






如果服务器或者本地可以直接挂vpn,那用Huggingface官方提供的代码即可。但是我想大多数人应该会碰上和我一样的问题,有时候服务器压根就挂不了vpn,甚至很多时候连网络都无法连接,这中情况下还要处理Huggingface上的那些dataset简直强人所难。本文通过统一处理下载的Huggingface文件来重新整理成符合我们自己要求的dataset文件。(全文以MagicBrush数据集为例,更换数据集按流程改个名字即可)
从Huggingface下载数据集
首先需要找到一台可以访问网络的服务器(或者本地电脑),通过Huggingface下载我们想要的数据集。假设此时我们需要下载MagicBrush这个数据集,我们首先上Huggingface或者镜像网站或者以其他方式(比如百度)找到我们想要数据集在Huggingface上对应的名称,例如(对应链接:https://huggingface.co/datasets/osunlp/MagicBrush/tree/main/data):
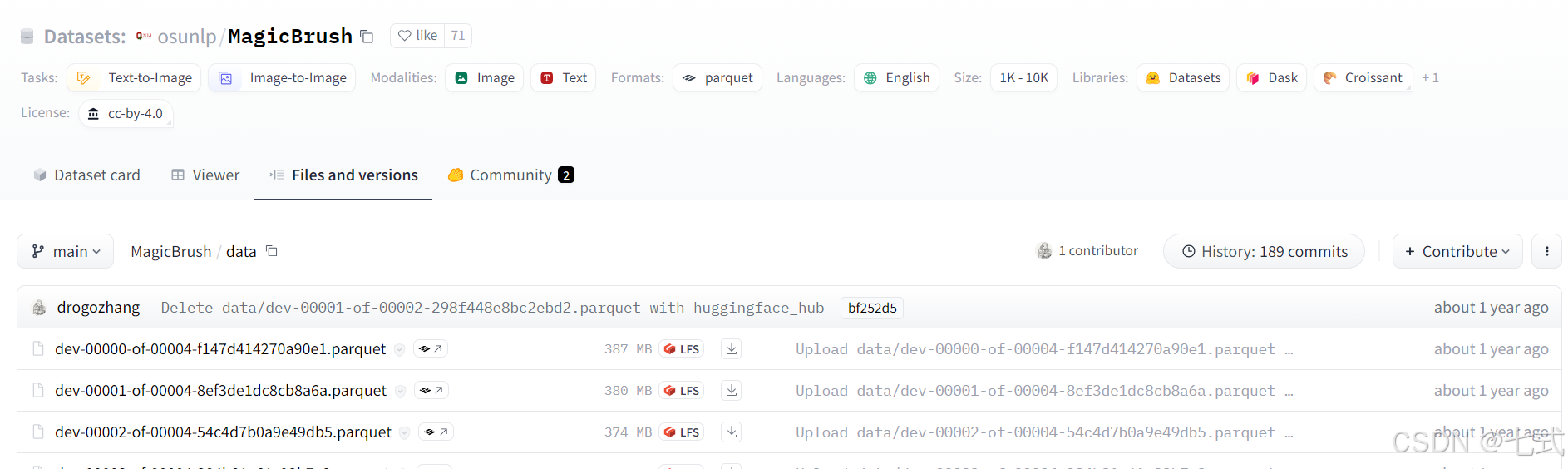
其对应的名称就是“osunlp/MagicBrush”,最直接的方式是,可以在网页上一个个点击下载,当然,也可以用以下脚本来下载:
import os
from huggingface_hub import HfApi, HfFolder
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" #国内镜像,无需连vpn就能下
#token = "*********" #只有需要验证账户才能下载的数据集/模型时才需要设置,token查看方法百度即可,很简单
#HfFolder.save_token(token)
from huggingface_hub import snapshot_download
from huggingface_hub import hf_hub_download
