






一、数据集
在深度学习中,数据集扮演着至关重要的角色。它们是训练机器学习模型的基础,决定了模型能够学习到的模式和特征。
数据集按应用场景分类:
- 图像数据集:用于计算机视觉任务,如图像分类、目标检测、图像分割等。
- 文本数据集:用于自然语言处理任务,如文本分类、情感分析、机器翻译等。
- 语音数据集:用于语音识别、语音合成等任务。
- 时序数据集:包含时间序列数据,如股票价格、天气数据等,常用于时间序列预测。
- 生物信息数据集:如基因数据、蛋白质数据等,用于生物信息学和计算生物学领域。
按数据标签类型分类:
- 分类标签:用于分类任务,表示样本所属的类别。
- 回归标签:用于回归任务,表示样本的连续值。
- 多标签:一个样本可以同时属于多个类别。
1.类与标签的说明
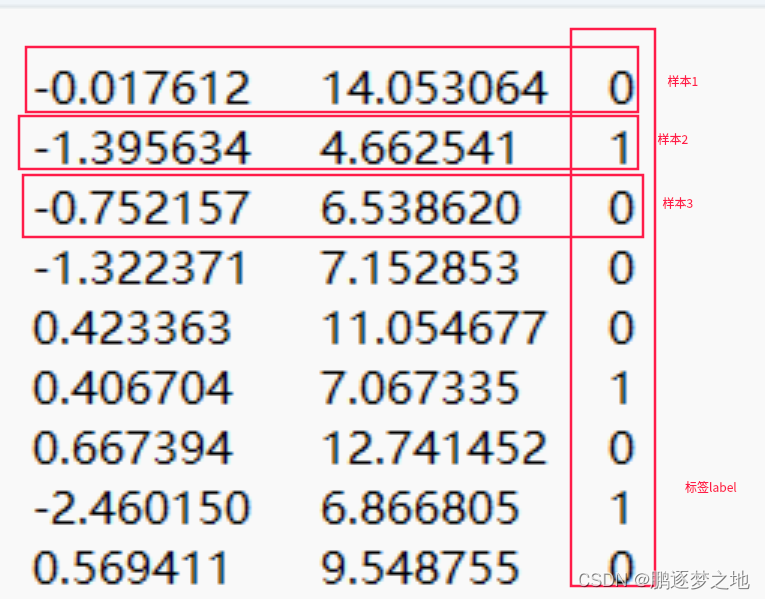
在这个文本数据集中,每一行就是一个样本,前面两列是样本的特征值,最后一列是该样本的标签(label),标签类型只有0或者1,说明该数据集只有两类。
2.数据集预处理
数据清洗:
- 处理缺失值:方法包括删除含有缺失值的样本、使用均值、中位数、众数等填补缺失值,或使用预测模型(如回归、决策树等)来预测并填补缺失值。如之前使用过的马的疝气病数据集(http://archive.ics.uci.eduAnWatasetsAiorse+Colic ),
- 处理异常值和离群点:通过统计方法识别并处理异常值,可能的方法包括删除、替换或采用平滑技术(如分箱操作、回归处理等)。如一些图像明显是某一个类别,但标签却是另外一类。
- 去除重复数据:检查并删除数据集中的重复记录。
数据加载:将数据集从文件中提取出来,并将非数字型特征或标签转换为数字,如猫狗分类,在每张图像对应的标签可能直接是英文Dog,Cat。在提取标签时会将其转为数字0或者1。再对数据进行标准化或者归一化,将原始的一列数据转换到某个范围,或者某种形态,加快模型的训练速度和模型性能。
3.数据集划分
通过将数据集划分为训练集和测试集(或验证集),我们可以在训练集上训练模型,并在独立的测试集上评估模型的性能。这样可以确保我们得到的模型性能评估结果是公正的,避免了由于使用相同数据同时训练和测试模型而导致的过拟合问题。
在监督学习中,数据集通常被分为以下三类
- 训练集(Train Set):
- 作用:主要用于模型训练,通过调整模型的参数来使得模型的输出尽可能接近训练数据集中的样本数据,即尽可能拟合训练样本数据集中的数据。
- 又称学习样本集,是用于调整当前模型的主要数据集。
- 验证集(Validation Set):
- 作用:用于判断模型的拟合程度,对实时学习的效果进行评估和考核,以决定是否需要进一步的学习和训练,同时决定是否需要调制超参数。
- 它帮助我们在不接触测试集的情况下,评估模型的性能,从而进行模型选择和调参。
- 测试集(Test Set):
- 作用:主要用于检验最终选择的最优模型的性能,主要是测试训练好的模型的分辨能力(识别率等)和泛化能力。
- 测试集是一个完全独立的数据集,用于在模型训练完成后评估其在实际数据上的性能。
这三类数据集的划分有助于我们在训练过程中评估模型的性能,避免过拟合和欠拟合,并最终选择出最优的模型。在划分数据集时,常见的划分方式包括顺序划分、随机划分和交叉验证等。
二、神经网络
深度学习中的神经网络,特别是深度神经网络(Deep Neural Networks, DNNs),是机器学习领域中一种重要的技术。它们是由多层神经元组成的人工神经网络,旨在模仿人脑神经元网络的结构和工作原理。深度学习中的神经网络是一种强大的计算模型,它们通过多层次的神经元连接和复杂的特征表示来实现对复杂数据的高效处理和分析。

