 机器学习入门:逻辑回归与梯度下降法解析
机器学习入门:逻辑回归与梯度下降法解析








 这篇博客介绍了逻辑回归和梯度下降法在机器学习中的应用。逻辑回归是一种分类算法,通过最优化算法调整参数,常用梯度下降法优化模型。文章详细阐述了逻辑回归的代价函数和非凸性质,并用下山问题类比解释了梯度下降法的工作原理。此外,还讨论了评估模型性能的精度、精确率和召回率等指标。
这篇博客介绍了逻辑回归和梯度下降法在机器学习中的应用。逻辑回归是一种分类算法,通过最优化算法调整参数,常用梯度下降法优化模型。文章详细阐述了逻辑回归的代价函数和非凸性质,并用下山问题类比解释了梯度下降法的工作原理。此外,还讨论了评估模型性能的精度、精确率和召回率等指标。
机器学习中常用的导公式和迹公式

sigmoid函数
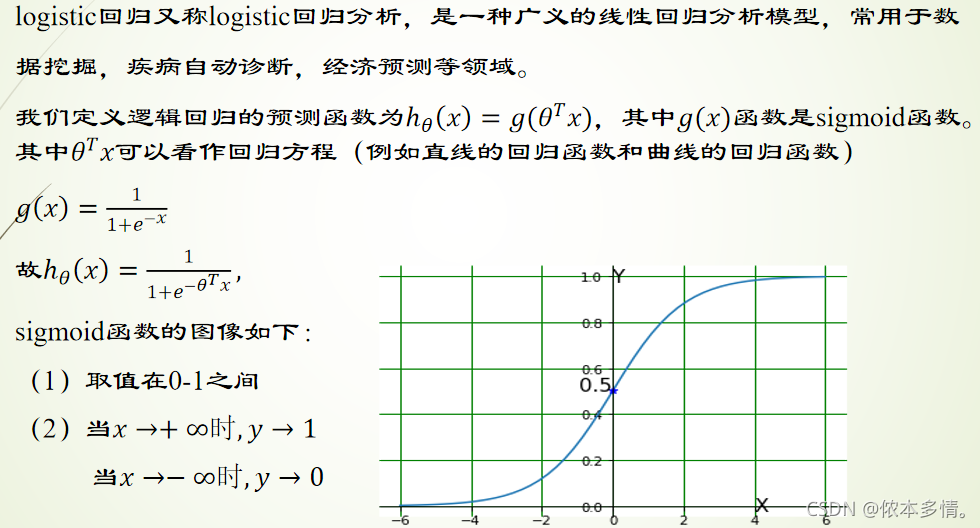
Sigmoid/Logistic Function:分类思想
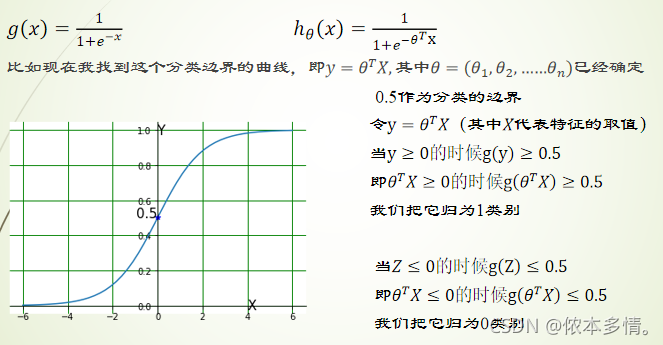
决策边界-线性