snapshot_download(repo_id="osunlp/MagicBrush", repo_type="dataset",
cache_dir='./Dataset',
local_dir_use_symlinks=False, resume_download=True)
snapshot_download的4个参数如下:
- repo_type:指定了你要下载的快照的类型。Hugging Face Hub 支持不同类型的资源,例如模型(model)、数据集(dataset)、库(library)等。
- cache_dir 指定了下载的文件应该缓存到哪个目录。如果你想将文件下载到特定的目录,可以使用此参数。
- local_dir_use_symlinks 决定是否使用符号链接(symlinks)来管理下载的文件。这对节省磁盘空间和管理文件更新很有帮助,但并非所有文件系统都支持符号链接。
- resume_download 用于指示是否从上次中断的地方恢复下载。如果下载过程中出现中断或错误,启用此选项将使下载从上次停止的位置继续。
如果你通过脚本下载,那么你得到的结构会如下:
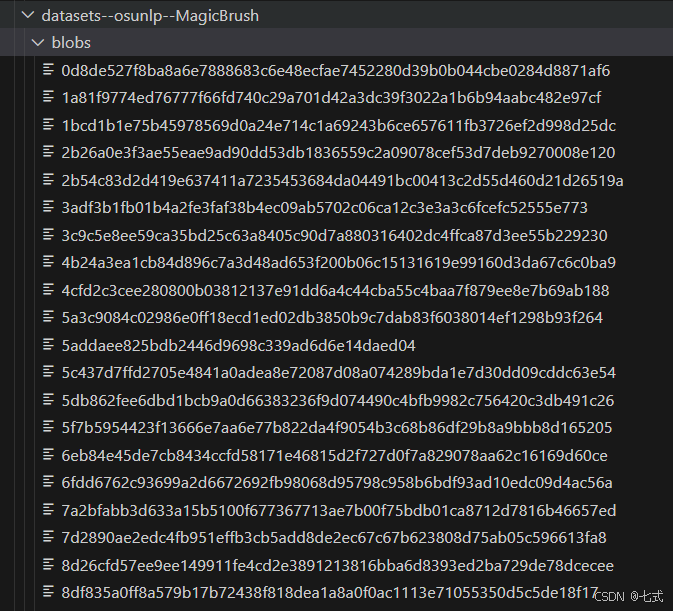
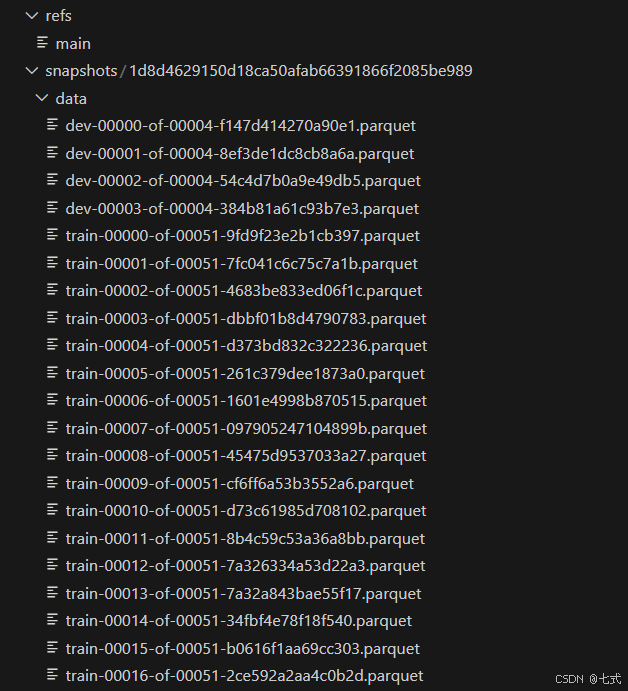
说明一下这3个目录: 在 Hugging Face 上下载的数据集文件夹通常包含 blobs、refs 和 snapshots 等目录,这些文件夹是 datasets 库使用 Git LFS(Large File Storage)进行管理的。这些目录有特定的用途,用于存储数据集的不同版本和快照。
- blobs: 存储大文件的实际数据。这些文件通常会以哈希值作为文件名。例如,文件名可能类似于d2a26b226b0916e5f4cf79f16d5b3a5a3e4e3e3e。这些哈希值是文件在 Git LFS 中的标识符。
- refs: 存储对这些大文件的引用.
