使用得到的参数weights与测试样本的特征相乘得到预测结果,预测结果和实际标签相比较
error_count += 1 #统计预测错误数目
error_rate = float(error_count) / num_test_vec #计算错误率
print(f"the error rate of this test is {error_rate}")
return error_rate
def multi_test():
num_tests = 10
error_sum = 0.0
for k in range(num_tests):
error_sum += colic_test()
#平均num_tests次预测结果的错误率
print(f"after {num_tests} iterations the average error rate is {error_sum/float(num_tests)}")
if __name__ == "__main__":
# 1. 测试
data_arr, label_mat = load_Dataset()
result = stoc_grad_ascent1(data_arr, label_mat)
print(result)
plot_best_fit(result)
# 2. 从疝气病预测病马的死亡率
multi_test()















 1911
1911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