决策边界(decision boundary),所谓决策边界就是能够把样本正确分类的一条边界,主要有线性决策边界(linear decision boundaries)和非线性决策边界(non-linear decision boundaries)
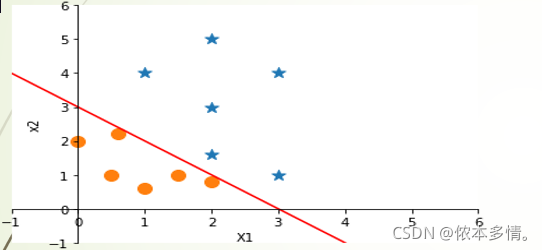

决策边界-非线性

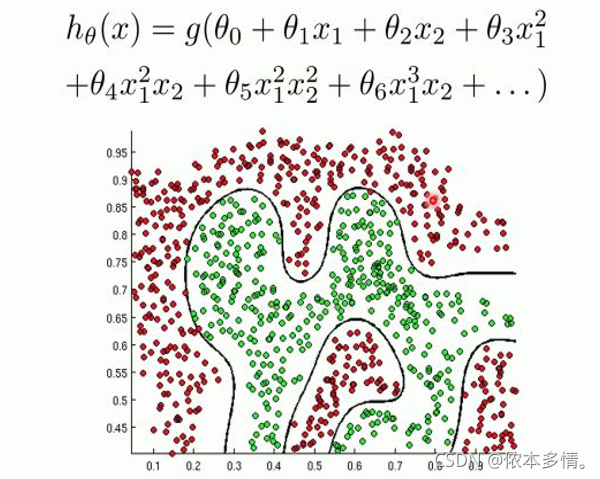
Logistic回归
logistict回归分类采用的是最优化算法.其做法就是通过迭代的方法不断调整θ=(θ1,θ2,……θn)的取值,从而求得使得代价函数最小的θ的取值。(注:这里的θ是我们提到ℎθ(x)=g(θ^T X) 的θ,即回归方程y=θ^T X 的参数)
其核心是利用梯度下降法(最速下降法)进行优化模型。梯度下降算法的步骤(梯度下降被广泛应用于像逻辑回归、线性回归和神经网络、深度学习的模型中)

逻辑回归的代价函数
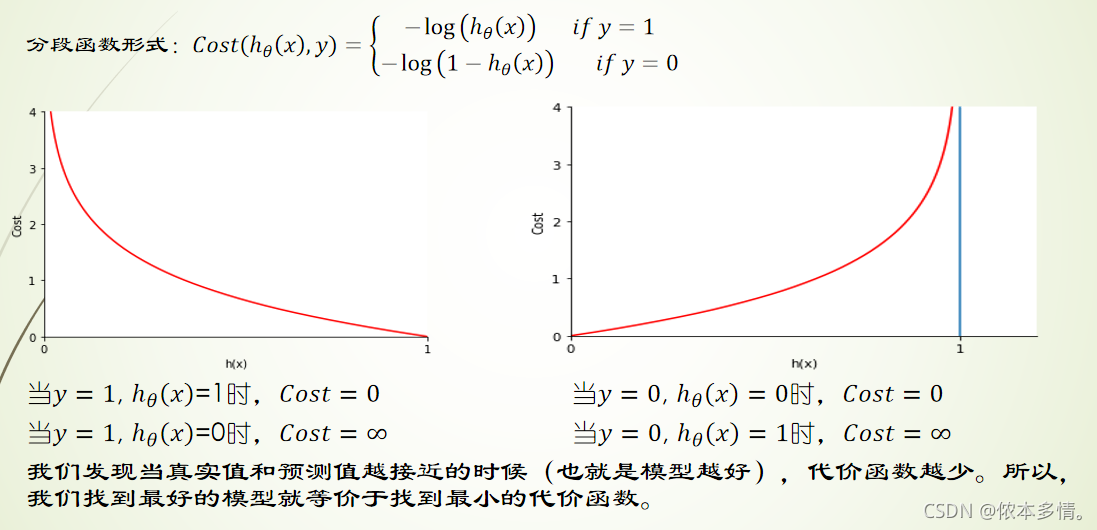