- 输入层(Input Layer):
- 神经网络的第一层,负责接收原始输入数据。
- 输入层中的每个节点(或神经元)对应输入数据的一个特征。
- 隐藏层(Hidden Layers):
- 介于输入层和输出层之间的层,可以是多层。
- 隐藏层中的每个节点都接收来自前一层节点的输出,并产生自己的输出,这些输出会传递给下一层。
- 隐藏层负责学习输入数据的特征表示,并将这些表示传递给输出层。
- 输出层(Output Layer):
- 神经网络的最后一层,负责产生预测或分类结果。
- 输出层中的节点数量取决于任务类型。
其中隐藏层就是主要负责学习规则部分,隐藏层中每一层网络都可以看做成一个函数,如上图可以分别看做由,
,
,
组成。
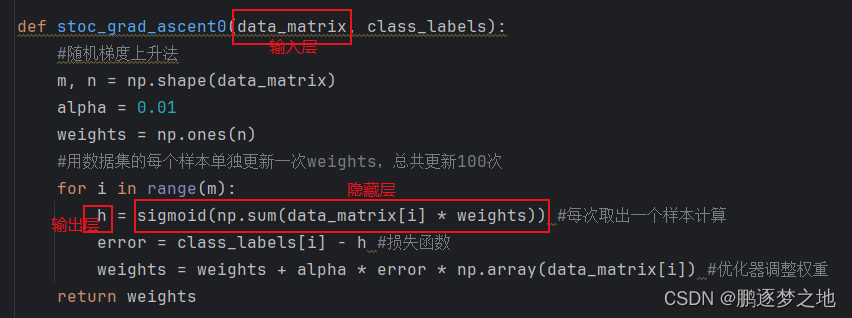
三、损失函数与优化器

损失函数是用于衡量模型预测值与真实值之间的差异程度的函数。在机器学习和深度学习中,损失函数通常用于评估模型的性能并指导模型的训练。损失函数越小,表示模型的预测值越接近真实值,模型的性能就越好。
优化器是用于调整模型参数以最小化损失函数的算法。在深度学习中,优化器通过计算损失函数关于模型参数的梯度,并根据梯度的方向和大小来更新模型参数。优化器的目标是使模型能够更好地拟合训练数据,并提高模型的泛化能力。
损失函数和优化器在模型训练过程中是紧密相连的。损失函数定义了模型预测值与真实值之间的差异程度,而优化器则根据损失函数的梯度信息来更新模型参数,以最小化损失函数。
在训练过程中,优化器会不断地迭代计算损失函数关于模型参数的梯度,并根据梯度的方向和大小来更新模型参数。通过不断地迭代和优化,模型参数会逐渐收敛到最优解附近,从而使模型的预测值更加接近真实值。
因此,选择合适的损失函数和优化器对于提高模型的性能和泛化能力至关重要。在实际应用中,需要根据具体的问题和任务类型来选择合适的损失函数和优化器,并进行充分的实验和验证。
















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