- snapshots: 存储数据集的快照或版本信息。
实际上,我们只需要处理snapshots下data中的.parquet文件即可
处理.parquet文件获取数据集
如果你很熟悉通过git lfs管理文件,到此我想你已经可以自己处理了。当然也会存在一些特殊的情况:比如我下载这些数据集只是希望作为已有数据集的补充。此时,可能更希望把这些parquet文件转变为最简单的数据格式以方便与其他文件进行统一的后续操作。
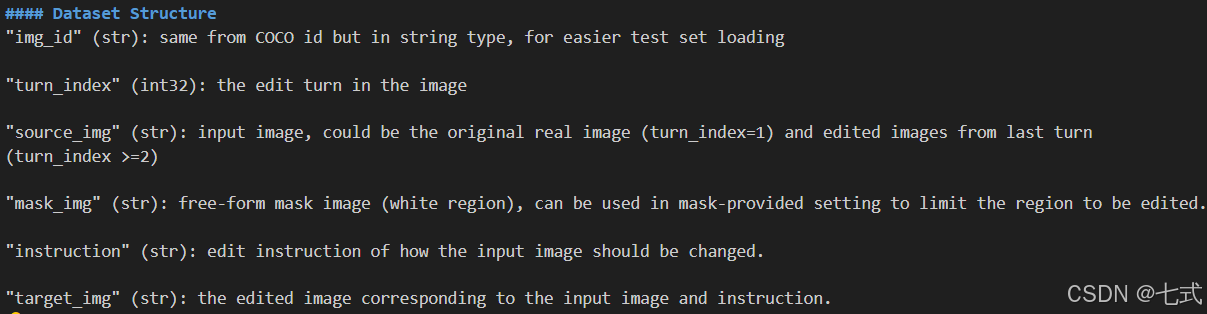
首先我们需要通过readme文件来确定一下文件的结构:
当然,不放心的话,也可以通过pandas读取.parquet文件进一步确认:
import pandas as pd
_file = pd.read_parquet('./datasets--osunlp--MagicBrush/snapshots/1d8d4629150d18ca50afab663918
66f2085be989/data/train-00000-of-00051-9fd9f23e2b1cb397.parquet')#修改为你自己的路径
print(_file.head())
##输出如下
# img_id turn_index ... instruction target_img
#0 327726 1 ... change the table for a dog {'bytes': b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHD...
#1 435242 1 ... leave only words on the page {'bytes': b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHD...
#2 435242 2 ... leave words only on half the page {'bytes': b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHD...
#3 513551 1 ... leave only the scissor on the cup {'bytes': b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHD...
#4 138270 1 ... the window is now square {'bytes': b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHD...
#[5 rows x 6 columns]
print(_file.keys())
#输出如下
#Index(['img_id', 'turn_index', 'source_img', 'mask_img', 'instruction',
# 'target_img'],
# dtype='object')
此时可以确认:image_id, turn_index和instruction都没有子结构了,接下来观察一下source_img, mask_img和target_img:
print(_file['source_img'][0].keys())
print(_file['mask_img'][0].keys())
print(_file['target_img'][0].keys())
##输出均为:dict_keys(['bytes', 'path'])
那么:bytes即为存储的图片,path经过确认为图片名(格式:{img_id}-{input/mask/output}{turn_index}.png)
通过如下代码我们保存第一组数据进行查看:
import pandas as pd
import cv2
import numpy as np
#更换为自己的路径
_file = pd.read_parquet('./datasets--osunlp--MagicBrush/snapshots/1d8d4629150d18ca50afab66391866f2085be989/data/train-00000-of-00051-9fd9f23e2b1cb397.parquet')
source_img_bytes = _file['source_img'][0]['bytes']
mask_img_bytes = _file['mask_img'][0]['bytes']
target_img_bytes = _file['target_img'][0]['bytes']
source_img_np = cv2.imdecode(np.frombuffer(source_img_bytes, dtype=np.uint8), cv2.IMREAD_COLOR)
mask_img_np = cv2.imdecode(np.frombuffer(mask_img_bytes, dtype=np.uint8), cv2.IMREAD_COLOR)
target_img_np = cv2.imdecode(np.frombuffer(target_img_bytes, dtype=np.uint8), cv2.IMREAD_COLOR)
cv2.imwrite(_file['source_img'][0]['path'], source_img_np) #327726-input.png
cv2.imwrite(_file['mask_img'][0]['path'], mask_img_np) #327726-mask1.png
cv2.imwrite(_file['target_img'][0]['path'], target_img_np) #327726-output1.png



我们在上面已经看到了,其对应的text为“change the table for a dog”,很显然是正确的。
而后,只需要批量处理这些.parquet文件保存至本地即可。批量的代码就按自己的需求去写就行。


















 6061
6061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