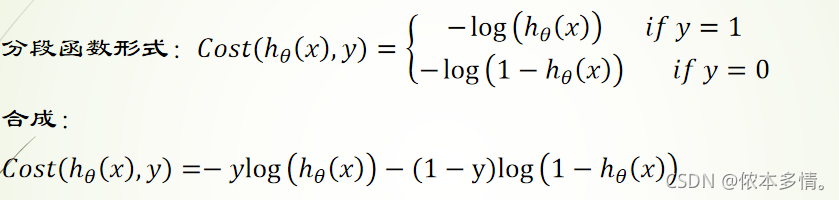
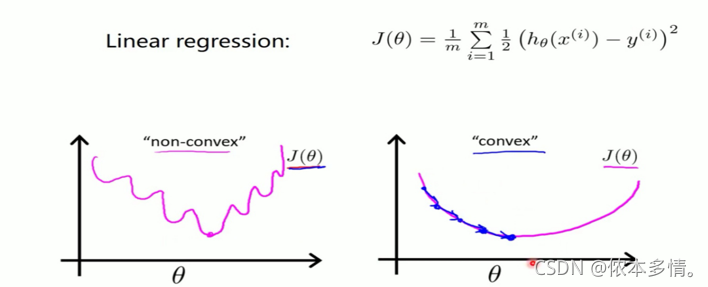
线性回归代价函数的实际意义就是平方误差。而逻辑回归却不是,它的预测函数ℎθ(x)是非线性的。如果类比地使用线性回归的代价函数于逻辑回归,那J(θ)很有可能就是非凸函数,即存在很多局部最优解,但不一定是全局最优解。我们希望构造一个凸函数,也就是一个碗型函数做为逻辑回归的代价函数。
梯度下降法-初识
一、概念
梯度下降法是一个最优化算法,它是沿梯度下降的方向求解极小值。
二、前提条件
1、目标函数(代价函数)
使用梯度下降法是要有前提条件,第一个就是要有目标函数。梯度下降法是求解最优解的算法没错,但是你要告诉梯度下降法是求的那个函数得最优解。
三、梯度的概念
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)
梯度有两点非常重要:(1)矢量(2)沿着梯度的方向,目标函数增加最快
我们采用的梯度下降法因为求的是目标函数的最小值,所以方向是该点梯度的反方向。
1 方向导数顾名思义,方向导数就是某个方向上的导数
比如下面的图示,在某一点处的方向导数其实是由很多(方向导数即该点处切线)
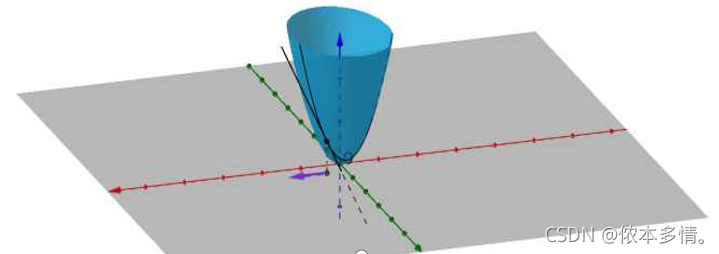
梯度:是一个矢量,其方向上的方向导数最大,其大小正好是此最大方向导数 。
梯度下降法-梯度如何求解
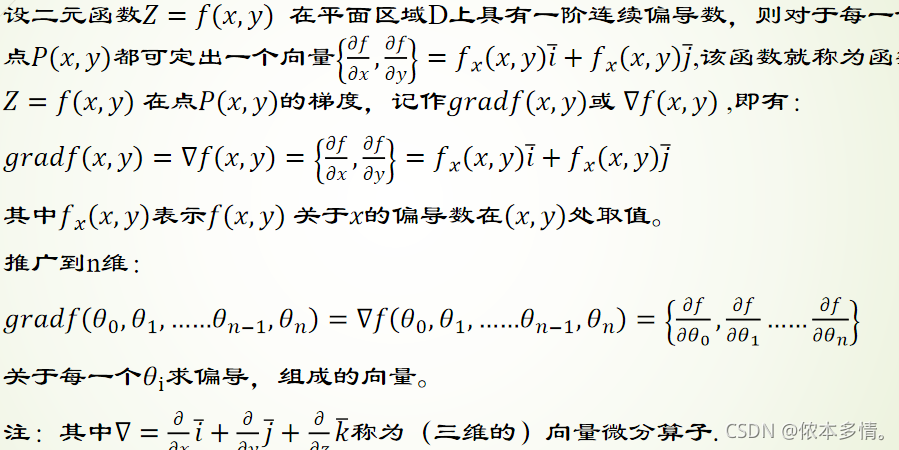
梯度下降法-形象理解
我们以”下山问题”进行类比,更直观的感受梯度下降法。比如现在我的代价函数只和两个参数有关θ_0,θ_1,我画如下的图形:
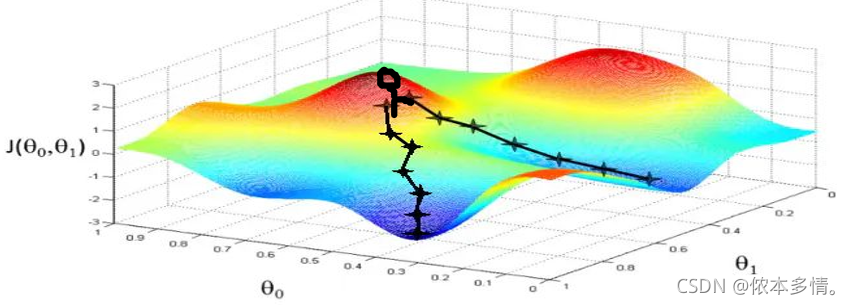
假设你站在山的某一处,你现在想以最快速度下山,那你肯定是找一条最陡峭的路走。你环顾四周,找到了一条路线,恩,这个方向是最陡的(梯度方向)。于是你就出发了,走了一会发现,这个方向不是最陡的路了。你就停下来,换了个最陡的方向,继续往下走。重复这个步骤,你最终到达了山脚下。
那么,你从山顶到山脚的整个下山的过程,就是梯度下降。
梯度下降法算法

逻辑回归-核心(求解梯度)
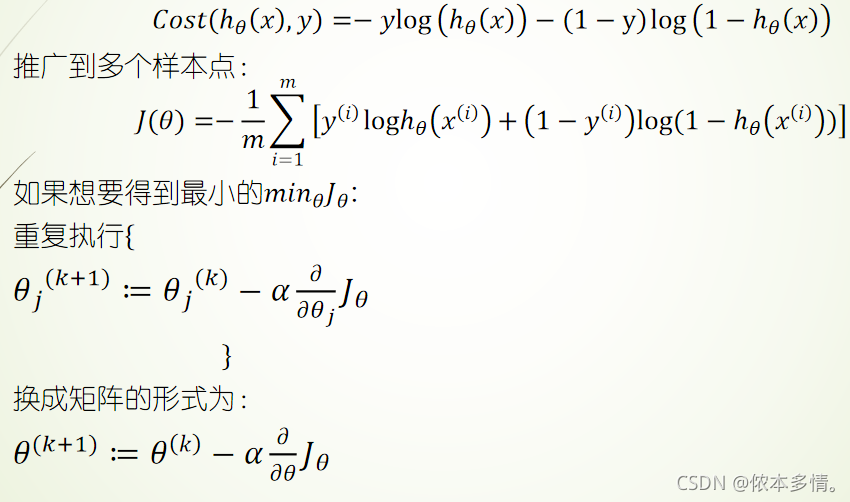
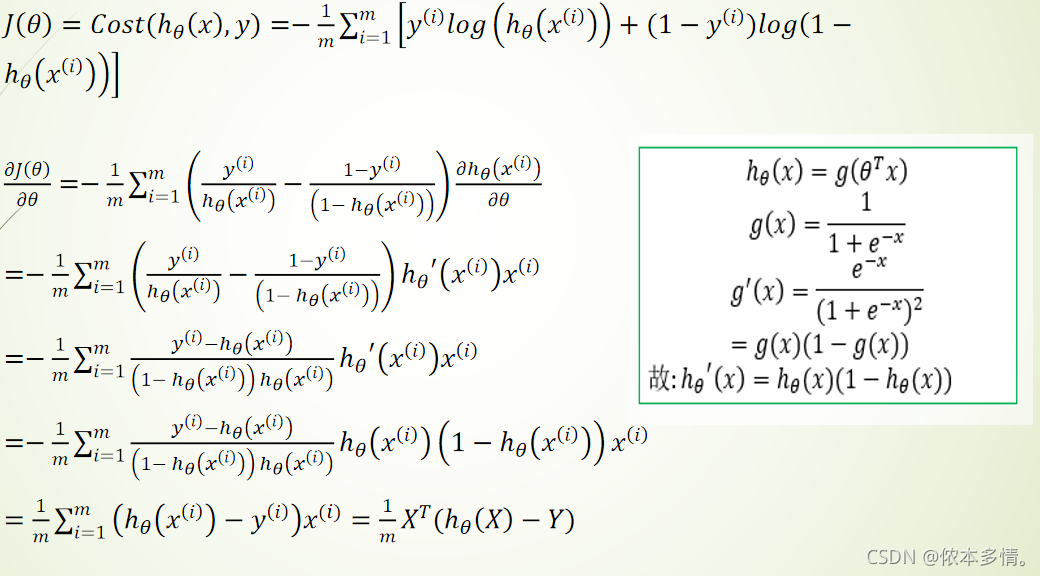
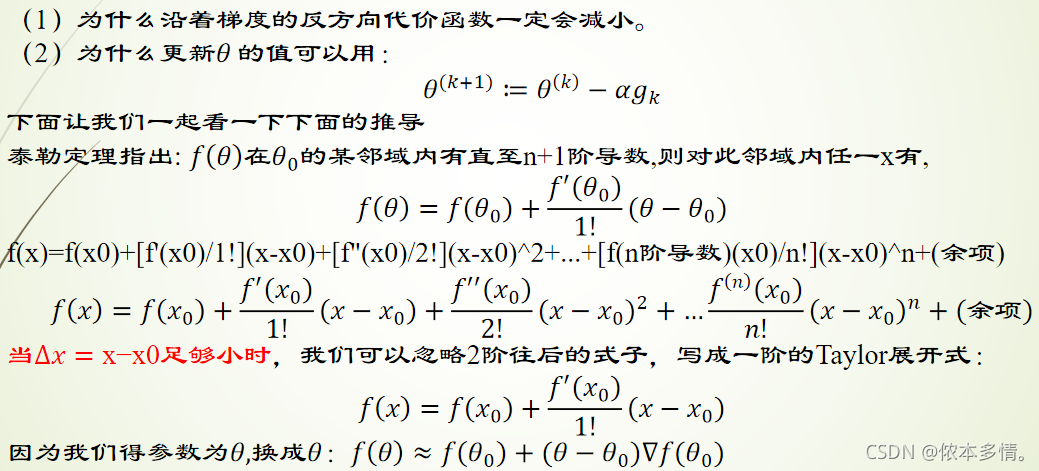

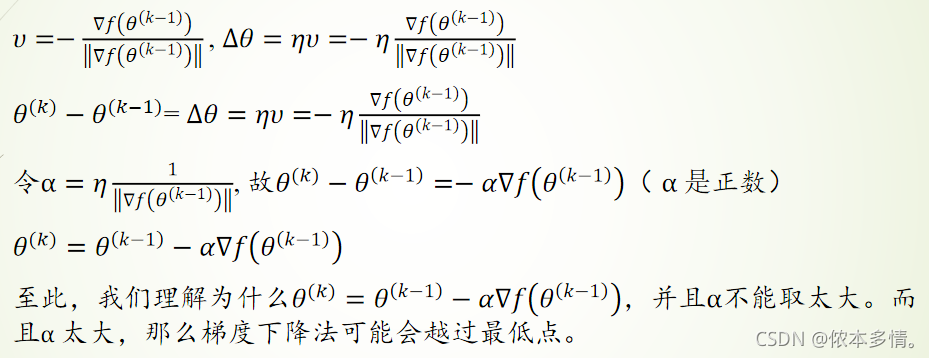
精度(正确率、准确率)accuracy = (TP+TN)/(TP+TN+FP+FN)
精确率precision = TP/(TP+FP)召回率recall = TP/(TP+FN)
精度比较好理解,就是预测准确的数占所有样本的比例,是最基本的指标;
精确率表示被预测为正例的样本中有多少是真正的正例。(查准率)
召回率表示所有正类的样本中有多少是被准确预测为正类(正例的样本被找回来了多少)。(查全率)
不准确的叫法:有些会把准确率(precision)和正确率( accuracy )


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











